A Comprehensive Survey on Diffusion Models and Their Applications
Abstract: Diffusion Models are probabilistic models that create realistic samples by simulating the diffusion process, gradually adding and removing noise from data. These models have gained popularity in domains such as image processing, speech synthesis, and natural language processing due to their ability to produce high-quality samples. As Diffusion Models are being adopted in various domains, existing literature reviews that often focus on specific areas like computer vision or medical imaging may not serve a broader audience across multiple fields. Therefore, this review presents a comprehensive overview of Diffusion Models, covering their theoretical foundations and algorithmic innovations. We highlight their applications in diverse areas such as media quality, authenticity, synthesis, image transformation, healthcare, and more. By consolidating current knowledge and identifying emerging trends, this review aims to facilitate a deeper understanding and broader adoption of Diffusion Models and provide guidelines for future researchers and practitioners across diverse disciplines.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is a big “map” of diffusion models—computer programs that can create new images, sounds, text, and more. The authors explain how these models work, compare different types, and show many ways they’re being used in the real world, from making sharper photos to helping in medicine. They also point out trends, common problems, and what researchers should work on next.
What questions are they asking?
The paper focuses on simple, practical questions:
- What are diffusion models and how do they work?
- What are the main kinds of diffusion models?
- Where are they being used (images, audio, text, medicine, etc.)?
- What new tricks and improvements have researchers invented?
- What are the limits and open problems, and where should the field go next?
How did they do it?
A quick, friendly explanation of diffusion models
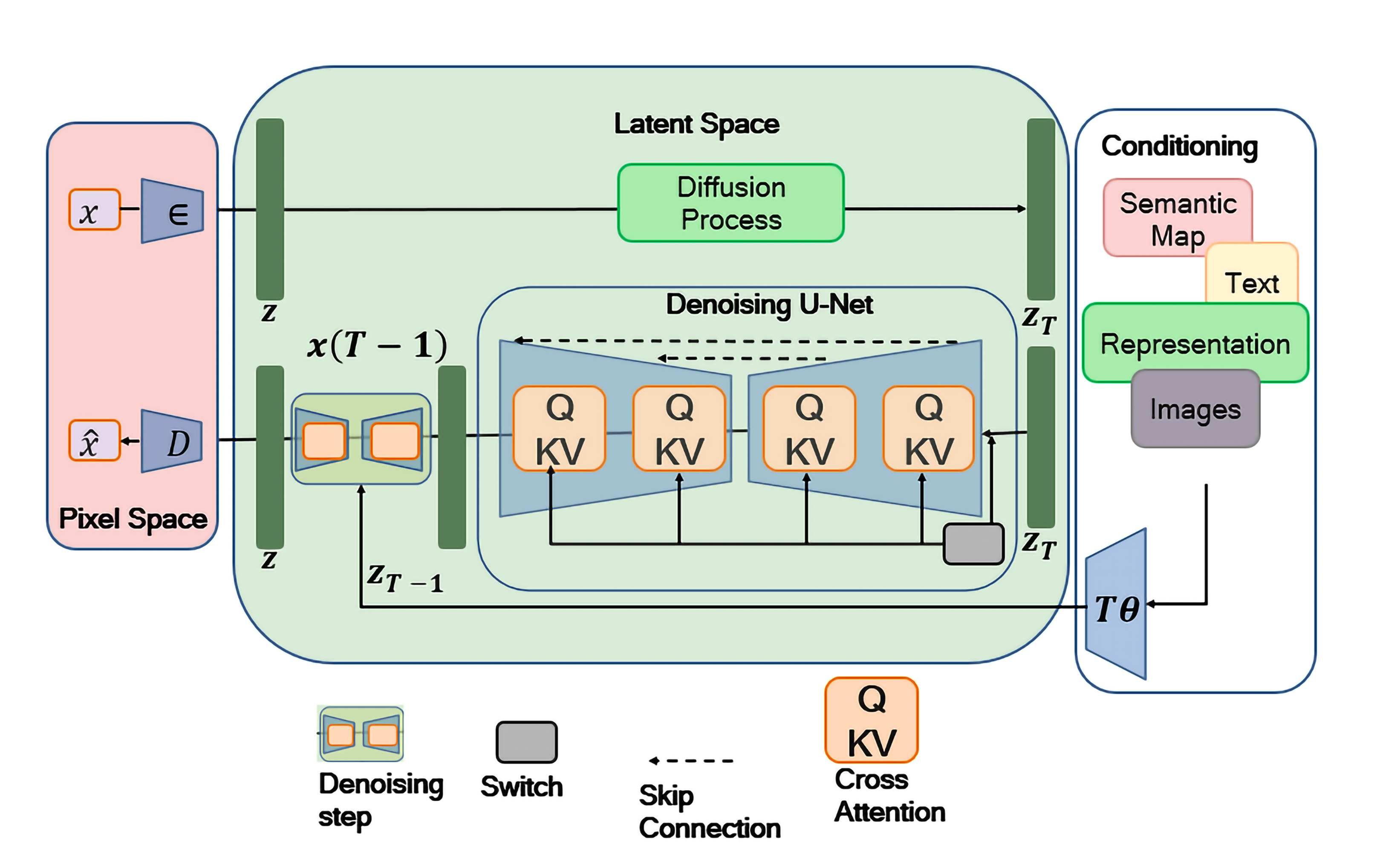
