- The paper introduces A3, a novel platform that evaluates mobile GUI agents using dynamic tasks and automated LLM-based assessments.
- It details a comprehensive architecture with controllers, translators, and evaluators to simulate realistic mobile app interactions.
- Experiments reveal that traditional static evaluations fall short, highlighting challenges in action coordination and error correction in dynamic scenarios.
Overview of "A3: Android Agent Arena for Mobile GUI Agents" (2501.01149)
Android Agent Arena (A3) represents a novel platform aimed at evaluating mobile GUI agents with real-world tasks in natural environments. The platform addresses the shortcomings of existing evaluation systems by incorporating dynamics and further complexity into agent assessment.
Introduction
Recent advancements in LLMs have propelled the development of mobile GUI agents capable of performing tasks autonomously on mobile devices. Traditional assistants like Siri and Bixby fall short in handling complex tasks due to their dependency on APIs. Consequently, GUI agents have been proposed to harness the strengths of MLLMs to function effectively across third-party applications without relying on predefined APIs. Existing datasets for evaluating these agents are primarily static and lack the capability to test dynamic interactions, thus A3 was developed.
A3 System Architecture
A3 is designed to act as an intermediary between the GUI agent and its environment (Figure 1). It comprises a controller to maintain device state, a translator to convert agent predictions into commands, and an evaluator for performance assessment. The architecture supports integration with widely-used third-party applications, allowing for expansive and varied task scenarios, which better reflect realistic operating conditions.
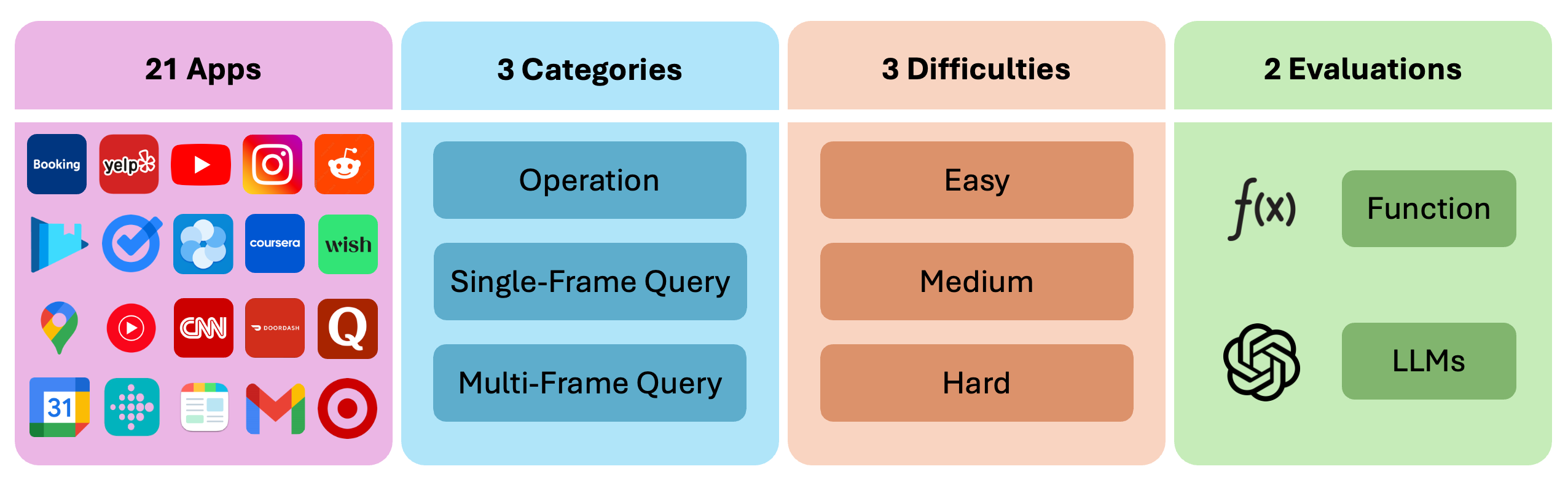
Figure 1: Overview of Android Agent Arena. A3 contains over 200 tasks from 21 widely used apps. Tasks are categorized into operation, single-frame query, and multi-frame query based on the task goal.
Action Space and Task Distribution
A3 expands the action space beyond existing frameworks to include comprehensive interaction possibilities, thereby accommodating diverse agent training methodologies. This includes the addition of novel actions to address the limitations of current platforms.
Tasks within A3 are meticulously organized into operation, single-frame query, and multi-frame query categories (Figure 2). This categorization allows for nuanced evaluation based on task complexity and required interactions, which test an agent’s ability to adapt dynamically.
