- The paper introduces a systematic survey of specialized large language models, detailing their evolution from domain-adapted fine-tuning to domain-native and agent-oriented architectures.
- It highlights key innovations in dataset specialization, parameter-efficient training, and rigorous evaluation that drive superior performance on domain-specific benchmarks.
- Empirical results demonstrate that architectural and data specializations yield significant efficiency gains and improved accuracy compared to general-purpose models.
Survey of Specialized LLMs: Technical Progression and Implications
Introduction
The surveyed work provides a comprehensive analysis of the evolution, architecture, and deployment of specialized LLMs across professional domains such as healthcare, finance, law, mathematics, and industry. The paper delineates the transition from early domain-adapted models to domain-native architectures and agent-oriented systems, emphasizing the technical innovations that have enabled specialized LLMs to consistently outperform general-purpose models on domain-specific benchmarks. The survey also addresses the challenges of knowledge freshness, evaluation rigor, and ethical deployment, while outlining future directions for the field.
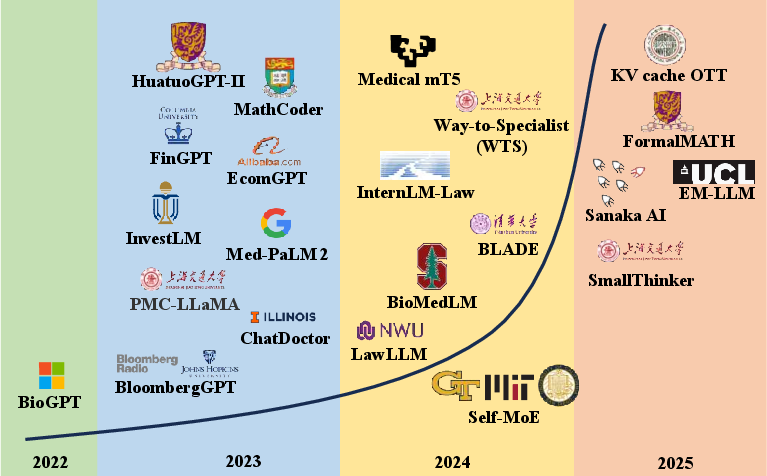
Figure 1: Evolution of representative specialized LLMs (2022–2025), highlighting the shift from early domain fine-tuning (BioGPT) to domain-native architectures (Med-PaLM 2, BloombergGPT) and agent-oriented designs (GLM-4.5, KV-Cache OTT).
Evolution of Specialized LLMs
The development of specialized LLMs has proceeded through several distinct phases:
- Domain-adapted Fine-tuning: Early models such as BioGPT (347M parameters) leveraged continued pretraining on domain-specific corpora, achieving notable improvements in biomedical text generation and relation extraction.
- Domain-native Architectures: Subsequent models, including Med-PaLM 2 (340B parameters) and BloombergGPT (50B parameters), introduced architectural modifications such as clinical reasoning modules and financial time-series embeddings, enabling superior performance on professional benchmarks.
- Hybrid and Agent-oriented Systems: Recent advances feature hybrid systems that integrate LLMs with symbolic knowledge bases (e.g., BLADE) and dynamic adaptation mechanisms (e.g., Self-MoE), as well as agent-oriented models like GLM-4.5 and KV-Cache OTT, which emphasize parameter efficiency and autonomous reasoning.
This progression is visually summarized in (Figure 1), which contextualizes the rapid technical maturation of specialized LLMs.
Technical Innovations in Specialization
Dataset Specialization
The construction of high-quality, domain-aligned datasets has been pivotal. Techniques such as Self-Instruct and Evol-Instruct have enabled the expansion of seed tasks into large-scale, diverse instruction–response pairs, with veracity-centric filtering (e.g., MedInstruct-200k) ensuring high specificity and domain relevance. Multimodal datasets (e.g., GeoVQA, mPLUG-DocOwl2, ProtST) have facilitated fine-grained alignment between symbolic and sensory modalities, driving gains in specialized LLM performance.
Training Architecture Specialization
Architectural advances have focused on parameter efficiency, sparsity, and reasoning depth:
- Parameter-efficient Fine-tuning: Mixture-of-LoRAs and HyperLoRA enable dynamic expert selection and continual domain addition with minimal parameter overhead, preserving high F1 scores while reducing memory requirements.
