- The paper presents a novel e-commerce assistant, LLaSA, that leverages large language models to improve task generalization and efficiency.
- It introduces the EshopInstruct dataset and employs LoRA fine-tuning along with GPTQ quantization for resource-constrained deployment.
- Advanced prompting strategies like Chain-of-Thought reasoning enhance the model’s performance across multilingual and complex shopping tasks.
The paper "LLaSA: Large Language and E-Commerce Shopping Assistant" (2408.02006) presents a study on the development of a comprehensive e-commerce shopping assistant leveraging the capabilities of LLMs. The study proposes novel solutions for the challenges faced by existing shopping assistants in terms of task specificity and generalization.
Introduction
The researchers identify two primary issues with existing e-commerce shopping assistants: task-specificity and inadequate generalization. Task-specificity necessitates multiple models for different tasks, increasing development complexity and cost, while constrained generalization limits model performance when dealing with novel products or scenarios. To address these challenges, LLaSA aims to utilize the multi-tasking prowess of LLMs alongside custom datasets to create a more versatile shopping assistant.
The study's focus is the ShopBench, an Amazon-derived dataset, crafted for the Amazon KDD Cup 2024 Challenge. This challenge encompasses four shopping skills, distributed over five tracks: Shopping Concept Understanding, Shopping Knowledge Reasoning, User Behavior Alignment, and Multilingual Abilities, with LLaSA achieving a remarkable ranking in the competition.
Dataset Construction
The development and comprehensive utility of the EshopInstruct dataset form the cornerstone of this study. With 65,000 data points, EshopInstruct is instrumental for training models in domain-specific scenarios. The dataset construction involves three strategies:
- Data Generation from Seed Data: This involves generating additional data closely aligned with the types of tasks found in the challenge development set.
- External Data Integration: Utilizes available datasets such as ECInstruct [ecinstruct], Amazon-ESCI [ref:esci], and others to create a dataset rich in real-world applicability, helping integrate practical e-commerce knowledge into LLMs.
- New Task Design: Introduce novel task scenarios, which expand beyond existing datasets to cover unaddressed practical shopping tasks (Figure 1).
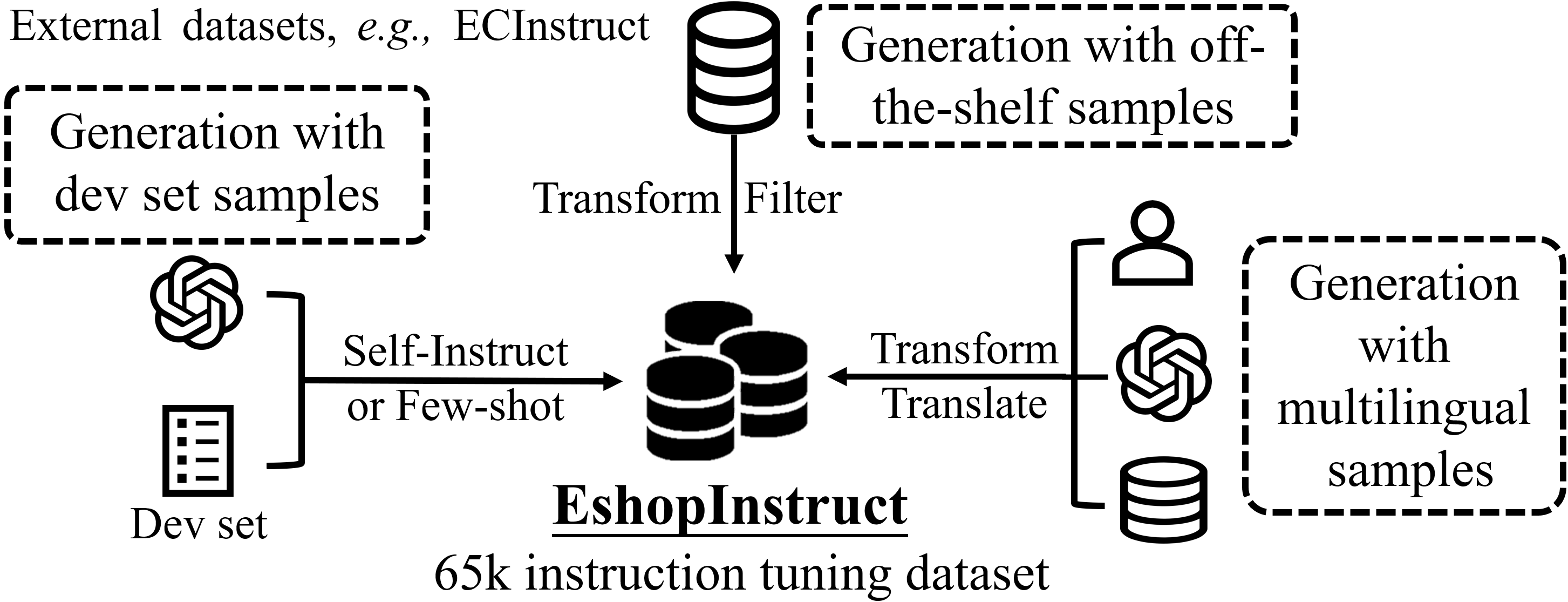
Figure 1: Construction pipeline of EshopInstruct depicting data generation strategies for creating a 65,000-point dataset.