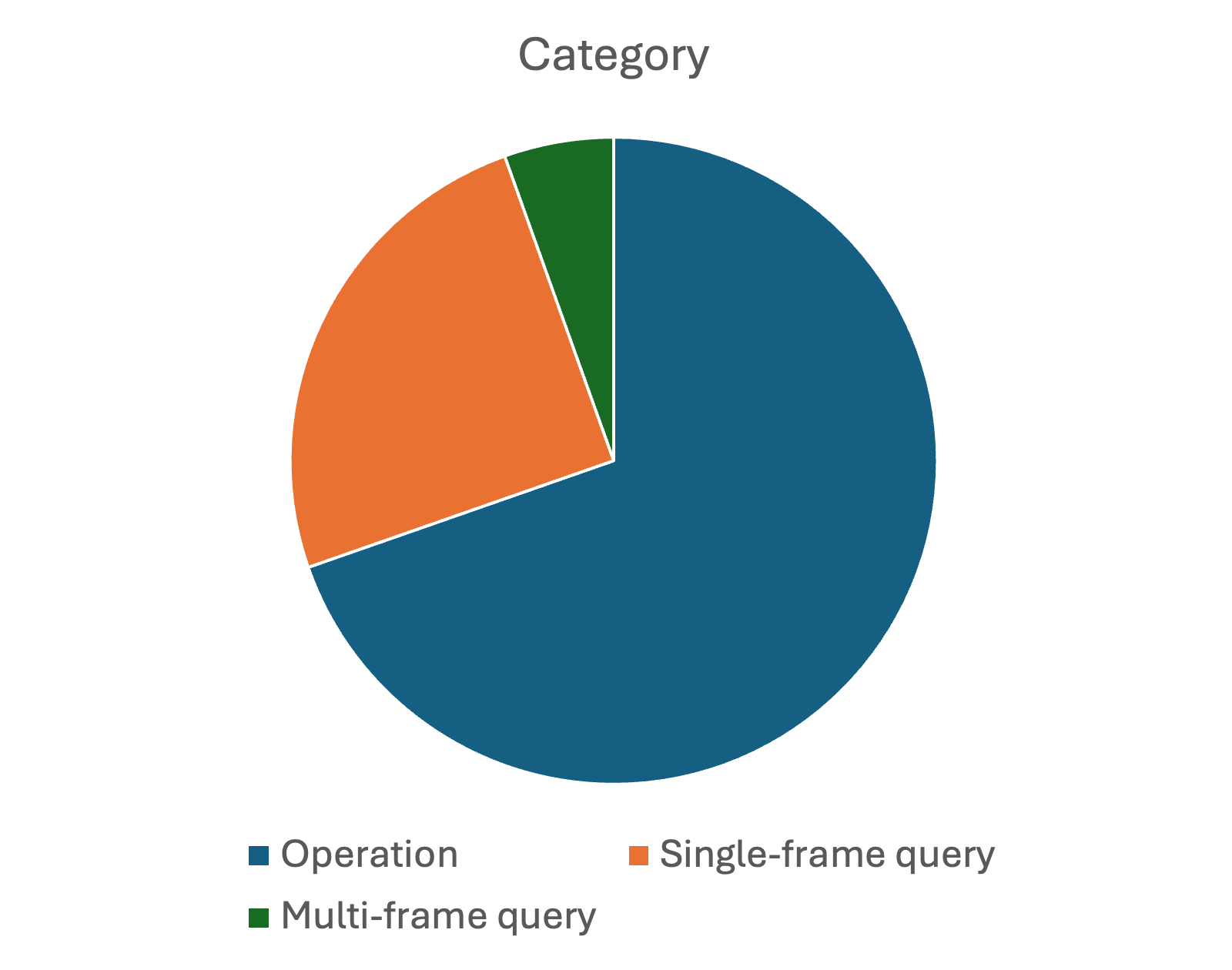
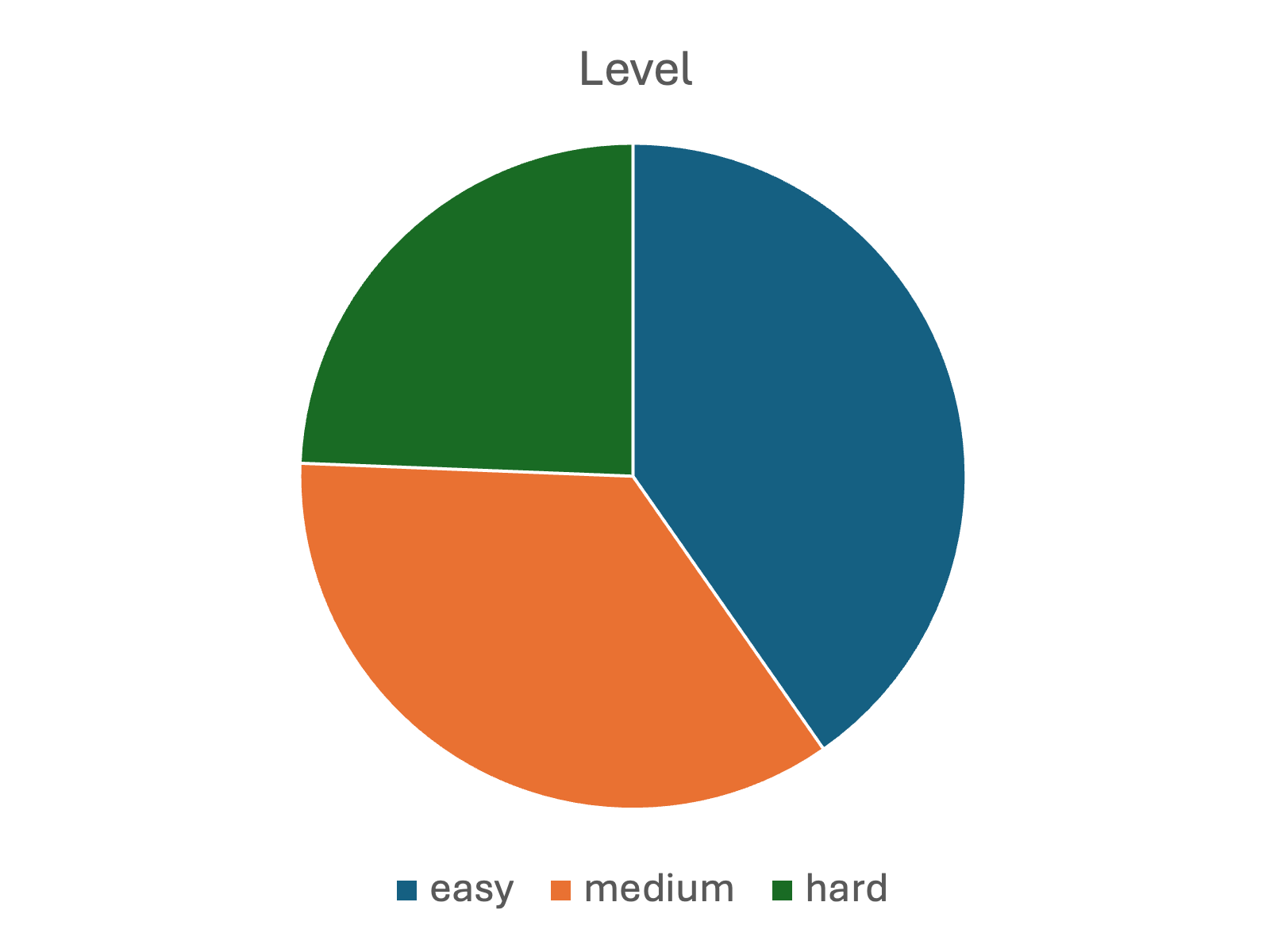
Figure 2: Distribution of tasks in A3. The above subfigure is the distribution by categories and the bottom subfigure is the distribution by difficulty levels.
Evaluation Strategies
A3 employs two distinct evaluation methodologies:
- Task-Specific Evaluation Functions: Custom evaluation functions parse XML trees and leverage action or element matching to determine task completion.
- LLM Evaluation System: Business-level LLMs such as GPT and Gemini automate evaluation, significantly reducing manual involvement and coding expertise. Coding by GPT-4o demonstrated promising reductions in workload with high correctness, though human oversight might still be necessary for edge cases.
The introduction of an automated LLM-based evaluation aspires to alleviate bottlenecks related to human labor in evaluation task creation.
Experiments and Findings
Experiments reveal that agents fine-tuned on existing datasets perform well on static evaluations but are challenged in dynamic, real-world scenarios (Tables 1 and 2). Primary issues included dependency on action history and the agent's incapacity for self-correction following errors.
Business-level LLMs could partially address these challenges, though they struggled with the full action spectrum. Enhancements through planning capabilities, as seen in AppAgent, yielded superior performance.
Common Error Cases
Several recurrent errors include:
- Incorrect action coordination, resulting in misclicks.
- Performing invalid actions when appropriate cues are absent.
- Actions triggered without selecting the intended elements.
- Inability to terminate actions upon task completion.
