- The paper presents a structured evaluation of LLMs for BPM tasks by analyzing activity recommendation, RPA candidate identification, process question answering, and declarative process model mining.
- It compares both open-source and commercial models using metrics like precision, recall, F1-score, cosine similarity, and ROUGE-L to reveal significant performance variations.
- The study highlights the crucial impact of prompt engineering, showing that tailored prompting strategies improve model outputs in BPM-specific applications.
Benchmarking LLMs for BPM Tasks
The paper presents a structured evaluation of LLMs specifically in the domain of Business Process Management (BPM). Unlike existing NLP benchmarks that focus on generic tasks, this study offers insights into BPM-specific tasks, an area previously lacking a standardized evaluation framework. By examining both open-source and commercial models on four distinct BPM tasks, the paper seeks to understand performance variations related to model size, topology, and licensing.
Introduction
The study recognizes the prevalent deployment of LLMs in organizational contexts for tasks ranging from process analysis to prediction. Given the critical role of BPM in organizational efficiency, the necessity for a tailored benchmark to evaluate and compare LLM suitability for BPM is highlighted. Existing benchmarks, although robust in evaluating general-purpose NLP tasks, do not sufficiently account for the unique characteristics and requirements of BPM applications. This research aims to bridge that gap.
BPM Tasks Analyzed
Activity Recommendation
The task involves predicting subsequent activities in BPM sequences. It is approached as a sequence prediction problem, where historical activity sequences are used to recommend subsequent actions.
Identifying RPA Candidates
Identifies tasks suitable for Robotic Process Automation (RPA) by classifying them into manual, user, or automated categories. This classification helps in pinpointing automation opportunities.
Process Question Answering
Entails understanding textual descriptions of processes and answering related queries. This task emphasizes comprehension and information extraction capabilities of LLMs.
Mining Declarative Process Models
Involves extracting process constraints from textual descriptions to generate flexible, declarative process models. This task tests the ability of LLMs to understand and formalize process rules.
Experimental Setup
Datasets and Models
Three specific datasets were utilized for the BPM tasks, derived from sources like the SAP Signavio Academic Models collection and other documented process descriptions. The models selected for evaluation included both cutting-edge open-source and commercial LLMs, such as GPT-4, Llama 3, and several medium-weight alternatives.
Metrics and Prompting Strategies
Evaluation metrics varied by task but focused on precision, recall, F1-score, cosine similarity, and ROUGE-L for text-based tasks. Prompting strategies involved few-shot examples, persona definitions, and step-by-step instructions to guide the models.
Results
The evaluation revealed diverse performance trends:
- General Model Performance: GPT-4 and Llama3-7b showed superior performance, consistently ranking high across tasks, particularly excelling in process question answering.
- Task-Specific Strengths: Models like Claude2-13b demonstrated particular aptitude for activity recommendation, while Mixtral-8x7b excelled in extracting information for process question answering.
- Effect of Prompting: Performance varied significantly with different prompting strategies, underscoring the importance of prompt design in obtaining reliable outputs.
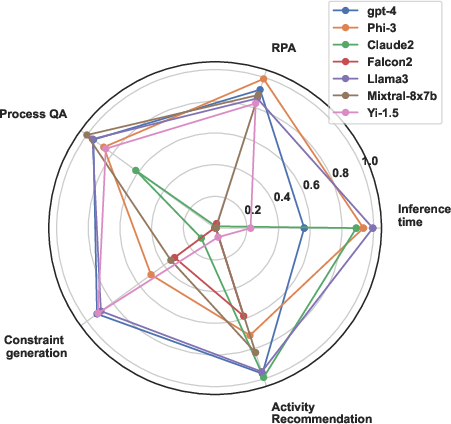
Figure 1: Overview of normalized performance results for each BPM task and inference time (with negative sign applied), where higher values indicate better performance. The results are based on few-shot prompting.
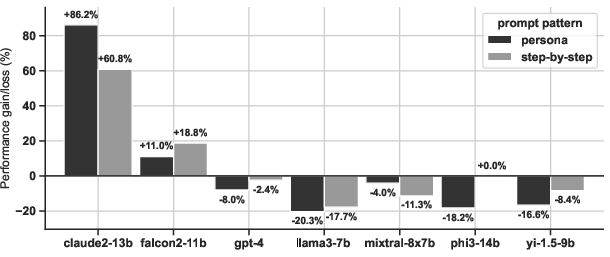
Figure 2: Performance gain/loss by LLMs and prompt pattern (difference from persona baseline).
Implications
The findings have various implications for practice and research. The analysis reveals that while some open-source models compete well with GPT-4 in efficiency and task specialization, model selection should be carefully aligned with specific BPM needs to maximize efficiency and performance. Prompt engineering also emerges as a crucial factor influencing model output quality.
Conclusion
The study provides a foundational benchmark for examining LLMs on BPM tasks. The insights underscore the necessity for domain-specific evaluations, demonstrating that LLM performance in BPM can be highly task-dependent. Future work should focus on expanding this benchmark to include additional tasks and developing more refined models for BPM, alongside refining prompt strategies for maximal performance yield.

