- The paper presents an omni-dimensional VAE that compresses videos both spatially and temporally, significantly improving latent representations and reconstruction accuracy.
- The paper introduces a 3D-causal-CNN architecture with four model variants to balance compression speed and quality, highlighting Variant 4 for its optimal performance.
- The paper implements tail initialization and temporal tiling techniques to leverage pre-trained SD-VAE capabilities and efficiently process videos of arbitrary lengths.
OD-VAE: An Omni-dimensional Video Compressor for Improving Latent Video Diffusion Model
This essay provides an authoritative summary of the research on the OD-VAE, an omni-dimensional compression Variational Autoencoder (VAE) designed to enhance the efficiency and effectiveness of Latent Video Diffusion Models (LVDMs). The OD-VAE addresses the limitations of existing VAE implementations by enabling temporal compression in addition to spatial compression, thereby facilitating more concise latent representations. The discussion encompasses the methodological innovations, variant analyses, initialization strategies, and experimental evaluations that underpin the advancements offered by OD-VAE.
Introduction to OD-VAE
LVDMs frequently incorporate VAEs for compression of video data into latent representations. Conventional VAEs, such as the Stable Diffusion VAE (SD-VAE), typically perform spatial compression only, which results in redundancy along the temporal dimension of videos. The OD-VAE proposes an omni-dimensional compression approach, integrating both spatial and temporal compression, to achieve more concise latent representations while preserving reconstruction accuracy.
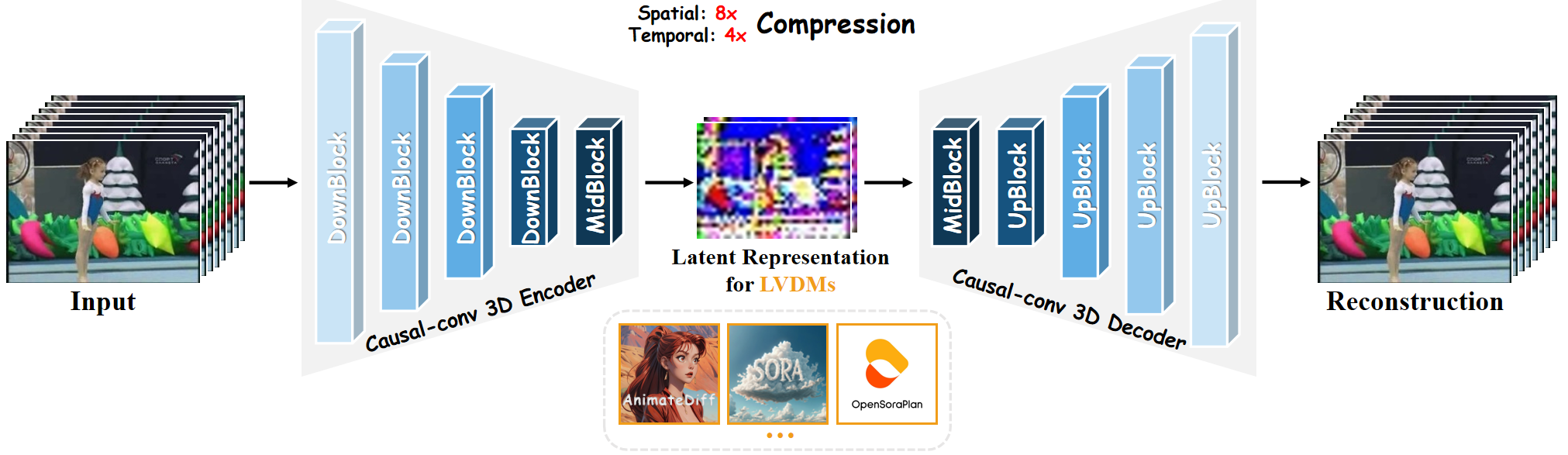
Figure 1: The overview of our OD-VAE. It adopts 3D-causal-CNN architecture to temp-spatially compress videos into concise latent representations and can reconstruct them accurately. This greatly enhances the efficiency of LVDMs.
Architecture and Variants of OD-VAE
OD-VAE Overview
The OD-VAE utilizes a 3D-causal-CNN architecture to compress videos spatially and temporally, leveraging high temporal correlation present in video frames for accurate reconstruction. The architecture considers each video frame as part of a continuous sequence rather than isolated images, enhancing compression efficiency and reconstruction quality.
Model Variants
To balance compression speed and reconstruction quality, four variants of OD-VAE were introduced:
- Variant 1 involves inflating all 2D convolutions to 3D convolutions, optimizing video reconstruction but reducing compression speed due to computational demands.
