- The paper introduces YOLOv8's novel architecture, leveraging CSPNet, an anchor-free detection head, and enhanced FPN+PAN designs to optimize performance.
- The paper demonstrates advanced training techniques, such as innovative data augmentation, focal loss, and mixed precision training, to boost detection accuracy and efficiency.
- The paper validates YOLOv8's superiority with higher mAP and reduced inference times, making it ideal for real-time applications across diverse hardware.
In-Depth Exploration of YOLOv8: An Analysis of Architectural and Training Innovations
Introduction
YOLOv8 emerges as the latest advancement in the series of object detection models, innovatively refining the architecture of its predecessors, particularly YOLOv5, to achieve enhanced performance metrics in terms of accuracy, speed, and efficiency in real-time applications. This paper thoroughly evaluates YOLOv8's design and training methods, highlighting its suitability for various practical scenarios across hardware environments, and exploring the model's impact on the evolving landscape of computer vision.
Architectural Innovations
YOLOv8 is designed around a sophisticated architectural framework that integrates cutting-edge components to optimize both feature extraction and object detection capabilities.
Backbone
The backbone of YOLOv8 leverages a variant of the CSPNet architecture to efficiently extract hierarchical features from input images. This configuration captures a spectrum of texture and semantic information crucial for accurate detection, balancing both accuracy and computational efficiency through the use of depthwise separable convolutions.
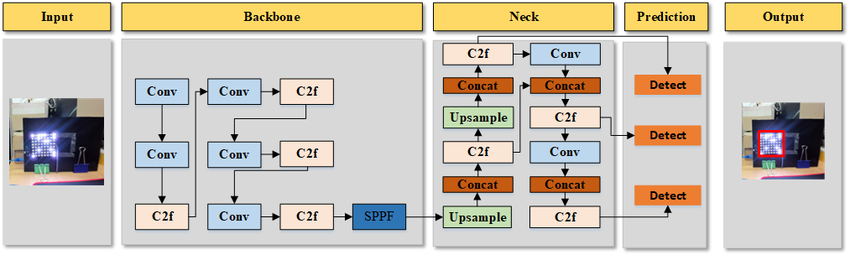
Figure 1: Process of Object Detection
Neck
The neck of YOLOv8 utilizes an enhanced version of the FPN+PAN design to effectively combine multi-scale features. This integration supports the detection of objects at varying scales, optimizing information flow and computational resource allocation across the model.
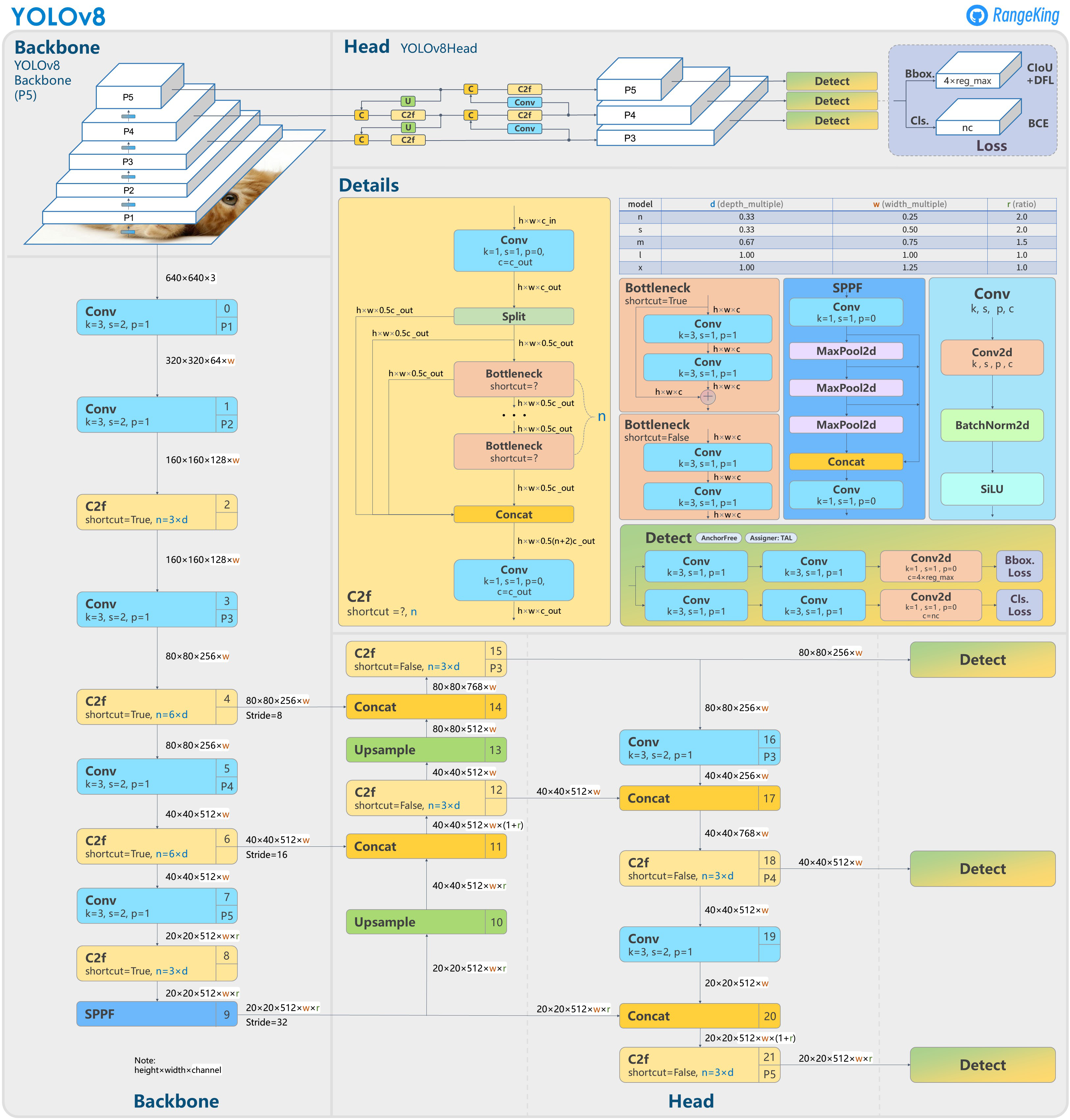
Figure 2: Model Structure of Yolov8
Head
Transitioning to an anchor-free architecture, the head in YOLOv8 simplifies bounding box prediction, reducing the complexity inherent in anchor-based approaches. This move not only streamlines model training but also enhances adaptability to numerous object shapes and sizes.
