- The paper presents MCBR-RAG, a framework that transforms multimodal data into text and improves case retrieval in CBR applications.
- It employs CNNs for text generation and FFNNs for latent representation, achieving notable precision improvements in the Math-24 application.
- Applications in Math-24 puzzles and Backgammon demonstrate the framework’s ability to enhance LLM-generated solutions via enriched contextual queries.
A General Retrieval-Augmented Generation Framework for Multimodal Case-Based Reasoning Applications
Introduction to MCBR-RAG
The paper introduces MCBR-RAG, a framework crafted to enhance multimodal Case-Based Reasoning (CBR) applications using Retrieval-Augmented Generation (RAG). Traditional CBR methodologies leverage a repository of solved cases to address new, similar problems through a pipeline of Retrieve, Reuse, Revise, and Retain. While RAG has shown promise in supporting text-based CBR Retrieve and Reuse stages, this framework extends its utility to non-textual data by converting multimodal elements into text-based representations. The aim is to improve LLM inference capabilities by providing enriched contextual information during the generation process.
Methodology of MCBR-RAG
The MCBR-RAG framework operates in multimodal domains by processing non-text components via two pivotal functions: text generation and latent representation.
- Text Generation: Converts non-textual case components into text, leveraging models such as CNNs to predict text from images.
- Latent Representation: Employs models to produce latent embeddings from text-based representations, facilitating similarity calculations for retrieval.
The Retrieve phase exploits these latent representations to compute similarity, enhancing the identification of relevant past cases. The Reuse phase utilizes the text generation output for context augmentation in LLM queries, improving solution generation for new cases.
Applications in Math-24 and Backgammon
Math-24 Application
In the Math-24 application, the framework is examined using a simplified version of the Math-24 game. Here, an image of a puzzle card becomes the problem component, processed through a CNN for text generation to predict the numbers on the card:

Figure 1: CNN for learning text generation in Math-24. Once the model is trained, the predictions can be used to generate a text-based representation of a Math-24 card image i.e. `4 5 9 10' for the image in this figure.
The latent representation, achieved through an FFNN, aids in the retrieval of similar puzzles:
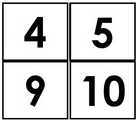
Figure 2: FFNN for learning latent representations in Math-24.
Backgammon Application
The Backgammon application extends this framework's capabilities to more complex, real-world scenarios involving board games. The task involves predicting landmark positions on a board to divide it into points, each processed to predict checkers' positions. A multi-task FFNN is employed for learning latent representations, enhanced by strategic analysis metrics:
(Figure 3)
Figure 3: CNN for learning text generation in Backgammon. Once the models are trained, the predictions can be used to generate a text-based representation of a Backgammon board image.
Experimental Validation
Math-24 Results: Experimental results demonstrated that MCBR-RAG could effectively increase the accuracy of LLM-generated solutions by a significant margin through context-based queries versus baseline models without context. Notably, the use of latent representations provided superior retrieval performance (e.g., 64.2% precision with SCD labeling).
Backgammon Results: In Backgammon, the framework also improved semantic quality as evidenced by enhanced similarity metrics across various context-intensive and context-free analyses. The incorporation of chapter-grouped contexts further emphasized retrieval quality improvements.
MCBR-RAG offers a robust, scalable solution for multimodal CBR applications. Its utility across tasks like Math-24 puzzles and Backgammon board analysis showcases its potential for diverse modalities. Future implementations can benefit from enhancing downstream LLM performance by tailoring framework components (i.e., text generation and latent representations) to fit complex, domain-specific challenges. This work paves the way for enriched automated reasoning capabilities, setting a precedent for future multimodal integrations in CBR systems.