- Sparse Mixture-of-Experts (MoE): Expert Choice Routing and DeepSpeed-MoE optimize routing and training efficiency, achieving near-linear scaling and substantial reductions in training cost for trillion-parameter models.
- Compression and Quantization: Methods such as SpQR and SliceGPT exploit the skewed singular-value spectrum of expert weights, enabling near-lossless compression and significant memory savings with minimal impact on downstream performance.
- Reasoning Depth: System-2-Attention and mixture-of-vision-expert adapters introduce explicit modules for intermediate reasoning, yielding substantial improvements on complex benchmarks (e.g., +14.7% on GSM8K).
Evaluation Standard Specialization
Evaluation methodologies have evolved to incorporate multidimensional, adversarial, and efficiency-aware metrics. Benchmarks such as MedBench and HumanEval (pass@k) provide rigorous assessments of diagnostic accuracy, safety, and functional correctness. Perplexity (PPL) has emerged as a sensitive, zero-cost indicator of next-token uncertainty and alignment, correlating strongly with downstream task performance.
Retrieval-augmented LLMs (e.g., In-Context RALM, RA-DIT) integrate differentiable retriever–reader pipelines, enabling dynamic knowledge injection at inference time and achieving state-of-the-art results with reduced parameter counts. Tool-use specialization has progressed from prompt engineering to learned, constrained decoding (e.g., Toolformer, Gorilla), supporting robust API interaction and reducing hallucinated outputs.
Memory Specialization
Memory architectures such as mem0 and Memory3 decouple long-term memory storage from inference, enabling persistent, updatable embeddings and explicit memory tokenization. These approaches reduce latency, compress memory usage, and enhance long-form QA performance, supporting coherent, personalized agent interactions across sessions.
Empirical Results and Contradictory Claims
The survey highlights several strong empirical results:
- BioMedLM (2.7B) outperforms much larger general models on biomedical tasks, challenging the assumption that model size is the primary determinant of domain competence.
- KV-Cache OTT reduces memory usage by 70% during inference without significant loss in accuracy, demonstrating the efficacy of targeted optimization.
- System-2-Attention adds 14.7% to GSM8K performance via explicit reasoning modules, underscoring the value of architectural specialization for complex tasks.
- SpQR achieves near-lossless perplexity with 3.9× GPU memory reduction, validating the effectiveness of sparse–quantized representations in specialized settings.
These results collectively indicate that domain-specific architectural and data innovations can yield substantial gains over parameter scaling alone.
Implications and Future Directions
Practical Implications
Specialized LLMs have achieved sector-wide adoption, becoming standard tools in healthcare, finance, law, education, and industry. The survey notes a notable gap in e-commerce customer service, where general-purpose LLMs exhibit limited domain inclination. The authors recommend fine-tuning with high-quality, validated corpora and leveraging efficient frameworks (e.g., Llama, Unsloth) for deployment, with evaluation via domain-specific benchmarks such as Ecom-Bench.
Theoretical Implications
The shift from adaptation to domain-native architectures and agent-based systems marks a significant theoretical development. The integration of modularity, structural sparsity, and dynamic knowledge updating mechanisms points toward a future in which LLMs are not only specialized but also self-evolving and multimodal.
Future Developments
Key anticipated directions include:
- Efficient and Lightweight Architectures: Further advances in quantization, sparsity, and dynamic inference will enable deployment on edge devices and in resource-constrained environments.
- Continual Learning and Knowledge Updating: Mechanisms for dynamic knowledge acquisition and self-optimization will be critical for maintaining relevance in rapidly evolving domains.
- Multimodal and Cross-domain Integration: Enhanced processing of diverse data types and improved transfer learning will support comprehensive domain intelligence.
- Interpretability and Safety: As specialized LLMs are deployed in high-stakes settings, transparency, reliability, and ethical alignment will become paramount.
- Agent-based Autonomy: The convergence of LLMs and agent systems will facilitate complex task execution and intelligent assistance in professional domains.
Conclusion
The surveyed work systematically documents the technical progression of specialized LLMs, from early domain adaptation to advanced, agent-oriented architectures. The analysis demonstrates that domain-specific innovations in data, architecture, and evaluation consistently yield superior performance over general-purpose models, particularly in knowledge-intensive and high-stakes applications. The field is poised for further advances in efficiency, adaptability, and trustworthiness, with significant implications for both industrial deployment and theoretical research in artificial intelligence.

