Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks
Abstract: Modern AI agents, driven by advances in large foundation models, promise to enhance our productivity and transform our lives by augmenting our knowledge and capabilities. To achieve this vision, AI agents must effectively plan, perform multi-step reasoning and actions, respond to novel observations, and recover from errors, to successfully complete complex tasks across a wide range of scenarios. In this work, we introduce Magentic-One, a high-performing open-source agentic system for solving such tasks. Magentic-One uses a multi-agent architecture where a lead agent, the Orchestrator, plans, tracks progress, and re-plans to recover from errors. Throughout task execution, the Orchestrator directs other specialized agents to perform tasks as needed, such as operating a web browser, navigating local files, or writing and executing Python code. We show that Magentic-One achieves statistically competitive performance to the state-of-the-art on three diverse and challenging agentic benchmarks: GAIA, AssistantBench, and WebArena. Magentic-One achieves these results without modification to core agent capabilities or to how they collaborate, demonstrating progress towards generalist agentic systems. Moreover, Magentic-One's modular design allows agents to be added or removed from the team without additional prompt tuning or training, easing development and making it extensible to future scenarios. We provide an open-source implementation of Magentic-One, and we include AutoGenBench, a standalone tool for agentic evaluation. AutoGenBench provides built-in controls for repetition and isolation to run agentic benchmarks in a rigorous and contained manner -- which is important when agents' actions have side-effects. Magentic-One, AutoGenBench and detailed empirical performance evaluations of Magentic-One, including ablations and error analysis are available at https://aka.ms/magentic-one
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Glossary
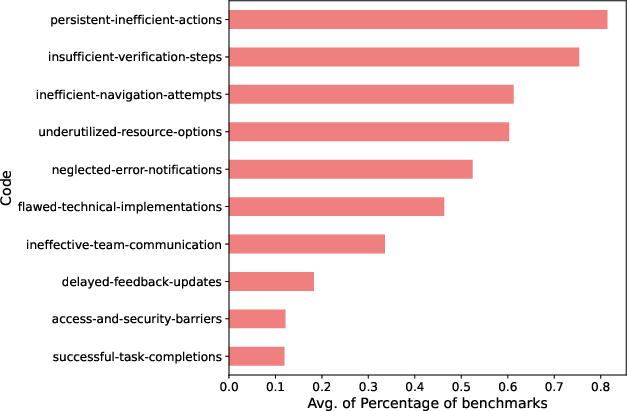
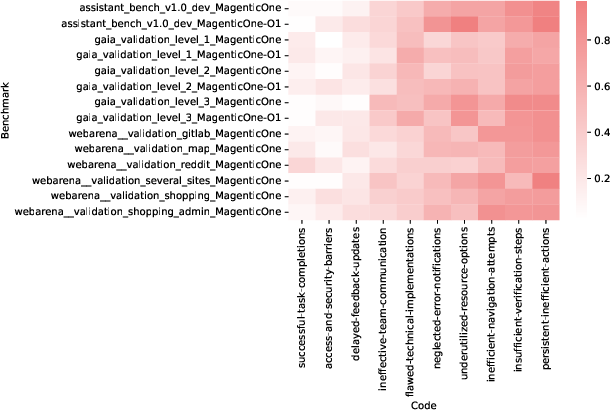
- Ablation experiments: Controlled removal or modification of components to measure their contribution to overall performance. "Follow-up ablation experiments and in-depth error analyses reveal the additive value of each agent to Magentic-One's performance, and highlight opportunities for further improvement."
- Action space: The set of permissible actions an agent can take in its environment. "With each incoming natural-language request, the WebSurfer maps the request to a single action in its action space (described below), then reports on the new state of the web page (providing both a screenshot and a written description)."
- Agentic systems: AI systems that can perceive, reason, and act in an environment to accomplish tasks. "By leveraging the powerful reasoning and generative capabilities of LLMs, agentic systems are already making strides in fields like software engineering"
- AssistantBench: A benchmark of realistic, multi-step web tasks evaluated by exact matching and partial-credit accuracy. "AssistantBench is a set of 214 question--answer pairs that are realistic, time-consuming (requiring a human several minutes to perform), and automatically verifiable."
- AutoGen: A multi-agent framework for building and orchestrating LLM-driven agents. "We implement Magentic-One on the multi-agent platform AutoGen version 0.4 \cite{wu2023autogen}."
- AutoGenBench: A standalone evaluation tool that runs agentic benchmarks under controlled initial conditions. "we introduce AutoGenBench, an extensible standalone tool for running agentic benchmarks."
