GroomCap: High-Fidelity Prior-Free Hair Capture
Abstract: Despite recent advances in multi-view hair reconstruction, achieving strand-level precision remains a significant challenge due to inherent limitations in existing capture pipelines. We introduce GroomCap, a novel multi-view hair capture method that reconstructs faithful and high-fidelity hair geometry without relying on external data priors. To address the limitations of conventional reconstruction algorithms, we propose a neural implicit representation for hair volume that encodes high-resolution 3D orientation and occupancy from input views. This implicit hair volume is trained with a new volumetric 3D orientation rendering algorithm, coupled with 2D orientation distribution supervision, to effectively prevent the loss of structural information caused by undesired orientation blending. We further propose a Gaussian-based hair optimization strategy to refine the traced hair strands with a novel chained Gaussian representation, utilizing direct photometric supervision from images. Our results demonstrate that GroomCap is able to capture high-quality hair geometries that are not only more precise and detailed than existing methods but also versatile enough for a range of applications.
Summary
- The paper introduces a prior-free method using neural implicit representations to capture detailed 3D hair geometry from multi-view images.
- It employs a three-stage pipeline with volumetric hair tracing and Gaussian-based optimization to refine approximately 150K hair strands.
- The method demonstrates robust performance across diverse hairstyles, outperforming existing techniques in realistic hair reconstruction.
High-Fidelity Prior-Free Hair Capture
The paper "GroomCap: High-Fidelity Prior-Free Hair Capture" (2409.00831) introduces a novel multi-view hair capture method, GroomCap, that reconstructs faithful and high-fidelity hair geometry without relying on external data priors. This method addresses limitations of conventional reconstruction algorithms by proposing a neural implicit representation for hair volume that encodes high-resolution 3D orientation and occupancy from input views. Furthermore, the paper introduces a Gaussian-based hair optimization strategy to refine the traced hair strands with a novel chained Gaussian representation, utilizing direct photometric supervision from images.
Method Overview
GroomCap's pipeline comprises three stages. The first stage establishes an implicit hair volume encoding spatial occupancy and orientation from multi-view image captures. (Figure 1) shows the inputs to the pipeline. In the second stage, initial hair strands are grown within the hair volume based on heuristics. The final stage refines the hair geometry through Gaussian-based hair optimization, utilizing differentiable rendering with chained hair Gaussians. The pipeline outputs approximately 150K hair strands, each explicitly represented as a polyline with 100 points.

Figure 1: The input to our pipeline includes calibrated multi-view images (left), semantic segmentations of hair and foreground (middle), reconstructed inner and outer meshes with the hair bounding box (right), and optional hair partline annotation on one image (middle column, first row).
Data Acquisition and Preparation
The method uses a multi-camera system with 64 cameras at 4K resolution under uniform illumination. Semantic segmentation masks categorize each pixel as background, hair, or body. A rough surface reconstruction of the subject is achieved using the technique described in [guo2019relightables], dilated to encompass all hairs, serving as the outer mesh. A fitted parametric head mesh model provides the inner mesh, approximating the subject's bald surface for locating the hair scalp. A loose 3D bounding box of the hairs is derived by projecting per-view hair segmentation onto the outer mesh. An optional 2D annotation of the parting line can be provided from a top-down view.
Neural Hair Volume
The implicit hair volume is formulated as an MLP network V. The input to V is a 3D position ∈3, and the output includes volume density σ∈[0,1], hair occupancy ρh∈[0,1], body occupancy ρb∈[0,1] and 3D hair orientation in polar angles (θ∈(0,π],ϕ∈(0,π]). During training, V is additionally fed with the view direction vector ∈3 and receives the view-dependent radiance color ∈3, similar to NeRF. The model architecture (Figure 2) includes a shared feature network, an appearance network, and a structure network.
