- The paper introduces DiffMa, a diffusion model using a State-Space Mamba to improve CT to MRI conversion.
- Utilizing Spiral-Scan and soft masking, the model preserves spatial continuity and emphasizes critical tissue details.
- Experimental results on the SynthRAD2023 dataset show superior SSIM performance compared to CNN, ViT, and similar models.
Soft Masked Mamba Diffusion Model for CT to MRI Conversion
The paper "Soft Masked Mamba Diffusion Model for CT to MRI Conversion" (2406.15910) introduces an innovative framework focused on improving the conversion of CT images to MRI using a diffusion model named Diffusion Mamba (DiffMa). This framework employs a State-Space Model (SSM) termed Mamba, enhancing efficiency in generating high-fidelity MRI images from CT scans. The model addresses limitations like spatial continuity and cross-sequence attention, pivotal for medical imaging tasks.
Diffusion Mamba Framework
DiffMa replaces traditional CNN and ViT backbones with the Mamba model, leveraging linear computational efficiency and a global receptive field. The introduction of the Spiral-Scan and soft masking mechanisms allows this model to better preserve spatial continuity and focus on significant patches, essential in MRI generation where capturing intricate details is crucial.
DiffMa proves superior in handling 2D spatial inputs through its Spiral-Scan approach, maintaining the continuity of scanned sequences. The framework integrates Mamba with a soft mask module, incorporating Cross-Sequence Attention, which further refines the focus on critical tissue areas for CT to MRI conversion.
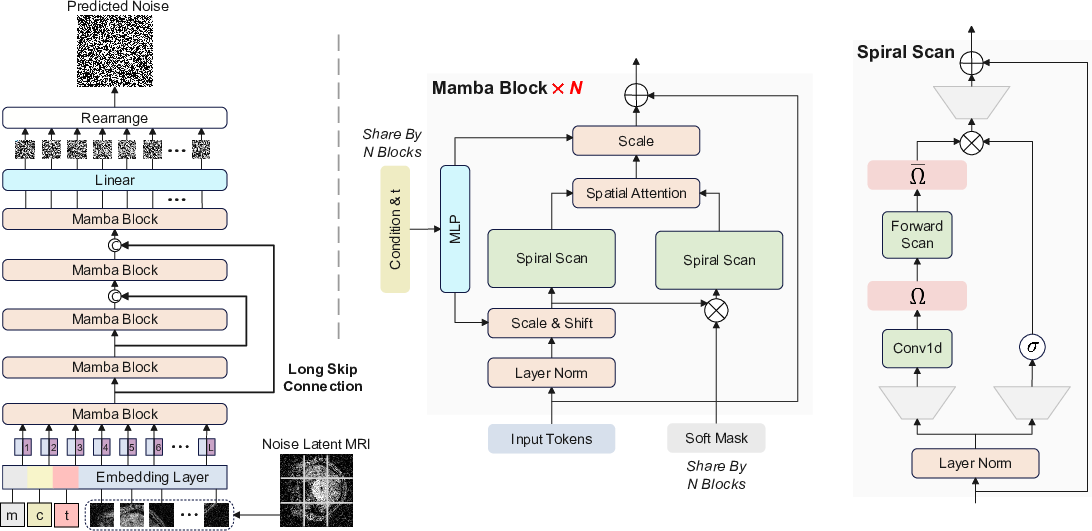
Figure 1: The Diffusion Mamba (DiffMa) framework. Left: The overall framework of Diffusion. Middle: Details of Mamba blocks. Right: Details of Mamba with Spiral-Scan.
Key Components
Spiral-Scan Mechanism
The Spiral-Scan strategy allows Mamba to manage spatial inputs effectively by maintaining spatial continuity during the sequence scan. This mechanism prevents disruption of spatial integrity when handling 2D patches, thus enhancing the model's ability to generate highly detailed MRI images.