- Chain of thought prompting: A prompting strategy that elicits step-by-step reasoning to improve problem solving. "similar to chain of thought prompting for the agents \cite{wei2022chain}."
- Chromium-based: Built on the Chromium browser engine. "This is a highly specialized LLM-based agent that is proficient in commanding and managing the state of a Chromium-based web browser."
- Deterministic: Producing the same output given the same input, without randomness. "agents may operate deterministically, and do not include LLMs calls at all."
- Docker containers: Isolated, reproducible environments used to ensure evaluation consistency and safety. "freshly initialized Docker containers, providing the recommended level of consistency and safety."
- Error analysis: Systematic examination of failures to identify causes and opportunities for improvement. "including ablations and error analysis are available at \url{https://aka.ms/magentic-one}."
- Evaluation function: A procedure that determines whether a candidate output satisfies the task requirements. "an evaluation function to compare the desired output to any candidate output."
- Few-shot prompting: Supplying a small number of examples in the prompt to guide model behavior. "few-shot prompting \cite{zhou2024webarenarealisticwebenvironment}."
- FileSurfer: A specialized agent for navigating and reading local files across multiple formats. "The FileSurfer agent is very similar to the WebSurfer, except that it commands a custom markdown-based file preview application rather than a web browser."
- Fine-tuning: Adapting model parameters to new tasks or domains via additional training. "explicit fine-tuning \cite{zeng2023agenttuningenablinggeneralizedagent,pan2024autonomousevaluationrefinementdigital,liu-arxiv2024,putta2024agentqadvancedreasoning}"
- GAIA: A multimodal benchmark of complex, multi-tool tasks with automatically verifiable answers. "GAIA is a benchmark for general AI assistants with 465 multi-modal question--answer pairs that are real-world and challenging, requiring multiple steps and multiple tools to solve (e.g., navigating the web, handling files, etc.)."
- GroupChat: An AutoGen mechanism that routes messages among multiple agents without planning ledgers. "the AutoGen\cite{wu2023autogen} library's GroupChat mechanism."
- Inference-time search: Exploring alternative reasoning paths during inference to improve reliability. "inference-time search \cite{chen2024treesearchusefulllm,yao2023treethoughtsdeliberateproblem,koh2024treesearchlanguagemodel,song2024trialerrorexplorationbasedtrajectory}."