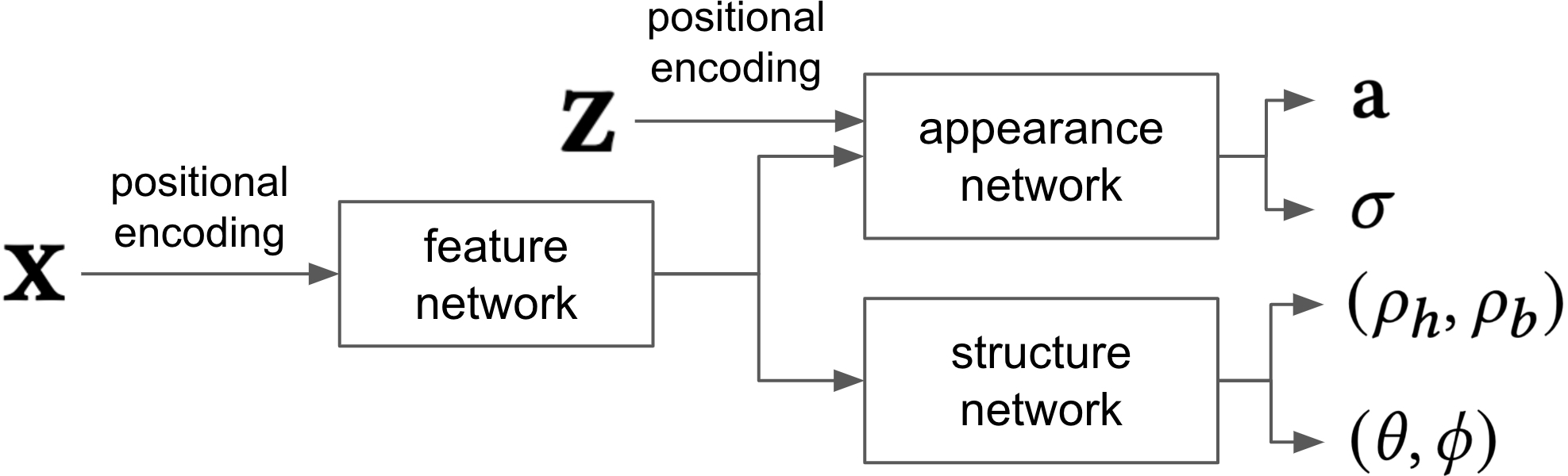
Figure 2: The implicit hair volume network comprises three sub-modules: the feature network and appearance network are used to estimate view-independent volume density σ and view-dependent radiance from input position and view direction , similar to NeRF; an additional structure network is devised to estimate hair ρh and body occupancy ρb as well as 3D orientation (θ,ϕ) in polar angles.
Neural Orientation Field
The volumetric orientation plays a crucial role in defining the 3D hair structure. The method optimizes a neural orientation field that estimates 3D orientations without explicit resolution limitations. To construct this field, a new formulation "renders" 3D orientations within the volume rendering paradigm. A single 3D orientation is expanded into a distribution using a predefined kernel function as its PDF. Based on the distribution formulation $\mathcal{H}_$, the accumulated 3D distribution Gr along an arbitrary ray r with PDF is computed using volume rendering.
Supervision with 2D Orientations
The method supervises accumulated 3D orientation distributions G using multi-view images. Instead of representing a pixel's 2D orientation with a single value, the responses of all filters are maintained, forming a distribution of 2D orientations. The 3D orientation distribution G of each ray is projected into a distribution of 2D orientations F. The loss function for the neural orientation field is defined as the integral of the squared difference between the projected 2D orientation distribution and the normalized response of the orientation filter at angle η.
Volume Rendering of 3D Orientations
The paper introduces a novel approach to volume rendering of 3D orientations by expanding single 3D orientations, represented as polar angles, into distributions and performing alpha-blending on these distributions. For a 3D position ,withpolarangles(\theta_, \phi_),itsdistributionof3Dorientations\mathcal{H}_isconstructedusingapredefinedkernelfunctionasitsPDFh_{}: h_(\theta, \phi) = \frac{1}{C_} h'_(\theta, \phi)
$$</p> <p>h'<em>(\theta, \phi) = \frac{1}{\beta(||\theta - \theta</em>||<sup>2</sup> + ||\phi - \phi_||<sup>2)</sup> + \delta}</p> <p>$$
C_ = \iint_{0}{\pi} h'_(\theta, \phi)\diff \theta \diff \phi \mathrm{.}
$### Neural Occupancy Field The implicit hair volume further establishes neural occupancy fields by predicting hair occupancy value $\rho_handbodyoccupancyvalue\rho_batanygivenposition.Thecontinuousvaluesofhairoccupancynaturallyalignwiththefactthathairsaresemi−transparentinimages.Theoccupancyvalues\rho_*areaccumulatedusingthestandardvolumerenderingformulatogiveper−pixellabels\psi_{*}andsupervisedbypseudogroundtruth(GT)segmentationlabels\bar{\psi}_{*}:
\mathcal{L}_\mathrm{occ} = ||\psi_h - \bar{\psi}_h||2 +||\psi_b - \bar{\psi}_b||2.
