- The paper establishes a benchmark challenge that leverages advanced generative models to restore high-quality face images from severe degradations.
- The study employs a rigorous evaluation protocol using multiple no-reference IQA metrics and AdaFace embeddings to ensure both perceptual quality and identity fidelity.
- The research highlights multi-stage pipelines that fuse diffusion, transformer, and GAN priors, with dynamic MoE and iterative latent-space optimization to balance restoration fidelity and efficiency.
NTIRE 2025 Challenge on Real-World Face Restoration: Technical Summary and Implications
Introduction and Challenge Overview
The NTIRE 2025 Challenge on Real-World Face Restoration establishes a rigorous benchmark for the restoration of high-quality face images from severely degraded inputs, emphasizing perceptual quality and identity consistency. The challenge is unconstrained in terms of computational resources and training data, allowing participants to leverage state-of-the-art generative models, large-scale datasets, and advanced optimization strategies. Evaluation is performed using a composite score derived from multiple no-reference IQA metrics (CLIPIQA, MANIQA, MUSIQ, Q-Align, NIQE, FID) and identity similarity via AdaFace embeddings, ensuring both subjective and objective fidelity.
Dataset and Evaluation Protocol
The challenge utilizes a diverse set of test images sampled from five datasets: CelebChild-Test, LFW-Test, WIDER-Test, CelebA, and WebPhoto-Test, each presenting unique degradation characteristics (e.g., extreme pose, occlusion, aging, color fading). The FFHQ dataset serves as the primary training corpus, with additional datasets permitted. The evaluation protocol enforces strict identity preservation thresholds and penalizes submissions with excessive identity mismatches, ensuring that perceptual improvements do not come at the expense of semantic fidelity.
Dominant Methodological Trends
Diffusion-Based Generative Priors
Diffusion models have become the de facto standard for high-frequency detail enhancement and realism in face restoration. Most top-performing teams employ two-stage pipelines: initial degradation removal via CNN/Transformer-based restorers, followed by refinement using diffusion-based generative modules (e.g., DiffBIR, SDXL-Turbo). Notably, the IIL team distilled a one-step diffusion model (SDFace) from SDXL-Turbo, achieving competitive perceptual scores with reduced inference latency.
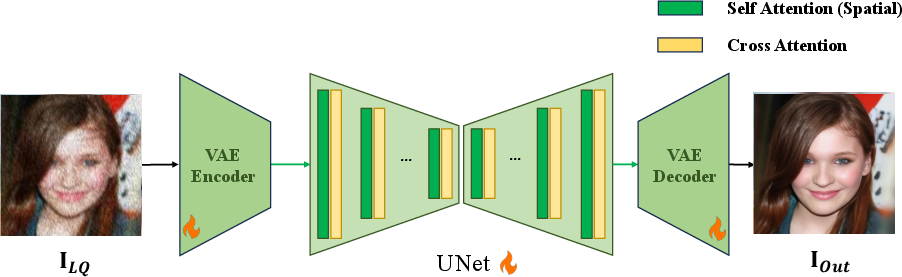
Figure 1: Team IIL's pipeline leverages a distilled one-step diffusion model for efficient face restoration.
Transformer architectures (e.g., CodeFormer, Vision Transformers) are widely adopted for their robust structural guidance, particularly in scenarios with severe degradation. These models facilitate the preservation of facial geometry and identity, often serving as the first stage in multi-stage restoration pipelines.
Fusion of Diverse Generative Priors
Several teams, including the winning AllForFace team, employ progressive fusion of generative priors—combining GANs (StyleGANv2), diffusion models, and VAEs guided by vision foundation models (e.g., Dinov2). This modular approach enables targeted optimization for fidelity, realism, and naturalness across sequential stages.

Figure 2: Team AllForFace's divide-and-conquer pipeline decomposes restoration into fidelity, realness, and naturalness subtasks.
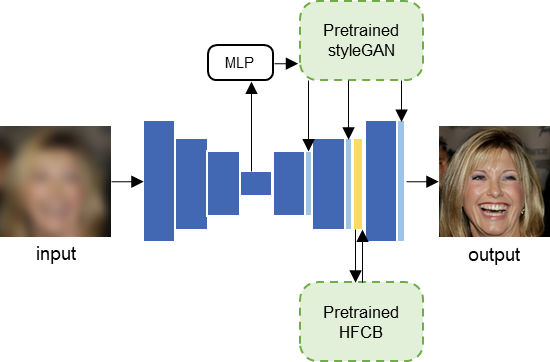
Figure 3: The fidelity module integrates StyleGANv2 and HFCB priors for robust identity preservation.