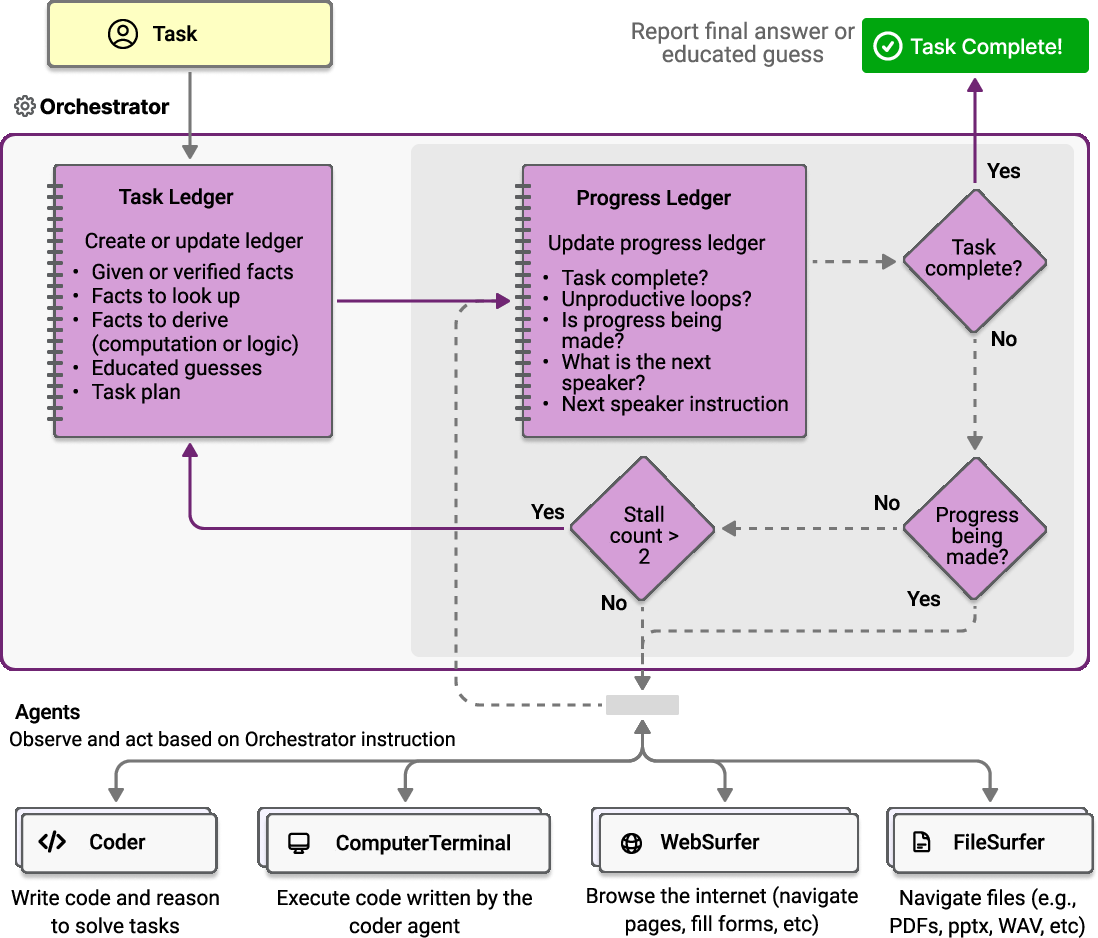
- Inner loop: The iterative cycle that manages step-level progress and agent assignment during execution. "During each iteration of the inner loop, the Orchestrator answers five questions to create the progress ledger:"
- Leaderboard: A public ranking of systems on a benchmark, often based on reported results. "There is a public leaderboard for WebArena, but it is based on self-reported results."
- Ledger: A structured memory artifact that records plans, facts, guesses, and progress throughout a task. "The Orchestrator uses two structured ledgers to achieve this and also to decide which agent should take the next action."
- LLM: LLM; a neural model trained on extensive text to perform language tasks. "LLMs"
- MD5 hash: A deterministic hashing function used for splitting or indexing tasks. "we computed the MD5 hash of each problem's template_id"
- Multimodal: Involving multiple data modalities (e.g., text, images, audio) within a model or system. "For Magentic-One, the default multimodal LLM we use for all agents (except the ComputerTerminal) is gpt-4o-2024-05-13."
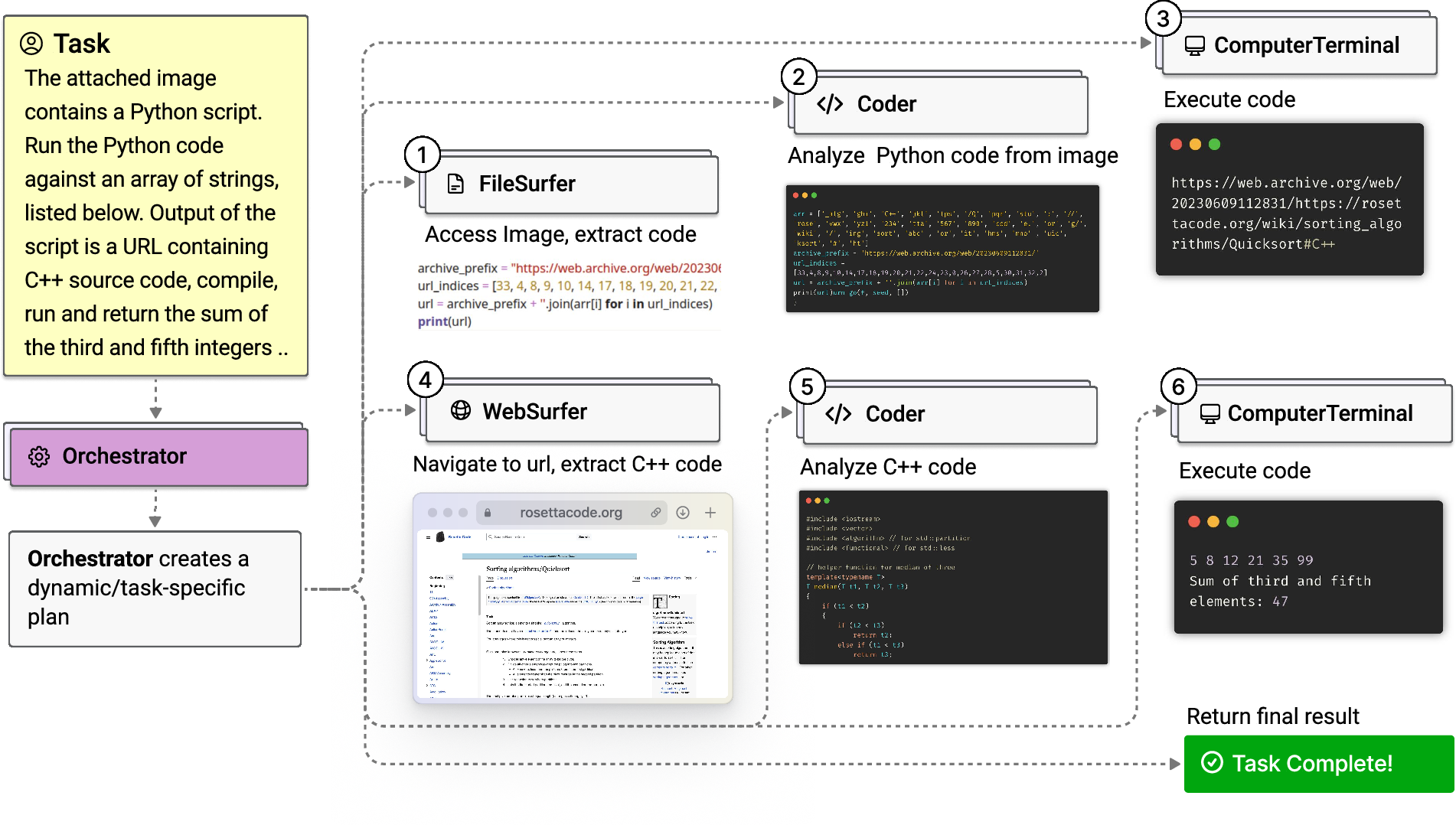
- Multi-agent architecture: A design in which multiple specialized agents collaborate under coordination. "Magentic-One uses a multi-agent architecture where a lead agent, the Orchestrator, plans, tracks progress, and re-plans to recover from errors."
- Orchestrator: The coordinating agent that plans, assigns, tracks, and revises actions across the team. "the Orchestrator creates the task ledger to serve as short-term memory for the duration of the task."
- Outer loop: The high-level cycle that manages the task ledger, planning, and reflection/reset steps. "The outer loop is triggered by an initial prompt or task."
- Partially Observable Markov Decision Process (POMDP): A formal framework for decision making under uncertainty with partial observations. "this setting can be described as a Partially Observable Markov Decision Process, similar to formalizations used by prior work~\cite{sodhi2024stepstackedllmpolicies}."
- Postmill: A forum platform used in WebArena’s synthetic environment, distinct from Reddit’s UI. "Postmill is similar to Reddit, but the UI is distinct, and 'subreddits' begin with /f/ rather than /r/"
