- The paper introduces Panacea, a specialized foundation model for enhancing clinical trial search, summarization, design, and recruitment.
- It employs innovative methods like TrialAlign for dataset integration and TrialInstruct for multi-task instruction tuning, achieving superior metrics.
- The model demonstrates high accuracy in trial design and patient matching, signaling significant potential for advancing clinical research operations.
Panacea: A Foundation Model for Clinical Trial Search, Summarization, Design, and Recruitment
The paper introduces Panacea, a foundation model specialized in clinical trials, aiming to optimize processes such as trial search, summarization, design, and recruitment. Unlike general-purpose LLMs, Panacea addresses multiple clinical trial tasks using a comprehensive dataset and fine-tuning techniques, demonstrating superior performance over existing models.
Overview of Panacea
Panacea acts as a unified tool for a range of tasks associated with clinical trials, outperforming task-specific models by leveraging its domain specialization. The model is constructed using a framework that includes TrialAlign for vocabulary alignment and TrialInstruct for instruction tuning across multiple tasks.
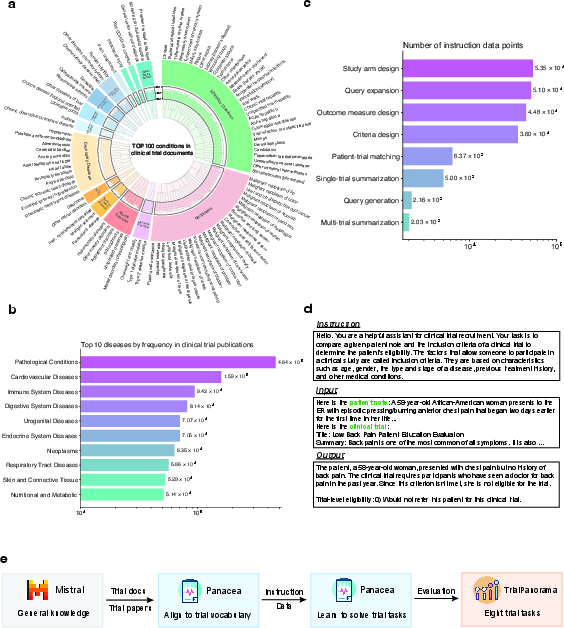
Figure 1: Overview of Panacea's datasets and training process.
TrialAlign incorporates 793,279 trial documents and 1,113,207 scientific papers, providing Panacea with an extensive resource base that encompasses a wide variety of conditions and treatments (Figure 1a, b). TrialInstruct, on the other hand, facilitates task-specific instruction tuning across eight tasks, standardizing interaction through data points that specify task definitions and outputs (Figure 1c, d, e).
Clinical Trial Search
Panacea enhances trial search capability through improved query generation and expansion techniques. It transforms user inputs into structured queries, categorized by disease, intervention, phase, status, and study type, then expands these queries to include relevant terms. This optimization ensures comprehensive retrieval of relevant trials.
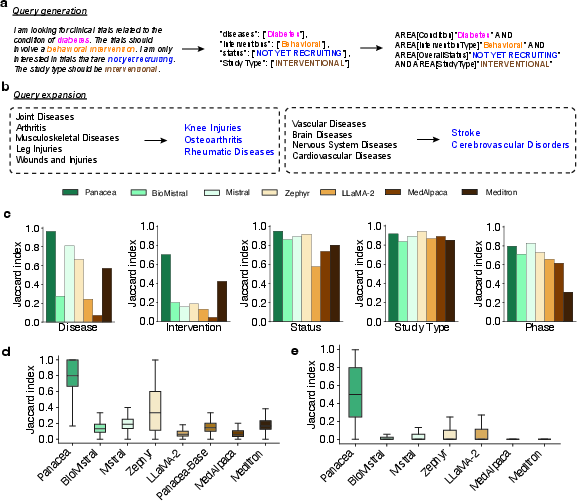
Figure 2: Evaluation metrics for query generation and expansion showcasing Panacea's effectiveness in trial search.
In experimental evaluations, Panacea outperformed existing models in query generation and expansion, as measured by Jaccard index improvements (Figure 2c, d, e).
Trial Summarization
Trial summarization is a critical capability, enabling the condensation of trial data into concise narrative summaries. Panacea's performance was benchmarked against several other models for both single-trial and multi-trial summarizations.
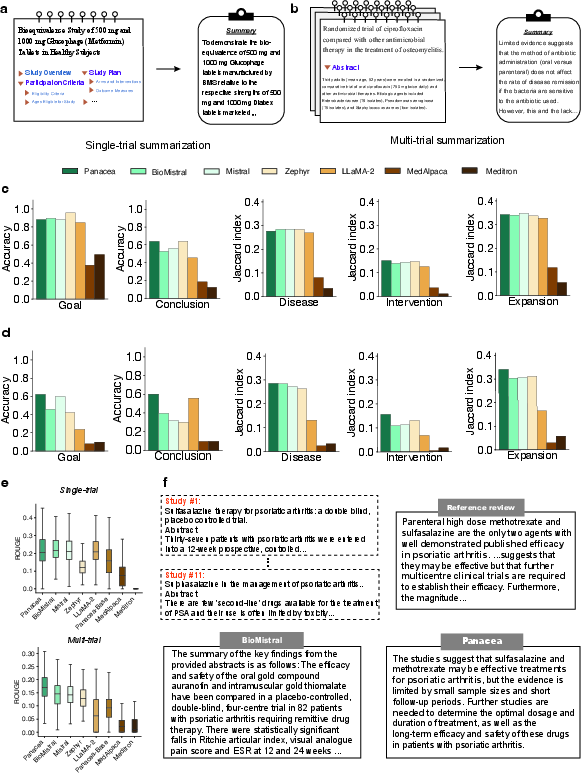
Figure 3: Summarization evaluation shows Panacea's ability in generating accurate trial summaries.