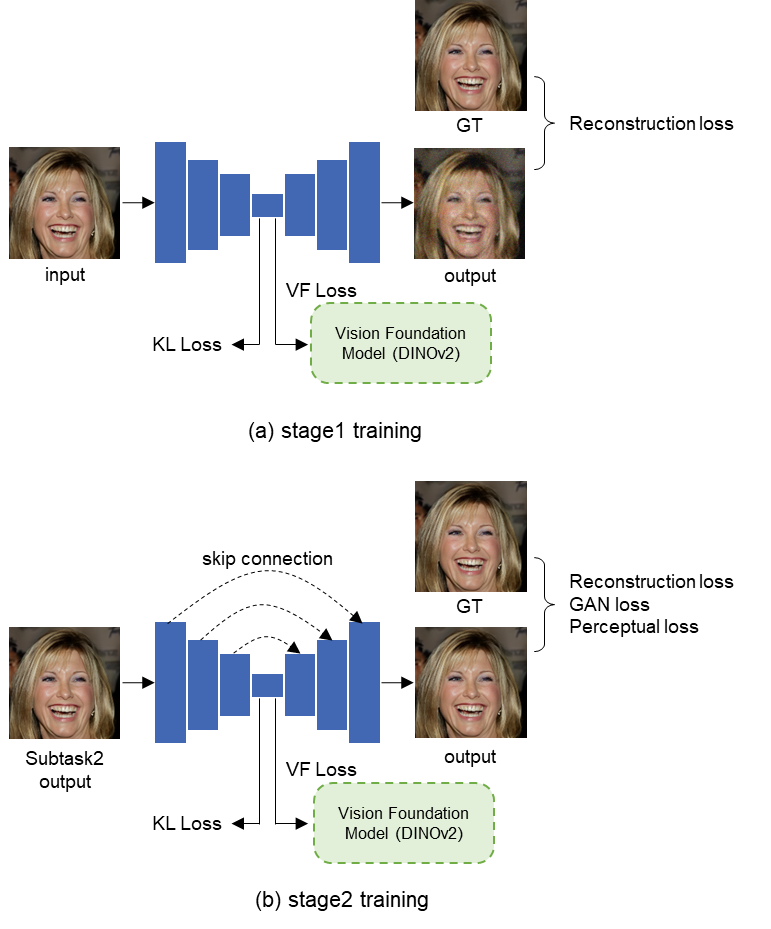
Figure 4: The naturalness module leverages VAE and vision foundation models to align restored images with natural image statistics.
Dynamic Adaptive Weighting and Mixture-of-Experts
Adaptive architectures, such as conditional gating and MoE frameworks, dynamically balance the contributions of different restoration modules based on input degradation severity. This enables flexible control over the trade-off between perceptual quality and identity fidelity.
Iterative Latent-Space Optimization
Instance-wise optimization in the diffusion latent space, guided by multiple NR-IQA metrics, is employed for content-aware refinement. The PISA-MAP team demonstrates that MAP estimation in diffusion latents, with joint guidance from CLIPIQA, MUSIQ, and MS-LIQE, yields significant improvements in subjective quality.
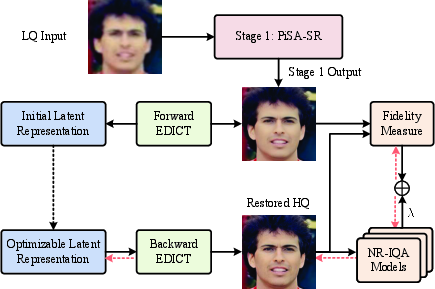
Figure 5: Team PISA-MAP's two-stage pipeline applies MAP optimization in the diffusion latent space for per-image refinement.
Implementation Details and Resource Considerations
Top-performing solutions typically utilize large pre-trained generative models (e.g., SDXL-Turbo, StyleGANv2, Stable Diffusion), often augmented with LoRA adapters for efficient fine-tuning. Training is conducted on high-end GPU clusters (e.g., NVIDIA A6000), with inference times ranging from 0.2s to several seconds per image depending on pipeline complexity. The use of instance-wise optimization and multi-stage architectures increases computational overhead but is justified by substantial gains in perceptual metrics.
Quantitative Results and Analysis
The AllForFace team achieved the highest overall score (4.36), with only one failed identity case, demonstrating the efficacy of their three-stage pipeline. The IIL and PISA-MAP teams closely followed, with scores of 4.35 and 4.27, respectively. Notably, teams that failed the AdaFace ID test were excluded from the final ranking, underscoring the importance of identity preservation in practical restoration scenarios.
Practical and Theoretical Implications
The challenge results indicate that diffusion-based generative priors, when combined with transformer-based structural guidance and adaptive fusion strategies, set the new state-of-the-art for real-world face restoration. The modular decomposition of restoration objectives (fidelity, realism, naturalness) enables targeted optimization and improved generalization across diverse degradation types. The integration of vision foundation models (e.g., Dinov2) into VAE-guided reconstruction represents a promising direction for aligning generative outputs with natural image statistics.
From a theoretical perspective, the success of instance-wise latent-space optimization and dynamic MoE architectures suggests that future research should focus on content-adaptive restoration strategies and efficient model distillation. The challenge also highlights the limitations of single-model approaches in handling the full spectrum of real-world degradations, advocating for multi-stage, multi-prior pipelines.
Future Directions
Potential avenues for advancement include:
- Unified Multi-Prior Architectures: Developing end-to-end frameworks that seamlessly integrate GAN, diffusion, and transformer priors with adaptive weighting.
- Efficient Instance-Wise Optimization: Reducing the computational cost of per-image latent-space refinement via meta-learning or lightweight surrogate models.
- Domain Generalization: Extending restoration pipelines to handle non-face domains and cross-modal degradations.
- Human-in-the-Loop Evaluation: Incorporating subjective human feedback into the training and evaluation loop for improved perceptual alignment.
Conclusion
The NTIRE 2025 Challenge on Real-World Face Restoration has catalyzed significant progress in generative restoration methodologies, establishing diffusion-based and transformer-based priors as the dominant paradigms. The modular, multi-stage pipelines and adaptive optimization strategies demonstrated by top teams provide a robust blueprint for future research and deployment in real-world applications. The challenge underscores the necessity of balancing perceptual quality with identity fidelity and sets a high bar for subsequent developments in face restoration and related generative tasks.