- The paper presents LaSR, a two-stage LLM-guided evolutionary framework that improves symbolic regression by evolving natural language concepts.
- LaSR leverages LLM-based operators within classical genetic programming, achieving a 72/100 exact match on the Feynman Equations dataset.
- The evolving concept library produces interpretable summaries that help rediscover known physical laws and uncover novel scaling equations.
Symbolic Regression with a Learned Concept Library
The paper presents LaSR—a two-stage, LLM‐guided evolutionary framework for symbolic regression that augments classical genetic programming with a learned library of natural language “concepts.” Unlike traditional methods that search blindly through expression spaces, LaSR iteratively extracts, refines, and evolves natural language encapsulations of favorable patterns from high‐performing hypotheses. This additional abstraction layer guides the search toward regions of the solution space that are both interpretable and empirically effective.
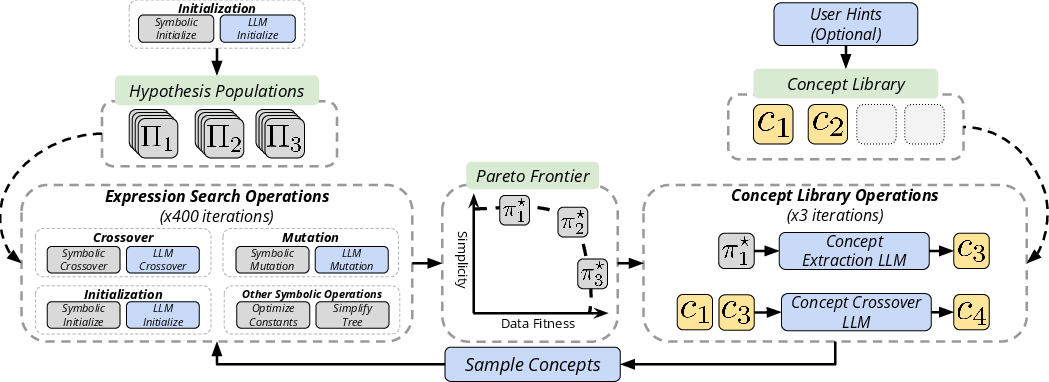
Figure 1: A schematic overview of a single LaSR iteration where multiple hypothesis populations are evolved under concept guidance.
Methodology
LaSR builds upon the PySR algorithm by incorporating LLM‐based operators for initialization, mutation, and crossover. At each iteration, the current hypothesis population is evaluated on a given dataset, and the best–performing expressions are summarized into natural language concepts via zero-shot queries. These concepts, stored in a dynamic library, are then evolved and sampled to inform subsequent rounds of search. The framework leverages prompt designs—for instance, the LlmCrossover prompt (Figure 2) and the LLM Concept Abstraction prompt (Figure 3)—to induce transferable “hints” that bias the search towards physically and mathematically plausible regions of hypothesis space. In later iterations, the system further refines the library via concept evolution (illustrated in Figure 4). The integration of this semantic layer with conventional genetic operations is controlled by a hyperparameter—the percentage of LLM calls—whose setting (e.g. 1%) minimizes disruption to local exploration while still enhancing convergence. Figure 5 details the PySR hyperparameters used consistently across experiments.
Experiments and Results
The approach is evaluated on several benchmarks. On the Feynman Equations dataset—a widely adopted benchmark for scientific discovery—LaSR achieves a 72/100 exact match solve rate, outperforming baselines including PySR (59/100) and other state-of-the-art symbolic regression techniques. The authors report that despite PySR’s ability to eventually converge after extended runtime (e.g. 10 hours per equation versus 40 iterations for LaSR), LaSR consistently discovers higher‐quality hypotheses while also uncovering equations that other methods cannot derive.