Instruction Tuning
Instruction tuning is fundamental to augmenting LLMs with necessary e-commerce knowledge. LLaSA utilizes a novel approach with LoRA (Low-Rank Adaptation) fine-tuning to incorporate task-specific knowledge due to the limited domain-specific data available. This fine-tuning is carried out through auto-regressive language modeling. Qwen2-72B served as the foundational large model, further refined using GPTQ quantization for efficient deployment on resource-constrained systems.
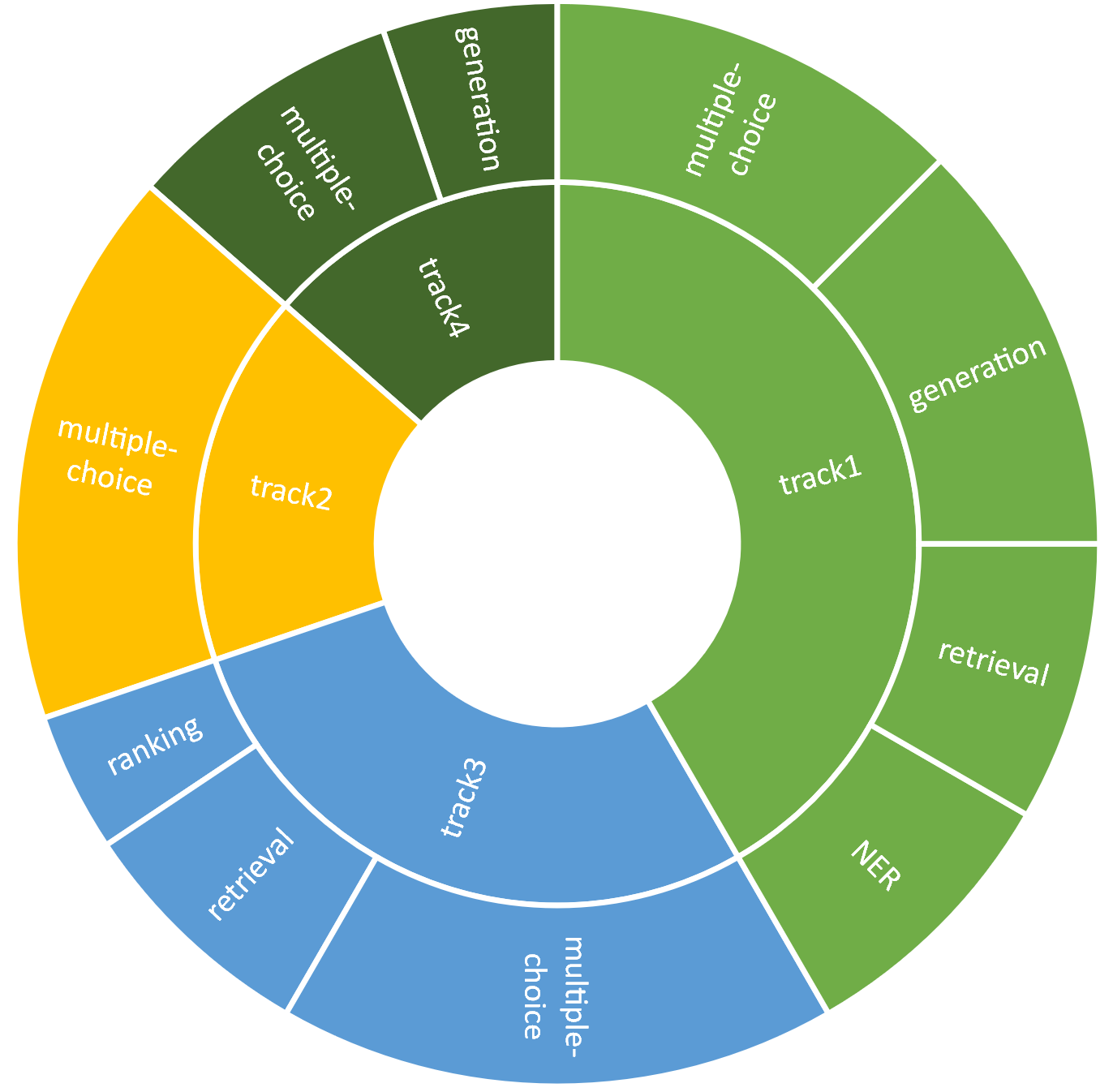
Figure 2: The data distribution of the development set, illustrating critical shopping skills and abilities used for training and evaluation.