Imagine you have a clear photo. Now, step by step, you add “snowy” static (noise) until the picture looks like TV static. A diffusion model learns the reverse: how to carefully remove the noise, step by step, to get back a clear image. Once it learns this “cleaning” skill, it can start from random noise and “clean” it into something brand new—like a cat that never existed, or a song, or even a short piece of text.
A few key ideas in everyday language:
- Forward process: add tiny bits of noise many times (like fogging up a window slowly).
- Reverse process: learn to remove the noise in small steps (like defogging the window).
- Training: the model practices predicting the noise it needs to remove at each step until it gets really good at it.
- Sampling: start with pure noise and “clean” it into a new image, sound, or text.
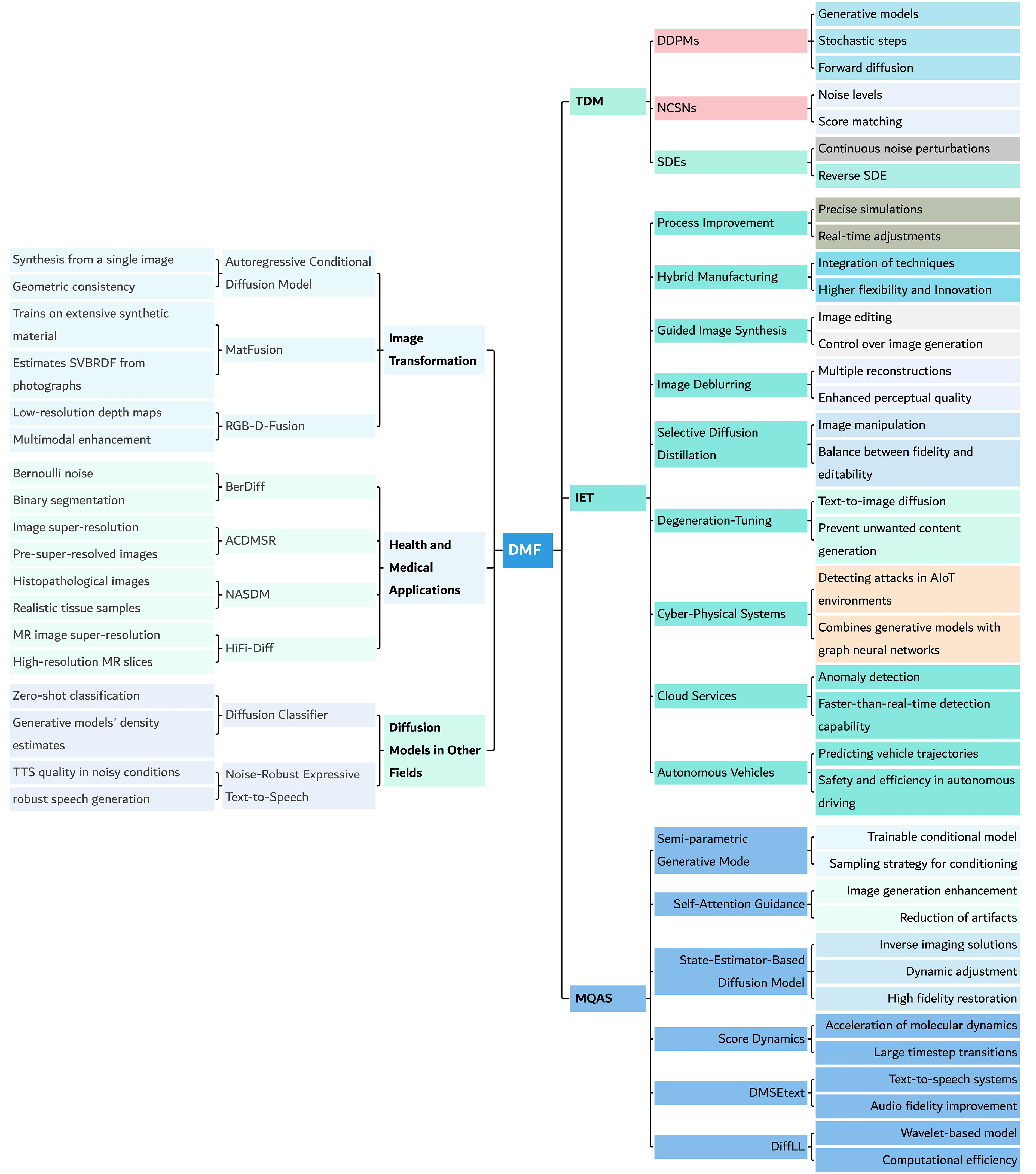
There are three popular “flavors” of diffusion models:
- DDPMs: the classic version that learns to remove noise step by step.
- NCSNs: instead of directly removing noise, they learn which direction makes the image more likely (think of following the slope uphill to a clearer picture).
- SDE-based models: they treat the process as continuous over time, like smoothly turning a dial instead of clicking through steps.
How the survey was done
- They searched a large research database (Scopus) for papers about diffusion models from 2020–2024.
- They filtered results to English, peer-reviewed, open-access papers and removed duplicates and off-topic items.
- In the end, they closely reviewed 85 papers across many fields to understand applications, methods, and results.
What did they find?
Diffusion models are booming
Papers about diffusion models have shot up since 2020. Medicine has the largest share (about 29%), followed by computer science and engineering. That means these models aren’t just for making cool art—they’re also being used for serious scientific and health tasks.
Where they’re used (with simple examples)
- Images: generate new pictures, fix blurry or low-light photos, colorize line drawings, turn sketches into detailed images, or translate text descriptions into images.
- Text: help produce clearer or better-structured writing.
- Audio: generate music or speech, and clean up noisy sound.
- Video: create short video clips or improve video quality.
- Science and engineering: design molecules and materials, predict movement (like cars in traffic), or detect unusual patterns in data (like cyber-attacks or server problems).
