- The paper proposes a transformer-based TTS system that integrates natural language emotion prompts with speaker embeddings to drive nuanced speech synthesis.
- It achieves high speaker similarity (cosine similarity near 1) and precise emotion transfer, validated through both objective metrics and subjective evaluations.
- The approach bypasses reliance on reference audio by utilizing textual prompts, paving the way for adaptive and expressive TTS applications.
Controlling Emotion in Text-to-Speech with Natural Language Prompts
Introduction
The paper "Controlling Emotion in Text-to-Speech with Natural Language Prompts" explores a novel approach to text-to-speech (TTS) synthesis that incorporates emotional cues directly from textual inputs. The authors propose a system that integrates natural language prompts, allowing for nuanced control over traditionally challenging prosodic aspects such as intonation and emotion. This is achieved by embedding emotional content from text alongside speaker identity within a transformer-based TTS architecture.
System Architecture and Approach
The proposed system uniquely employs embeddings derived from emotionally rich text snippets to condition speech synthesis outputs. A notable advancement in the architecture of this TTS system is the integration of both speaker and prompt embeddings into the model, which are combined at multiple points within the network to refine output control. Green components in the system architecture diagram signify the handling of these embeddings, while orange marks denote the associated loss functions, illustrating the areas of optimization within the system.
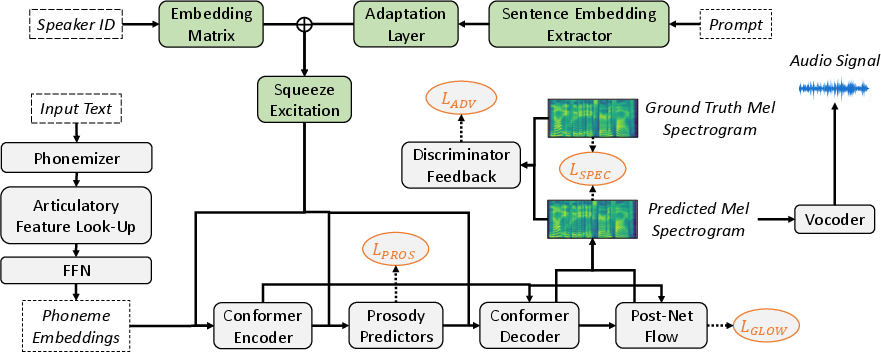
Figure 1: Architecture of the prompt conditioned TTS system. Green components handle the integration of speaker and prompt embedding. + indicates concatenation. The loss functions with which the components in this system are optimized are marked in orange.
This innovative utilization of natural language prompts bypasses the need for reference audio for style transfer, a limitation prevalent in previous approaches. Instead, emotional prompts derived from textual datasets guide the synthesis process, culminating in emotionally congruent speech outputs across diverse speaker identities.
Results and Evaluation
Extensive evaluations reveal that the use of prompt-conditioned embeddings facilitates precise emotion transfer in synthesized speech without compromising multi-speaker capabilities or speech quality. Objective measures of speaker similarity illustrate the system's ability to retain distinct speaker identities with high fidelity (cosine similarity close to 1), surpassing baseline systems.
In terms of emotional accuracy, the system exhibits substantial capabilities, aligning synthesized emotion labels closely with those intended by textual prompts. The effectiveness of this approach is visualized through emotional confusion matrices, indicating a strong correlation between predicted and underlying emotion labels.

Figure 2: Results of speech emotion recognition in terms of relative frequency for predicted emotion labels opposed to underlying ones. For Prompt Conditioned Same input text is the same as prompt while Prompt Conditioned Other uses different prompts. Emotion labels are abbreviated as follows: a(nger), j(oy), n(eutral), sa(dness), su(rprise).
Subjective evaluations further validate the system's performance, confirming high speech quality and naturalness, as rated on a 5-point mean opinion score scale. Additionally, participants acknowledge the accuracy of emotion transfer from prompts to synthesized speech, underscoring the practical significance of this method.
Implications and Future Prospects
The system sets a strong precedent in leveraging natural language prompts for nuanced emotion modulation in TTS systems, suggesting significant implications for enhancing user engagement in human-computer interactions and spoken dialogue systems. The demonstrated multi-speaker support and emotion transfer capabilities offer significant advantages for applications requiring diverse and expressive speech synthesis.
Future work could explore broader lexical styles and contexts outside predefined dialogue or storytelling datasets, potentially integrating real-time sentiment analysis to dynamically adjust synthesis outputs. Further exploration of zero-shot style transfer and adaptive learning in real-world applications could extend the scope and deployment of emotion-conditioned TTS systems, representing a vibrant area for ongoing research and development in AI-driven speech technologies.
Conclusion
In summary, the paper introduces a robust framework for emotional TTS synthesis through natural language prompting, achieving both practical and theoretical advancements in the field. The proposed architecture successfully combines speaker and emotional text embeddings to enable high-quality and emotionally accurate speech synthesis. With this groundwork laid, subsequent research could aim to address adaptive learning and style variability, bolstering the effectiveness and applicability of emotion-driven TTS systems in varied domains.