Figure 2: The 2D Image Spiral-Scan. Eight schemes are employed to maintain structural information continuity.
Soft Mask with Vision Embedder
DiffMa incorporates a soft mask facilitated by a Vision Embedder, which produces token-level weights to prioritize patches vital for MRI generation. This component bridges the gap by focusing on the cross-sequence variation, allowing the model to emphasize more critical areas, thereby refining the image quality output.
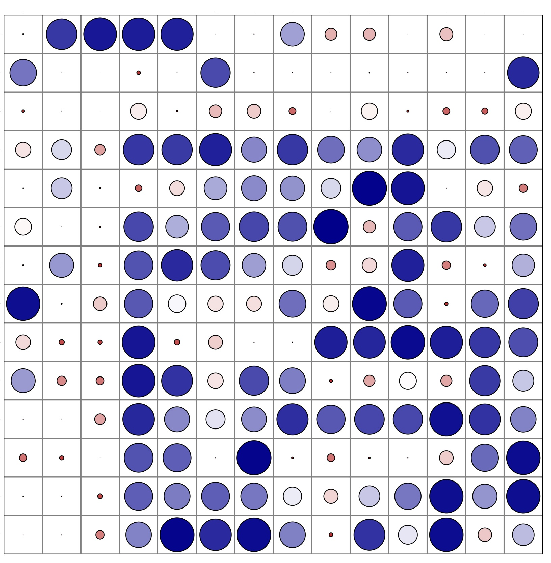
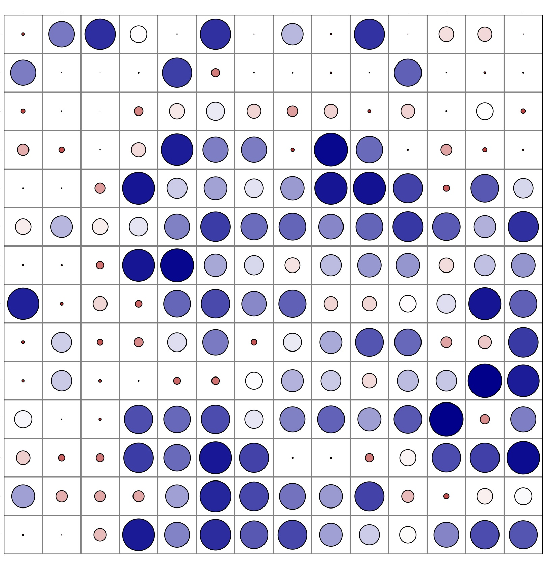
Figure 3: Visualization of patch significance from latent pelvic images indicating importance through circle size and darkness.
Computational Efficiency
By using SSMs, specifically the Mamba model, DiffMa achieves a linear complexity conducive to processing long sequences efficiently. In contrast with architectures based on CNNs and ViTs, DiffMa maintains a manageable computational overhead while retaining a global understanding, beneficial for producing high-quality medical images.
Experimental Results
The effectiveness of DiffMa was validated on the SynthRAD2023 dataset, focusing on converting CT to MRI for brain and pelvic scans. Compared to other models such as LDM, DiT, and various Mamba-based architectures, DiffMa demonstrated superior performance, particularly through SSIM metrics, highlighting its capability in maintaining structural integrity and detail.
(Figure 4 and Figure 5)
Figure 4: Visualizations of brain CT to MRI conversion. DiffMa outperformed in structural preservation.
Figure 5: Visualizations of pelvis CT to MRI conversion showcasing enhanced detail fidelity.
Conclusion
Diffusion Mamba represents a significant advancement in medical image synthesis, notably in CT to MRI conversion, by leveraging Mamba's efficient processing and innovative scan and attention mechanisms. Future directions may involve exploring more complex conditions and expanding the adaptability of the Mamba for diverse medical imaging tasks, potentially enhancing diagnostic methodologies through efficient, high-quality image generation.