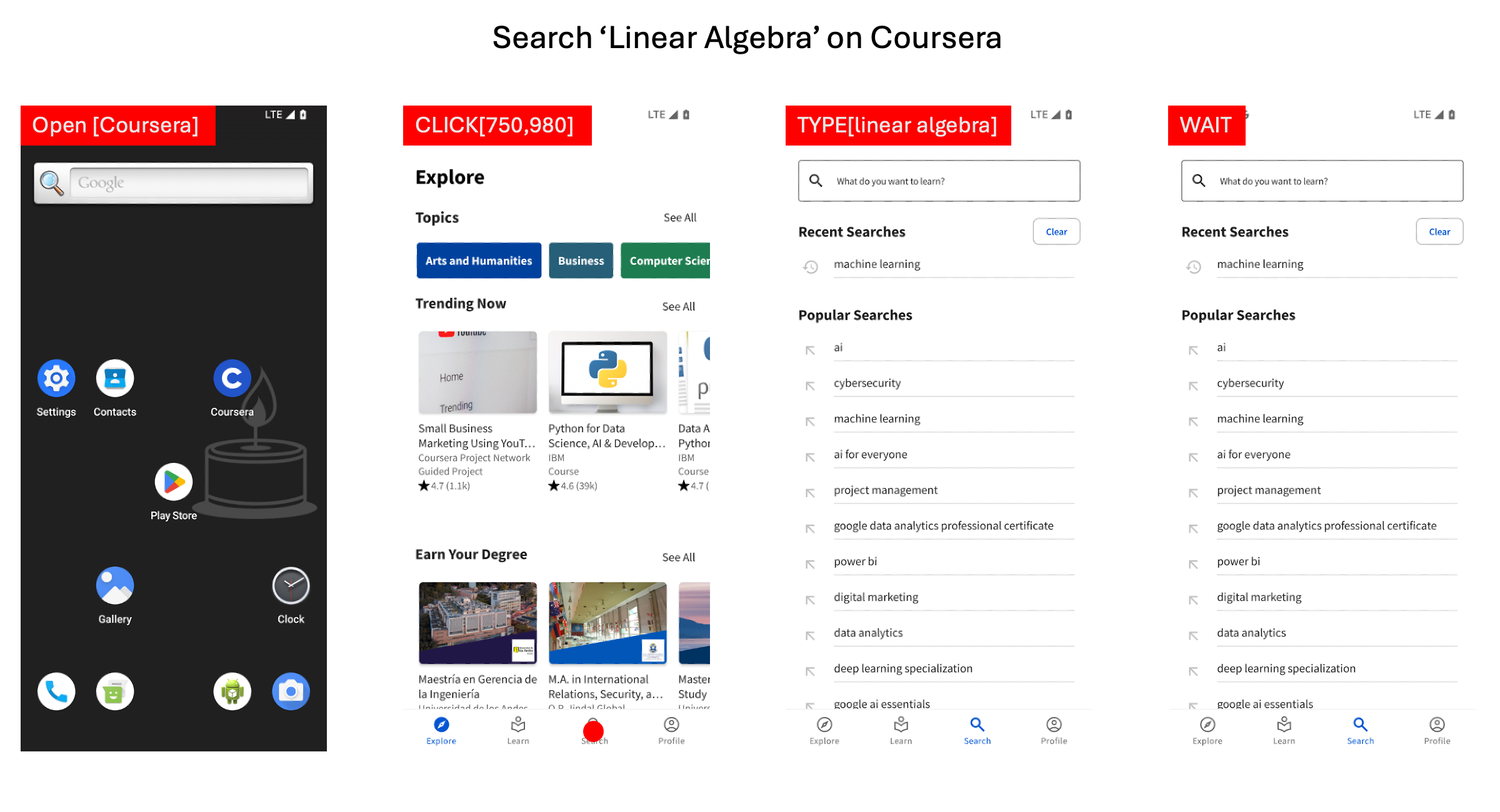
Figure 3: Step 1 and Step 2 are correct, however, the agent starts typing before the search bar is clicked or selected, so the process sticks at this situation and the agent keeps typing and waiting.

Figure 4: Step 1 and Step 2 are correct, however, the agent predicts a wrong click coordinate and accidentally goes to the shopping cart. It should go back but cannot, indicating a lack of capability, and gets stuck in the shopping cart.
Limitations
The primary constraints include version-specific task evaluations and inadequacies in assessing sub-goal performances. Future efforts should refine LLM evaluations to obviate these limitations and enhance the reflective accuracy of agent capabilities in real-world scenarios.
Conclusion
A3 offers a comprehensive and extensible evaluation platform for GUI agents. By extending the task and evaluation spectrum beyond static assessments, A3 paves the way for adaptable, effective agent designs incorporating current AI advancements. Future improvements may focus on diversifying task scenarios and enhancing evaluation precision through further LLM development.