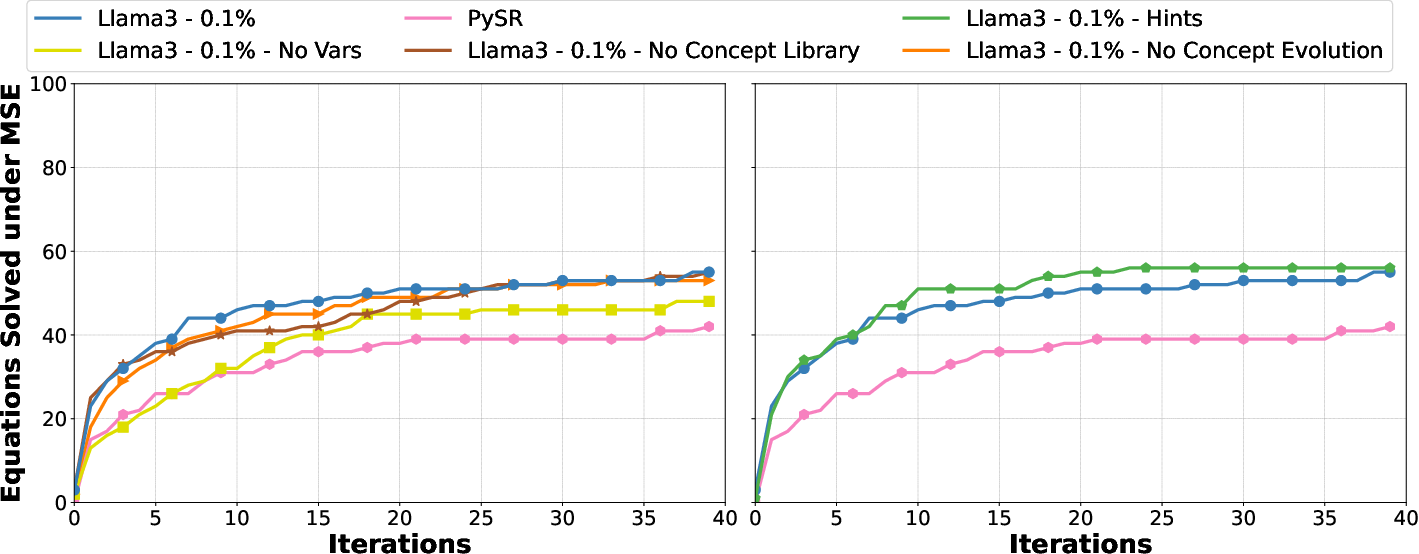
Figure 6: Evaluation results for ablations and extensions of LaSR showing how components such as concept evolution and the concept library accelerate search performance on the Feynman dataset.
Furthermore, LaSR is extended in a cascading experimental setup wherein different LLM backbones and mixture probabilities are deployed sequentially. These experiments emphasize that even minimal language guidance—using open-source backbone models—yields substantial improvements over classical genetic operations. In one notable application, LaSR is applied to data from BigBench to discover a scaling law predicting LLM performance over training steps and shots. The discovered empirical law, which requires only three free parameters compared to the five of standard formulations (e.g. Chinchilla scaling law), demonstrates competitive MSE loss values on held-out data.
Additional qualitative analyses highlight that LaSR’s output is twofold: in addition to the discovered equation, the evolving concept library provides interpretable textual summaries of early, intermediate, and late-stage evolutionary patterns. For example, early iterations capture coarse relationships using power and trigonometric functions, while later iterations exhibit symmetry and functional structure similar to Coulomb’s law. Such insights are not only useful for the mathematical fitting process but also facilitate scientific interpretation.
Discussion and Implications
The results reinforce that embedding natural language priors into the symbolic regression process can help overcome local minima that plague pure genetic-based search methods. By introducing LLM-based operators and a continually updated concept library, LaSR achieves both a lower complexity in discovered solutions and superior fit (with loss reductions reaching as low as ~4.67×10−14 on certain equations) compared to standard approaches. The framework’s capability to rediscover well-known physical laws (e.g. inverse square laws, Coulomb’s law) and derive novel relations in high-dimensional problems hints at significant potential for automated scientific discovery. Moreover, LaSR’s successful extraction of novel scaling laws for LLMs suggests a broader applicability to self-improving systems—as future LLM advancements promise faster and more accurate natural language inference, the performance and generalizability of LaSR are expected to further improve.
Conclusion
LaSR integrates LLM-guided genetic operations with a dynamic concept library to enhance symbolic regression. It outperforms classical methods on challenging scientific benchmarks, achieving higher exact matching rates and lower loss scores, while also providing interpretability through its evolving concept library. The work opens promising avenues for combining LLM reasoning with search-based synthesis across diverse domains, and its potential for novel empirical discovery underscores its theoretical and practical implications in AI research.