Inference Framework
To tackle challenges in reasoning tasks often encountered in e-commerce shopping activities, LLaSA incorporates advanced prompting strategies such as Chain-of-Thought (CoT) reasoning and Re-Reading techniques. The inference framework is designed to run efficiently on limited resources, utilizing quantization strategies, specifically GPTQ, to enhance model performance without compromising computational integrity (Figure 3).
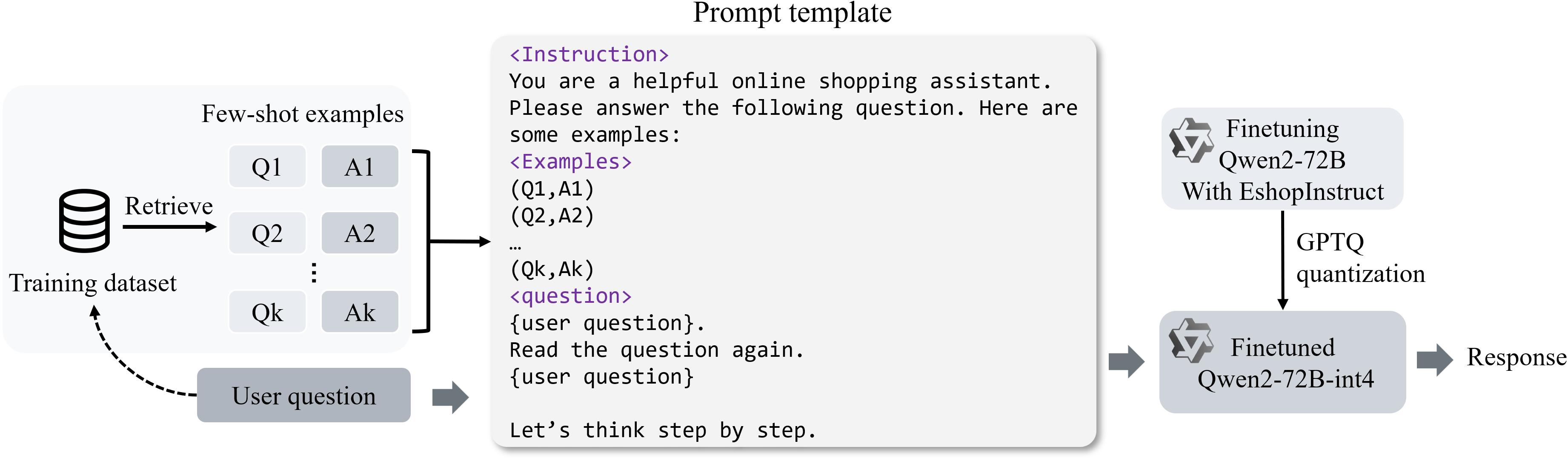
Figure 3: The overall inference framework, highlighting prompt construction techniques and quantization for optimized performance.
The experiments demonstrate that larger models like Qwen2-72B perform superiorly across multiple tasks, with Qwen2-72B fine-tuned using EshopInstruct outperforming other configurations significantly on all tracks (Table 1). Track-specific performance was notable, with competitive results across various shopping skills, particularly in multilingual abilities (Table 2).
(Table 1)
Table 1: Overall performance on different tracks with best results in boldface, underscore denotes second-best. Missing data due to unstable evaluation system denoted by '-'.
(Table 2)
Table 2: Best Model's Detailed Performance on task types for each track, with '-' denoting non-evaluated tasks.
Conclusion
The paper illustrates a comprehensive methodology for enhancing LLMs for e-commerce purposes. Through robust dataset construction and fine-tuning strategies, the solution brings forth an effective e-commerce assistant capable of understanding and responding to complex online shopping scenarios. The results offer a promising avenue for further integration of LLMs in practical commercial applications, emphasizing the need for continuous evolution in training data frameworks and resource optimization techniques.