- The paper quantifies loop vectorization rates and challenges across compilers (GCC, Clang, ICX, ACFL) on x86 and ARM platforms.
- It shows that vectorization success varies drastically by code pattern, with fewer than one‐third of loops common to all compilers.
- The study reveals inconsistent performance gains from vectorization, urging explicit benchmarking and manual review for mission-critical HPC code.
Comparative Evaluation of Compiler Vectorization on X86 and ARM Architectures
Abstract
This essay provides an in-depth analysis and synthesis of the paper "Comparison of Vectorization Capabilities of Different Compilers for X86 and ARM CPUs" (2502.11906). The study systematically benchmarks GCC, Clang, Intel's ICX, and ARM's ACFL using a modified TSVC2 loop suite on recent x86 (Intel Xeon(R) Gold 6152) and ARM (A64FX) CPUs, focusing on both the breadth of automatic vectorization and the relative and absolute performance of the resulting machine code. The implications for compiler design, code portability, and high-performance computing are examined.
Experimental Setup
The research uses four modern compilers: GCC 14.1.1, Clang 18.1.8, ICX 2024.0.2, and ACFL 22.2, targeting x86 (with AVX-512) and ARM (with SVE). The TSVC2 suite is adapted for higher realism: all global compile-time information (loop bounds, array sizes) is eliminated, mirroring production HPC settings where arrays are dynamically allocated and loop trips are runtime-dependent. The two hardware platforms, Intel Xeon and Fujitsu A64FX, allow direct comparison of vectorization efficacy and code generation on ISAs with distinct vector unit architectures.
On x86, GCC reports success for 54% of loops, ICX for 50%, and Clang for 46%. On ARM, the numbers rise slightly: GCC at 56%, ACFL at 54%, and Clang at 47%. Notably, vectorization is far from universal—even on carefully selected benchmarks, a significant fraction of loops are not vectorized by any compiler on either platform. The cross-compiler intersection is limited, with only about one-third of loops vectorized by all compilers and a comparable fraction vectorized by none.
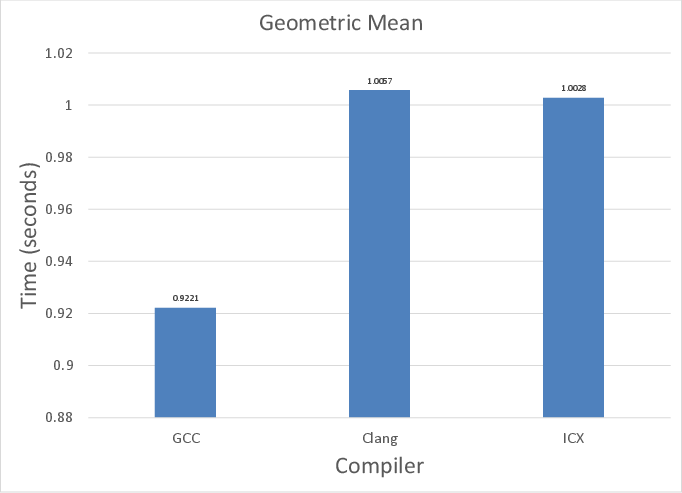
Figure 1: Aggregate geometric mean execution times of all compilers on x86, revealing competitive but not dominating behavior among GCC, Clang, and ICX.
A closer examination reveals that, despite similar overall vectorization rates, compilers often diverge in which loops they handle. Loops with conditional branches, non-unit strides, reverse accesses, reductions, and indirect addressing constitute stress points. Several cases were identified where a compiler vectorized one instance of a pattern but failed on a nearly identical one, pointing to architectural idiosyncrasies in their vectorization analyses.
The performance evaluation demonstrates that vectorization, when reported, does not uniformly translate into superior execution speed. For x86, ICX is fastest on 40% of loops, GCC on 39%, and Clang on 21%. On ARM, Clang leads (65%), followed by GCC (22%) and ACFL (13%). The lack of a single superior compiler is underscored—relative performance varies with both microarchitecture and code pattern.
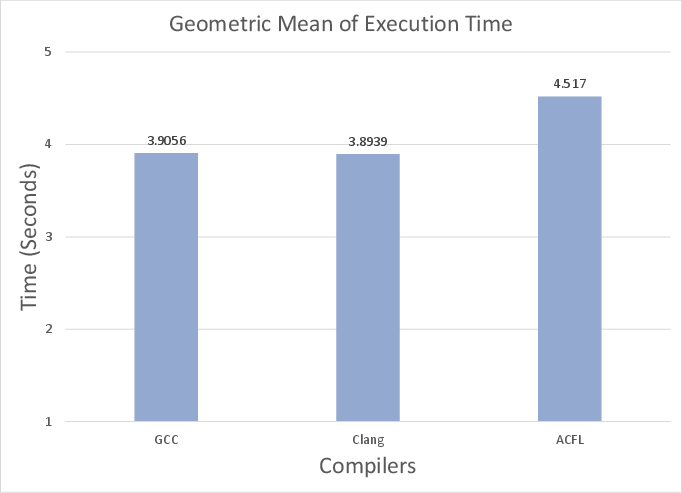
Figure 2: Cross-architecture geometric mean execution times, showing that no compiler consistently outperforms others across platforms.