$The GT masks do not need to be perfect; the segmentations estimated by the method outperform GT due to implicitly integrated multi-view information. ### Training Strategy The model undergoes a two-phase training process. Initially, only the feature and appearance networks are trained with the conventional L2 photometric loss. In the subsequent phase, the structure network is trained alone with loss $100 \mathcal{L}_\mathrm{ori} + 0.02 \mathcal{L}_\mathrm{occ}$, and the other two modules are frozen. The reconstructed outer mesh is used to decide the depth sampling range of the rays, ensuring the model focuses exclusively on the hair volume. ## Volumetric Hair Tracing Once the hair volume is established, hair strands are extracted by tracing within the volume using the inferred volumetric orientation and occupancy with forward Newton method. At timestep $k,eachstrandisextendedbyafixedlengthl = 3\mathrm{mm}toanewpoint_k=_{k-1}+l \cdot \mathrm{norm}(_k),wherethegrowingdirection_kbeforenormalizationiscalculatedas:
\begin{split} k=&\gamma\cdot{k-1}+&(1-\gamma)\cdot\big(\sign(\cdot_{k-1})\cdot+\lambda\min(\cdot_{k-1},0)\cdot\big). \end{split} Tracingisinitializedfromseedpointsuniformlysampledwithintheboundingboxvolumebetweentheinnerandtheoutermesh,organizedintoapriorityqueue,weightedbytheproductofvolumedensityandhairoccupancy,\sigma \cdot \rho_h.Ahealthvalueismonitoredforeachstrand,ceasingtracingwhenthisvaluedropsto0.Volumehairs,tracedfromseedsinthisstep,areconnectedtothescalpbytracingadditionalscalphairs,initiatedbysamplingseedsonthescalpregionoftheinnermesh.Ifapartinglineisannotatedforthehairstyle,allhairscrossingitareremovedasarefinementstep.ThefinaloutputisacollectionofN_sstrands\mathcal{S} = \{_1, _2, ..., _{N_s}\},resampledtoN_k = 100vertices,_i \in ^{N_k \times 3}$. ## Gaussian-Based Strand Optimization This stage uses direct supervision from the original images to recuperate lost fine details, ensuring a match to the captured imagery. The image-based differentiable rendering framework of 3D Gaussian spatting (3DGS) is used to optimize the reconstructed hairs using photometric losses. The method introduces a novel chained hair Gaussian formulation that constrains the relationships among Gaussians along each strand, aligning with the inherent geometric nature of hair. ### Formulation of Chained Hair Gaussians The optimization targets are the parameters of hair geometry, rather than the shape and appearance parameters of individual Gaussians. The elementary unit of strands are defined as line segments. For a strand of $N_kvertices,thesegmentbetweenvertex_iand_{i + 1}isdenotedby_i,characterizedbythefollowingparameters:headvertex_i,tailvertex_{i+1},diameterd,opacityo,andsphericalharmonics(SH)coefficients. In the chained Gaussian representation, each segment i is approximated by a Gaussian centered at the midpoint (i+i+1)/2. The covariance matrix C of this Gaussian is expressed as:
C=EDDTET.
Here, E=[i,i′,i′′]T represents the principle axes of the Gaussian, where i is the unit direction vector of the segment i+1−i, and i′ and i′′ are two orthogonal unit vectors to i. The matrix D=diag[τl,τd,τd] contains scales of the axes, with τl=∣∣vi+1−vi∣∣/2 and τd=d/2 being the axial and radial scales, respectively. Auxiliary body Gaussians, anchored at the vertices of the inner mesh and modeled as discs with optimizable radii w, are incorporated to model the non-hair foreground, serving as proxies for occlusion.
Geometry Parameters
Instead of directly optimizing the positions of strand vertices, a low-dimensional latent vector is optimized for each strand. For each subject, a strand variational autoencoder (strand-VAE) is trained that encodes a latent code ∈128 from root-relative vertex positions ′∈(Nk−1)×3.