A novel evaluation metric based on LLMs was proposed to address limitations of lexical-based metrics, emphasizing Panacea's superior ability in summarizing both individual and multiple trials accurately, with enhanced performance in trial conclusion summarizations (Figure 3c, d, e, f).
Clinical Trial Design
Panacea supports trial design by generating eligibility criteria, study arms, and outcome measures. The model's design capabilities were validated using BLEU, ROUGE, and clinical relevance metrics to assess the natural language processing agreement and clinical accuracy of generated designs.
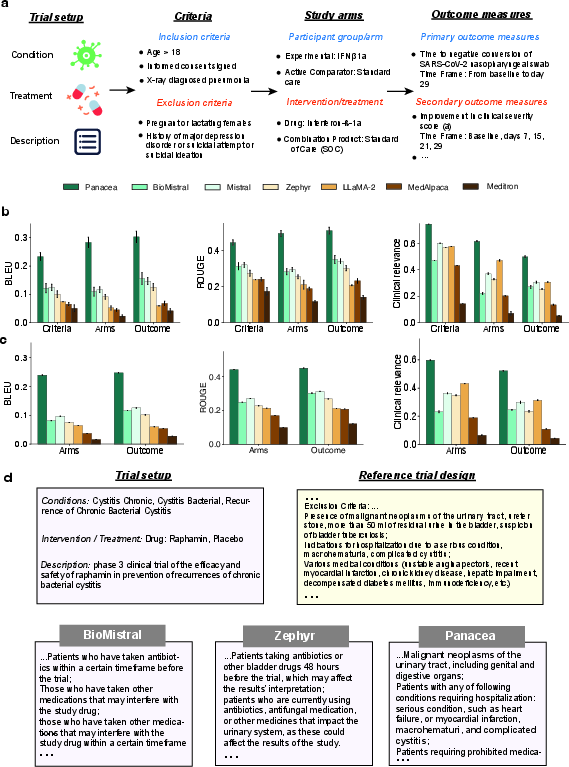
Figure 4: Panacea's trial design performance evaluated in terms of BLEU, ROUGE, and clinical relevance.
Enhanced design reliability was observed, with Panacea achieving leading scores across various design tasks and demonstrating the potential to automate design generation efficiently by adapting its outputs based on previous step designs (Figure 4b, c, d).
Patient-Trial Matching
Panacea improves patient-trial matching by classifying patients based on trial descriptions and notes, using a three-class classification method. This enhances patient recruitment by accurately determining trial eligibility.
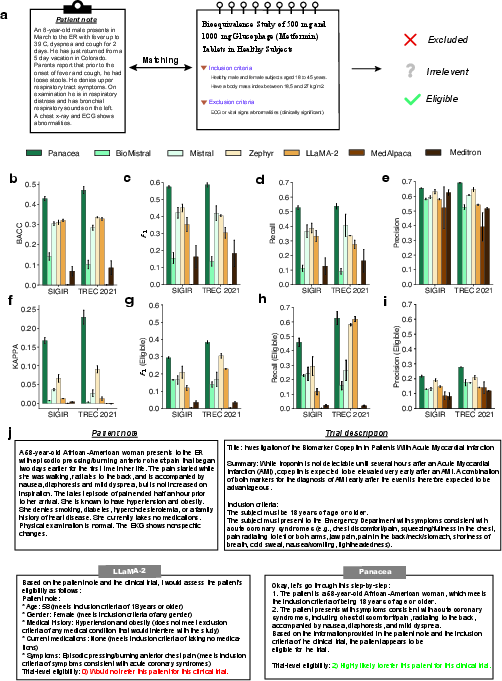
Figure 5: Comparative analysis on patient-trial matching highlights Panacea's superior classification accuracy.
Panacea achieved top performance metrics such as balanced accuracy, Cohen's KAPPA, recall, precision, and F1-score across datasets, indicating robust generalizability and precision in matching patients with appropriate trials (Figure 5b, f, h).
Discussion
Panacea marks a significant step in optimizing AI applications for clinical trials. By integrating clinical knowledge through extensive datasets and finely tailoring instruction data, Panacea establishes itself as a comprehensive tool for trial-related tasks. Future directions include enhancing model alignment, mitigating hallucination risks, and developing robust evaluation metrics. Moreover, Panacea's open-source resources pave the way for further development and adaptation in AI-driven clinical research.
Conclusion
Panacea effectively bridges the gap between generalized LLMs and the specialized needs of clinical trials. By excelling in tasks from trial search to patient matching, Panacea demonstrates the potential of clinical trial foundation models in improving the efficiency and accuracy of clinical research operations. This model serves as a promising foundation for ongoing advancements and applications in the intersection of AI and healthcare.