In the subset of loops vectorized exclusively by one compiler, gains are not universal. There are instances where the vectorized path underperforms unvectorized code due to increased register pressure, suboptimal vector instruction selection, or lack of profit-based heuristics. For example, ICX uniquely vectorizes some indirect-access loops on x86 using gather instructions, but these do not deliver speedup, indicating limitations in both hardware gather implementations and profitability models. On ARM, unrolling in Clang sometimes matches or surpasses the performance of other compilers' vectorized code, suggesting that SVE code generation or auto-vectorization infrastructure remains immature in parts.
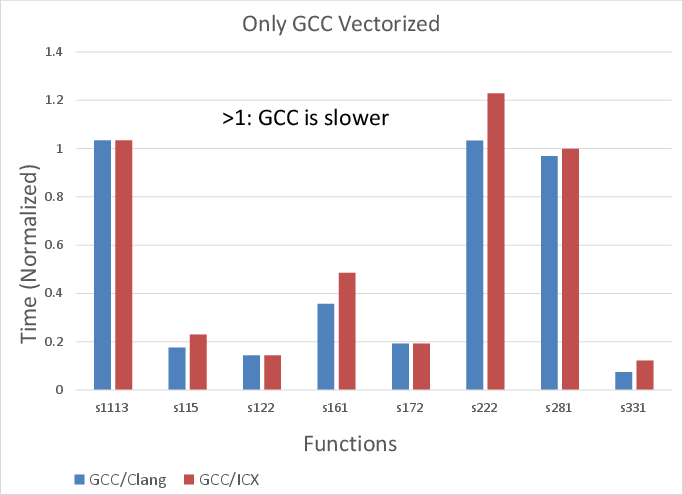
Figure 3: x86 loop execution times where only GCC applies vectorization, illustrating both improved and degraded performance relative to other compilers.
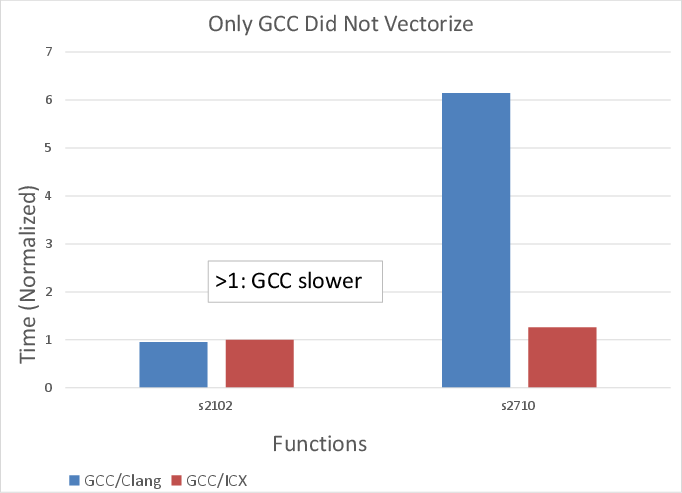
Figure 4: Execution times on x86 for loops vectorized by other compilers but not GCC, exposing cases where vectorization offers marginal or negative benefit.
Vectorized loops involving reductions or complex dependences often see divergent choices: GCC and Clang sometimes attempt partial vectorization, while ICX and ACFL rely on explicit gather/scatter or predicate logic. In some situations, loops are vectorized on x86 but not on ARM or vice versa, suggesting a lack of cross-architecture portability in vectorization analyses despite a uniform source base.
Analysis of Vectorization on Irregular Patterns
A key finding concerns indirect-memory-access (IMA) loops. Across both ISAs, only two of the eight TSVC2 IMA patterns are effectively vectorized by any compiler—by ICX on x86 and GCC/ACFL on ARM. Clang does not utilize relevant gather/scatter hardware support on either platform for these cases. Furthermore, even when gather/scatter instructions are emitted, there is no guarantee of improvement, highlighting the inadequacy of current compilers' profitability and codegen for IMAs and their ongoing challenge in high-performance, memory-bound applications.
Implications for Compiler Development and HPC Portability
The study illustrates that no contemporary compiler demonstrates a clear overall advantage in vectorization ability or resulting performance across both major CPU architectures. The disparities highlight gaps in vectorizer analysis frameworks, especially for non-trivial control flow, reductions, or IMAs, and the absence of fully portable, consistently profitable vectorization strategies across heterogeneous platforms. Proprietary, vendor-tuned compilers (ICX, ACFL) do not universally outperform open-source alternatives.
For end-user HPC developers, these results argue for explicit multi-compiler benchmarking and careful manual review of compiler reports and generated code when performance is mission-critical. For compiler/toolchain researchers, there are evident opportunities for improvement in heuristic design, pattern recognition in loop analyses, and cross-target intermediate representations for robust vectorizability.
Speculation on Future Directions
Automated vectorization for complex control flow, dynamic trip counts, or IMAs remains unsolved. Integrating polyhedral models more deeply into open-source compilers, improving profitability heuristics with hardware performance counter feedback, and using ML-guided vectorization strategies are promising avenues. Evolution on the hardware side (e.g., better gather/scatter throughput) may require further collaboration between architecture and compiler designers. Standardization of vectorization pragmas or annotations could also improve both portability and performance predictability in heterogeneous HPC settings.
Conclusion
A comprehensive, quantitative assessment of four state-of-the-art compilers on contemporary HPC CPUs establishes that automatic vectorization remains incomplete and non-uniform even for well-characterized loop kernels. Vectorization success and realized performance are highly sensitive to loop structure and platform, and even aggressive vendor compilers do not guarantee superior handling. These findings set a clear research agenda for vectorizer improvement, cross-platform portability analysis, and better integration of profitability models within the compiler optimization pipeline (2502.11906).