Appearance Parameters
To limit the per-strand appearance DoF, the following simplifications are proposed to the hair appearance parameters: elimination of view variations of color by reducing the SH degree to zero; spatial variations of color by optimizing the color for only 8 segments (anchors) uniformly distributed along the strand, with color for other segments derived via piecewise linear interpolation; parameterization of segment diameters using 8 anchors; restriction of each strand to 2 opacity values: o1 for the first Nk−Nt−1 segments starting from the root, and o2 for the final Nt=8 segments.
Adaptive Control of Hair Gaussians
During optimization, the strand distribution is adaptively controlled by periodically employing heuristic-based actions including splitting and pruning. For each strand si with Nk−1 segments, given its per-segment diameters di,j and opacities oi,j for the j-th vertex, the per-strand split score ωi is computed as:
$\omega_i = \frac{\hat{\omega_i}{\frac{1}{N_s} \sum_{i = 1}^{N_s}\hat{\omega}_i}, \quad \hat{\omega}_i = \sum_{j=1}^{N_k - 1} d_{i,j} \cdot o_{i,j} \mathrm{.}$
Strands are split into ⌈ωi⌉ new strands, whose vertices are generated by randomly displacing the original positions within its diameter. Invisible strands are identified and pruned based on their opacity and color. Strands whose average vertex opacity falls below a threshold of 0.1 are removed, and strands whose average color is closer to the background color than to the average hair color are pruned.
Training Objectives
The primary loss during optimization is the L2 photometric distance between rendered images and reference images, denoted as Li. Additional regularization terms include:
- Volume Guidance Term:
Ln=Nk−11i=1∑Nk−1min(∣∣i−i∣∣,∣∣i+i∣∣),
where i is the direction of the hair segment, and i is the undirectional 3D orientation prediction at (i+1+i)/2.
- Penetration Prevention Term:
Lp=Nk1i=1∑Nk∣∣i−~i∣∣2,
where ~i is the nearest point on the inner mesh surface to i.
Heuristic Terms:
- Diameter term: Ld=i=1∑Nk−1∣di∣/(Nk−1)
- Latent regularization term: L=∣−^∣
- Body radius term: Lb=i=1∑Nb∣∣wi−w^i∣∣2/Nb
The overall training objective is:
L=λiLi+λnLn+λpLp+λdLd+λL+λbLb,
where the weights are set as described in the paper.
Experimental Results
The results on various hairstyles captured in the studio show that the method can reconstruct diverse hairstyles that surpass the coverage of any existing dataset, capturing personal details such as hairlines, fringes, and clusters. (Figure 3) shows the results on various hairstyles. GroomCap can handle short hairs and long ponytails using the same pipeline.

Figure 3: Reconstruction results on diverse hairstyles from short hairs to long ponytails, where personal features such as fringe, hairline, and clusters are faithfully captured. We use the same predefined material to better show geometric details.
Comparisons with state-of-the-art multi-view hair reconstruction works MonoHair and Neural Haircut on the in-the-wild NHC dataset demonstrate that while the reconstructions on this dataset are inferior to the primary setting due to the imperfect inputs, they remain comparable with the concurrent work of MonoHair and outperform the earlier work of NeuralHaircut. (Figure 4) shows a comparison of GroomCap with existing methods.

Figure 4: Comparions with existing hair reconstruction methods. We compare GroomCap with MonoHair [wu24monohair] and Neural Haircut [sklyarova23neural] on the in-the-wild NHC dataset, rendered with the same renderer. The rendering camera of NeuralHaircut results are manually adjusted to match the input.
Ablation Studies
Ablation studies for implicit hair volume show that supervising only the maximum angles results in locally over-smooth strands because non-maximum orientations are discarded, while blending 3D orientations by directly summing polar angles yields even worse results, as it is mathematically flawed. Estimated volume densities and 3D orientations show that the 3D orientations match different hair layers and lead to correct hair intersections, which is crucial for avoiding over-smoothness for tracing. The ablation study for implicit hair volume is shown in (Figure 5).

Figure 5: Ablation studies for implicit hair volume. We show strands traced from different hair volumes, including full method (second column), 2D supervision of maximum orientations without keeping the distribution (third column), and directly alpha-blending 3D orientation angles without our rendering algorithm (fourth column). The results are either overly smoothed (third column) or contain incomplete and sparser strands (fourth column).
Ablation of the Gaussian-based optimization stage demonstrates that the optimization leads to improved hair boundaries, more uniform hair density, and more natural strand geometry.