- Variant 2 replaces half the 3D convolutions with 2D convolutions, aiming to expedite processing while retaining spatial and temporal transformational capacity.
- Variant 3 substitutes the 3D convolutions in outer blocks with 2D convolutions, enhancing compression speed by modifying high-consumption stages first.
- Variant 4 retains a full 3D decoder to preserve reconstruction quality, and replaces only the encoder’s outer block 3D convolutions, maintaining processing efficiency.

Figure 2: Four variants of our OD-VAE. Variant 1: inflating all the 2D convolutions in SD VAE to 3D convolutions. Variant 2: replacing half of the 3D convolutions in variant 1 with 2D convolutions. Variant 3: replacing the 3D convolutions in the outer blocks of variant 1's encoder and decoder with 2D convolutions. Variant 4: replacing the 3D convolutions in the outer blocks of variant 1's encoder with 2D convolutions.
Initialization and Temporal Processing
Tail Initialization
The tail initialization strategy utilizes weight inheritance from 2D SD-VAEs to improve spatial compression and reconstruction abilities, thereby accelerating training convergence. This method effectively transfers compression accuracy without learning overhead, leveraging pre-existing spatial capabilities of SD-VAE for efficiency enhancement.
Temporal Tiling
To accommodate processing videos of arbitrary length within constrained computational resources, the temporal tiling strategy is employed. This approach segments videos with overlapping frames, ensuring seamless concatenated outputs that mitigate errors and maintain high temporal correlation across groups.
Experimental Evaluation