Advanced Training Techniques
YOLOv8's training methodologies feature several advancements aimed at improving generalization and detection performance.
Data Augmentation
Incorporating innovative techniques like improved mosaic and mixup augmentations allows YOLOv8 to expose the model to diverse object appearances, thereby enhancing robustness and dataset generalization.
Focal Loss Function
Adopting a focal loss function allows YOLOv8 to address class imbalance by preferentially weighting difficult examples, improving the model's focus on accurately identifying small or occluded objects.
Mixed Precision Training
By employing mixed precision training, YOLOv8 enhances computational efficiency, accelerating training and inference processes while reducing memory usage, which is especially advantageous for deployment in resource-limited settings.
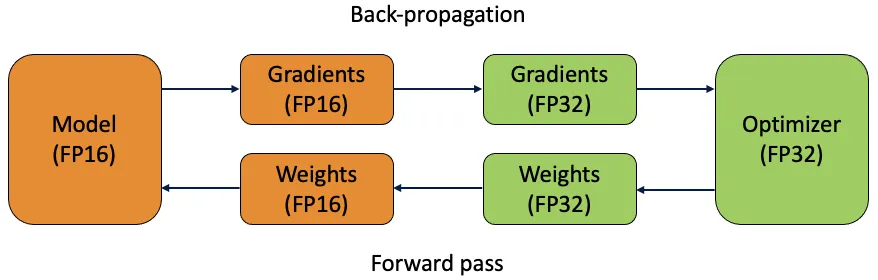
Figure 3: Mixed precision training
YOLOv8's performance is substantiated through comparisons with its predecessors, emphasizing its superiority in various key metrics.
Comparative Metrics
Performance evaluations reveal that YOLOv8 achieves a higher mean Average Precision (mAP) with reduced inference and training times, underscoring its effectiveness for applications requiring real-time processing with high precision.
Additionally, YOLOv8 is shown to have a smaller model size compared to earlier versions, facilitating deployment across a range of hardware, from edge devices to high-performance computing setups.
Model Variants
The YOLOv8 series provides a selection of models, from YOLOv8n optimized for edge deployments to the highly precise YOLOv8x, tailored for scenarios demanding maximum accuracy.
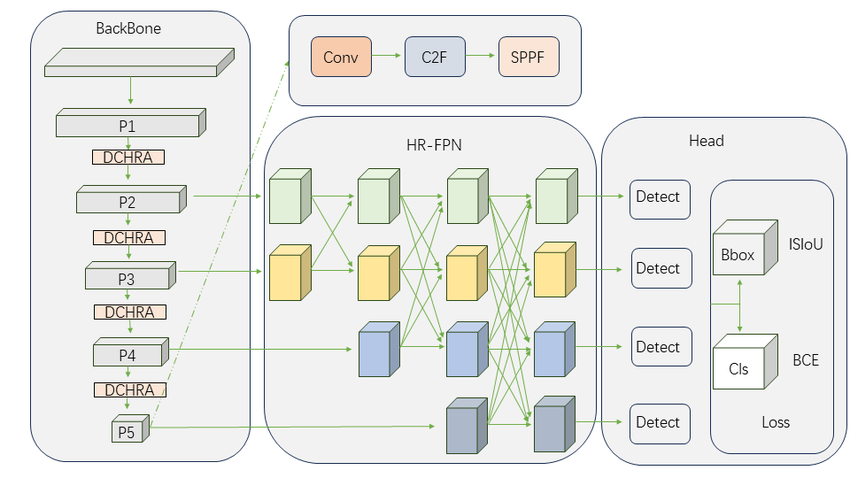
Figure 4: Variations of FPN architectures in YOLOv8
Practical Implications and Future Prospects
The YOLOv8 model represents a significant milestone in object detection, offering a blend of architectural refinement and advanced training strategies that enhance its applicability across diverse applications. Future work is anticipated to sustain the trajectory of innovations within the YOLO framework, potentially incorporating transformer-based architectures or greater integration with edge computing paradigms to extend their impact further.
Conclusion
YOLOv8 stands as a robust and efficient model in the object detection domain, leveraging architectural and training enhancements to deliver significant performance improvements over its predecessors. Through its superior accuracy, speed, and flexibility, YOLOv8 is positioned to effectively address the growing demands of real-time computer vision applications, maintaining its standing as a pivotal contribution to both research and industrial deployment.