(Figure 6) visualizes 3D orientation predictions. (Figure 7) shows ablation studies for Gaussian-based hair optimization. (Figure 8) and (Figure 9) show additional ablations for Gaussian-based hair optimization and the strand latent space, respectively.
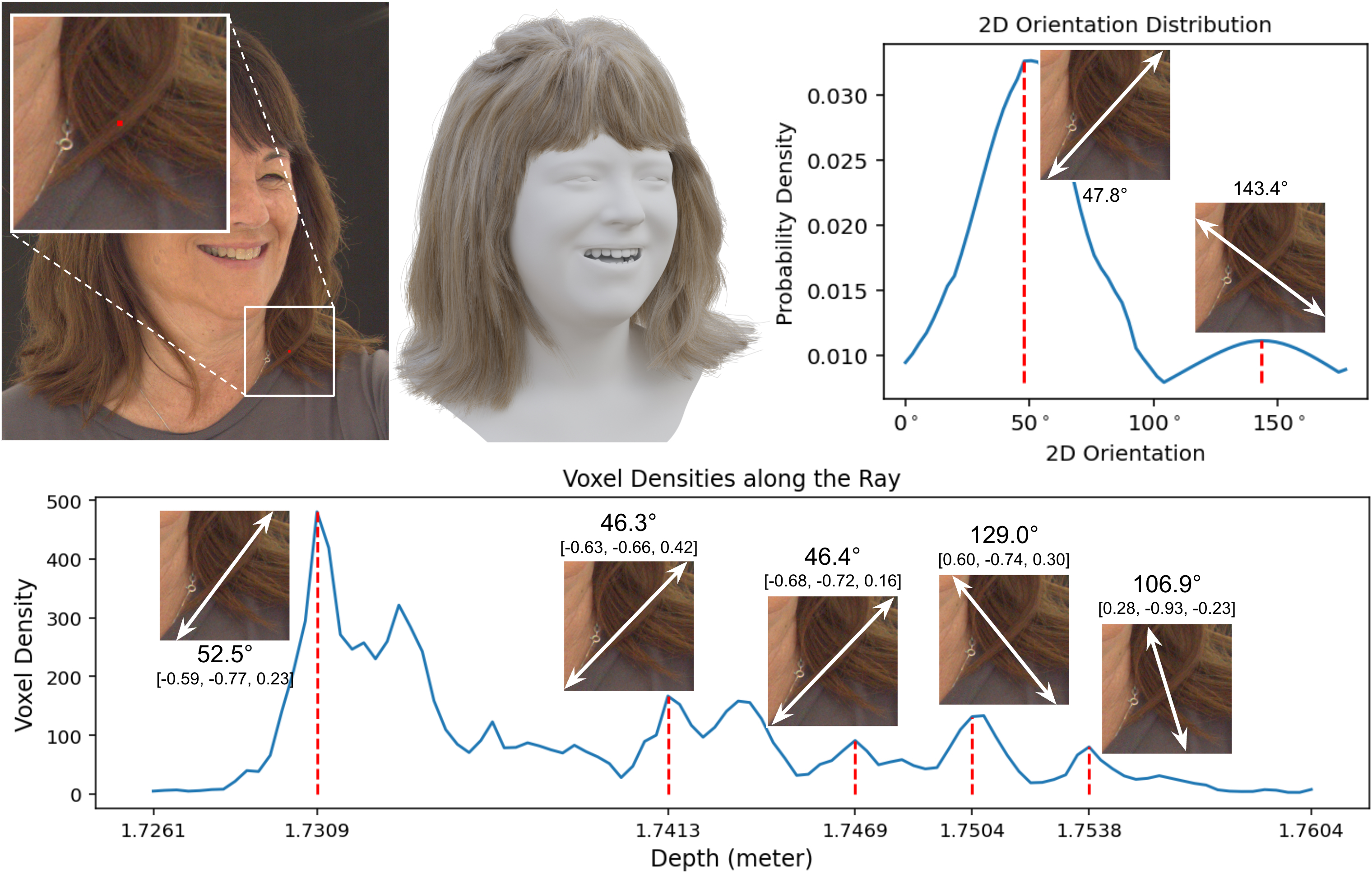
Figure 6: Visualization of 3D orientation predections. On an example subject, we show a reference view (top-left) and the corresponding hair reconstruction (top-middle). In the reference view, we highlight a sample patch (the white square) where two intersecting wisps are accruately captured in the output. In the lower part of this figure, we plot voxel densities along the ray path at the center of the patch using a line chart. For each density peak, we visualize the corresponding predicted 3D orientation by drawing an arrow over the patch. The first peak represents the front hair wisp with a 3D orientation in camera space of [-0.59, -0.77, 0.23] and a 2D projection of 52.5∘. Beginning at depth $1.75$m (the fourth peak), the ray intersects the back layer of hair, with 2D projections ranging from 107∘ to 130∘. At the top-right, we visualize the accumulated 2D orientation distribution along the same ray at the patch center, identifying two peaks. The first peak at 48∘ correlates to the front hairs, while the second peak at 143∘ corresponds to the hair at the back.