Extensive experiments validate the superiority of OD-VAE in video reconstruction and LVDM efficiency. Metrics including PSNR, SSIM, LPIPS, and FVD demonstrate that OD-VAE consistently outperforms its contemporaries (e.g., SD-VAE and OPS-VAE) in both compression efficacy and video generation quality.

Figure 3: Video generation results of LVDMs with different VAEs on the SkyTimelapse dataset. As the figure shows, with OD-VAE, LVDM can generate more realistic and high-quality videos.
Performance tests on popular datasets like WebVid-10M and UCF101 underscore the nimble processing capabilities of OD-VAE variants, highlighting variant 4 as the optimal configuration for harmonizing compression speed with video quality.
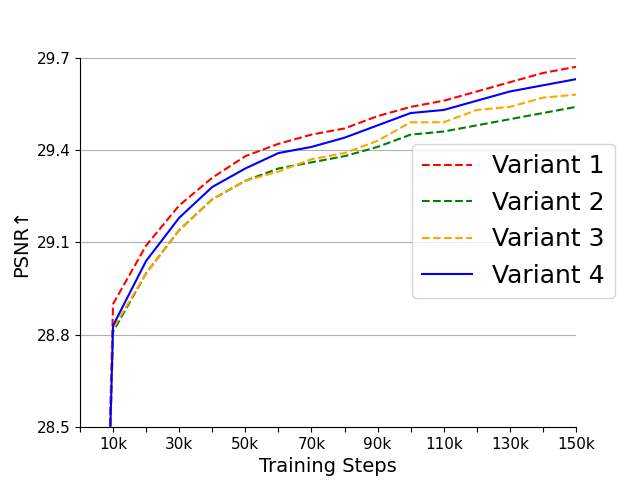
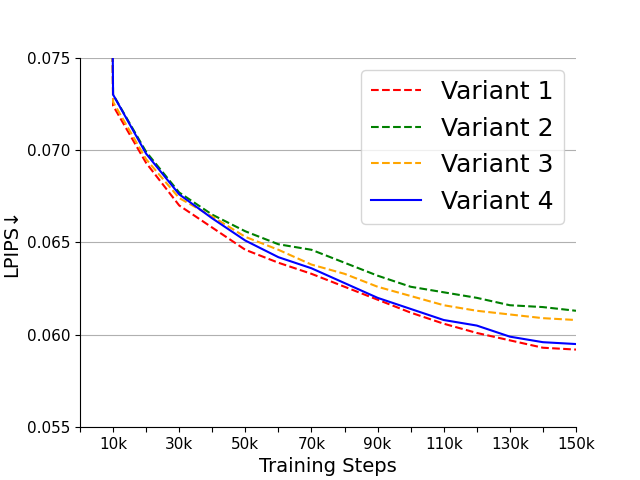
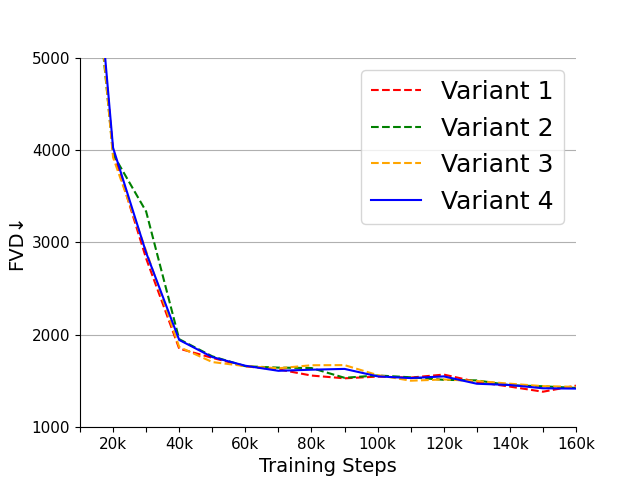
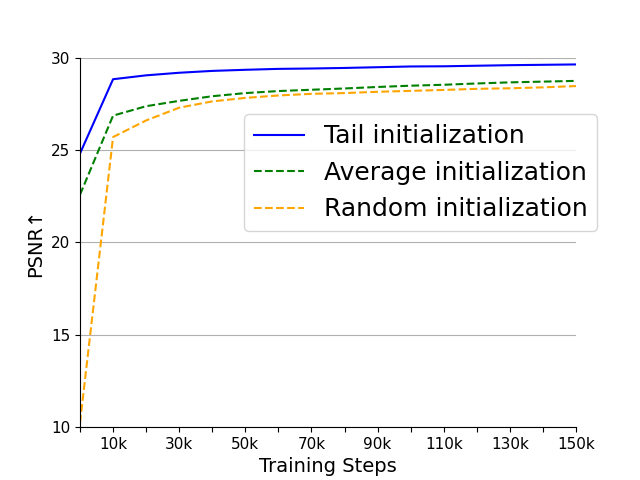
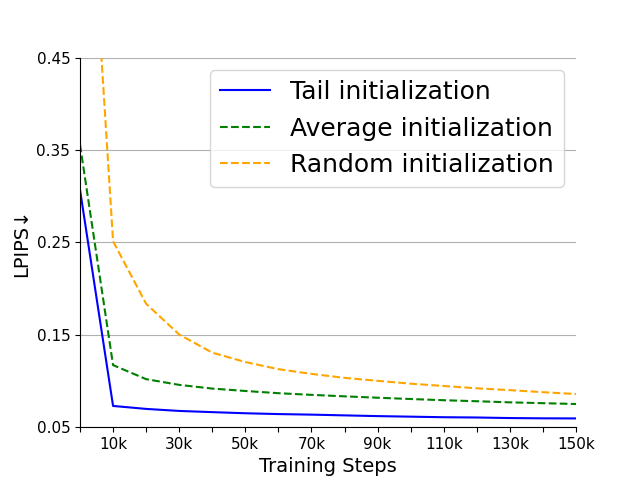
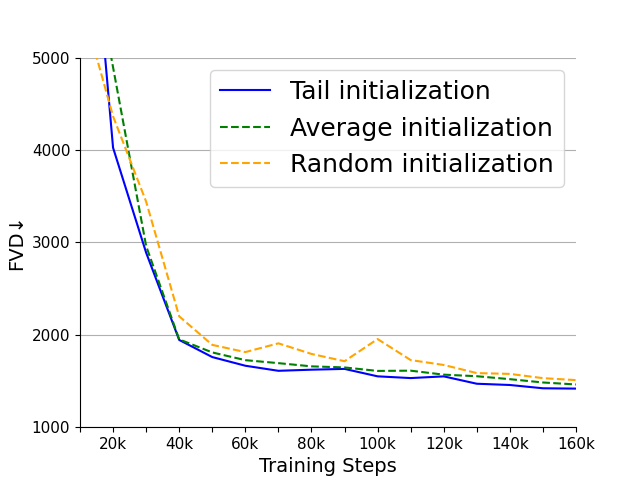
Figure 4: (a), (b) are the PSNR and LPIPS of the four variants on the WebVid-10M validation set. (c) is the FVD of the four variants on the UCF101 dataset. (d), (e) are the PSNR and LPIPS of the three initialization methods on the WebVid-10M validation set. (f) is the FVD of the three initialization methods on the UCF101 dataset.
Conclusion
OD-VAE represents a significant advancement in video compression methods within LVDMs, offering omni-dimensional compression that sharply reduces hardware demands and enhances video generation capabilities. The adoption of an optimized 3D-causal-CNN structure, along with targeted strategies like tail initialization and temporal tiling, ensures robust performance across varied scenarios. The strong numerical results and efficiency gains pave the way for further exploration into compressive methodologies that transcend conventional spatial constraints, offering promising directions for future LVDM developments.