- Progress ledger: The memory structure that records current progress, assignments, and step outcomes. "the inner loop maintains the {\em progress ledger}, which directs and evaluates the individual steps that contain instructions to the specialized agents."
- Prompt tuning: Adjusting prompts (without model retraining) to improve system performance or behavior. "without additional prompt tuning or training, easing development and making it extensible to future scenarios."
- ReACT: A prompting technique that interleaves reasoning and acting steps to solve tasks. "ReACT \cite{yao-iclr2023}"
- Set-of-marks prompting: A visual annotation technique for grounding actions on a page via marked regions. "set-of-marks prompting \cite{yang2023set}"
- Side-effects: Unintended changes to the environment resulting from agent actions. "which is important when agents' actions have side-effects."
- SOTA: State-of-the-art; the best known performance at the time of writing. "state-of-the-art (SOTA) systems"
- Stateful environments: Contexts where actions persist and alter subsequent states, affecting evaluation. "Agentic systems, such as Magentic-One, that interact with stateful environments, pose unique challenges for evaluation."
- System prompt: The role-defining instruction given to an LLM to constrain its behavior and capabilities. "constructed around LLMs with custom system prompts, and capability-specific tools or actions."
- Viewport: The currently visible region of a web page within the browser window. "like human users, the WebSurfer agent cannot interact with page elements that are outside the active viewport."
- WebArena: A synthetic, multi-website environment for evaluating complex web navigation tasks. "WebArena, which involves performing complex tasks in a synthetic web environment."
- WebSurfer: A specialized agent that operates a web browser via grounded actions and page understanding. "With each incoming natural-language request, the WebSurfer maps the request to a single action in its action space (described below), then reports on the new state of the web page"
- Wald interval method: A statistical technique for constructing approximate confidence intervals for proportions. "We include 95\% error bars as using the Wald interval method."
- z-test: A hypothesis test used to assess differences in proportions or means assuming known variance. "according to a z-test with "
Collections
Sign up for free to add this paper to one or more collections.