Figure 7: Ablation studies for Gaussian-based hair optimization. In the second and third columns, we show hair models before and after optimization, respectively. The optimization effectively consolidates the hair boundary and enhance overall smoothness. In the fourth column, we show an initial hair model that is intentionally smoothed from the traced hairs to better highlight the difference brought by optimization. The fifth column demonstrates that, even from this smoothed initial hair, the optimization is capable of faithfully recovering detailed features. However, as shown in the sixth column, keeping the high degree-of-freedom parameters of the vanilla 3DGS leads to flattened strands, which underscores the importance of our tailored Gaussian parameters.

Figure 8: Additional ablations for Gaussian-based hair optimization. Each triplet shows the reference view (left), the result of our full method (middle), and the result of the ablated baseline (right). Top left: the hair without adaptive splitting suffers from worse coverage and wisp structures. Top right: optimization without adaptive pruning leads to excessively long strands. Bottom left: using a pre-trained prior strand-VAE leads to overly smoothed strands due to poor coverage of the synthetic data. Bottom right: regularization with the implicit hair volume helps enhance the hair structure.
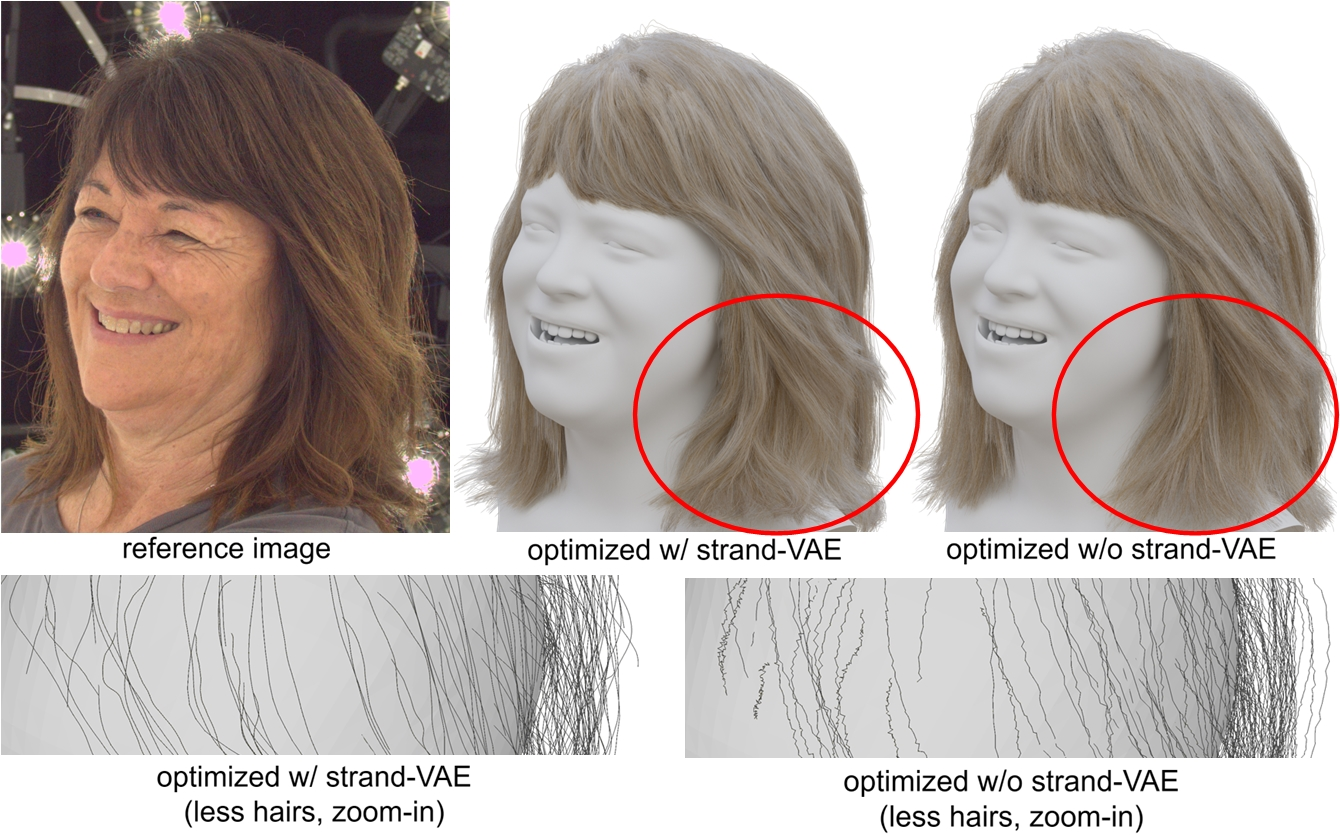
Figure 9: Ablation study for the strand latent space. Optimization within the strand latent space of strand-VAE achieves globally consistent strand deformations that are smoothly regularized (top-middle and bottom-left). In contrast, replacing this latent space regularization with a strong smoothing term fails to prevent sharp turns in the strands (bottom-right), even when the overall hair is already overly smoothed (top-right).
Applications
The method reconstructs explicit hair geometry as a dense set of polyline curves. Compared to implicit representations, the reconstruction can be easily used in other applications, such as physically-based rendering (Figure 10), simulation (Figure 11), and hair editing (Figure 12).

Figure 10: Hair re-rendering application. We render the reconstructed hair geometry using different materials (row 1) and environment lightings (row 2) with a physically-based renderer.

Figure 11: Hair simulation application. In each image pair, we demonstrate the original captured hairs (left), and the hairs deformed with quasi-static simulation at a given head pose. The simulation is performed using the industrial software Houdini.