- Healthcare: create realistic medical images to help train doctors or improve scans without exposing patient data.
New tricks and improvements people are trying
Researchers are:
- Speeding things up: reducing the number of steps so results come faster.
- Making edits easier: letting users guide the model with sketches, text, or example layouts.
- Cleaning images better: removing blur, fixing low-light photos, and restoring compressed images.
- Controlling content: steering the model away from unwanted outputs or towards specific styles and details.
- Using them beyond images: forecasting anomalies in cloud systems, predicting motion, and more.
Common challenges
- Computation cost: they can be slow and require strong computers.
- Real-time use: hard to run instantly for video or live audio.
- Data needs: good results often require lots of quality data.
- Control and safety: avoiding harmful or biased content and preventing misuse.
- Long-term accuracy: predicting far into the future (like long traffic trajectories) is still tough.
Why does it matter?
Diffusion models are changing how we create and improve digital media. They can:
- Empower creativity: artists, designers, and students can create high-quality content with simple instructions.
- Boost science and medicine: generate realistic training data, enhance medical images, and help discover new materials.
- Improve technology: better speech tools, cleaner photos and videos, and smarter systems that detect problems before they happen.
The paper encourages future work on making these models:
- Faster and more efficient (so more people can use them on regular computers).
- Easier to control (so results match what users want).
- Safer and more ethical (so they’re used responsibly).
- Broader in scope (beyond images—into science, health, and everyday tools).
In short, diffusion models are like superpowered “cleaners” that can turn noise into something meaningful. They’re already great at art and media, and they’re starting to make a difference in health, safety, and science. This survey shows the big picture and points the way for what comes next.
Collections
Sign up for free to add this paper to one or more collections.