Figure 12: Hair editing application. We perform haircut by keeping 80\% (60\%) of the original vertices for each hair strand.
Limitations
Challenges arising from dark hair appearances and extremely curly strands can cause difficulties across all stages: retrieved orientations are noisy, traced strands appear messy, and optimization struggles to effectively enhance the hair quality. Integrating prior knowledge with the flexible prior-free capture pipeline represents a promising avenue for future research. (Figure 13) shows failure cases for the method.

Figure 13: Failure cases. For the extremely complicated hairstyles, our method fails to capture all the small curls.
Conclusion
GroomCap presents a prior-free approach for capturing hair geometry from multi-view inputs. It bridges the gap between high-fidelity hair modeling and practical application needs. The success of GroomCap highlights its potential as a transformative tool in various scenarios where high-quality hair is desired.
Paper to Video (Beta)
No one has generated a video about this paper yet.
Whiteboard
No one has generated a whiteboard explanation for this paper yet.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Open Problems
We haven't generated a list of open problems mentioned in this paper yet.
Continue Learning
- How does GroomCap compare with state-of-the-art multi-view hair reconstruction methods?
- What are the main advantages of using a neural implicit representation for hair capture?
- How does the Gaussian-based hair optimization refine the reconstructed hair strands?
- What limitations does GroomCap encounter with dark or extremely curly hair?
- Find recent papers about neural hair capture.
Related Papers
- GaussianHair: Hair Modeling and Rendering with Light-aware Gaussians (2024)
- Neural Haircut: Prior-Guided Strand-Based Hair Reconstruction (2023)
- MonoHair: High-Fidelity Hair Modeling from a Monocular Video (2024)
- GroomGen: A High-Quality Generative Hair Model Using Hierarchical Latent Representations (2023)
- HairNet: Single-View Hair Reconstruction using Convolutional Neural Networks (2018)
- Perm: A Parametric Representation for Multi-Style 3D Hair Modeling (2024)
- Human Hair Reconstruction with Strand-Aligned 3D Gaussians (2024)
- StrandHead: Text to Strand-Disentangled 3D Head Avatars Using Hair Geometric Priors (2024)
- GeomHair: Reconstruction of Hair Strands from Colorless 3D Scans (2025)
- DiffLocks: Generating 3D Hair from a Single Image using Diffusion Models (2025)
Collections
Sign up for free to add this paper to one or more collections.
Tweets
Sign up for free to view the 1 tweet with 0 likes about this paper.