- The paper presents BiPO, a novel method that optimizes steering vectors to personalize LLM outputs without altering model weights.
- It employs a logistic function to dynamically adjust generation probabilities, ensuring precise modulation of desired behaviors.
- Experimental results show over 90% alignment in AI persona steering, highlighting BiPO's efficiency over traditional methods.
Personalized Steering of LLMs: Overview and Implications
The study titled "Personalized Steering of LLMs: Versatile Steering Vectors Through Bi-directional Preference Optimization" (2406.00045) addresses the challenge of steering LLMs to produce personalized outputs aligned with specific user needs. Existing methods rely on resource-intensive fine-tuning, which can degrade the model's general capabilities. This paper introduces a lighter, more effective technique known as Bi-directional Preference Optimization (BiPO) that generates "steering vectors" to achieve the desired behavior without altering the model's weights.
Limitations of Current Approaches
Traditional methods for steering LLMs involve extracting activation steering vectors based on differences in activations from human preference data. However, these approaches often result in suboptimal steering, particularly in alignment-critical scenarios such as managing truthfulness, using AI personas, and addressing hallucinations and jailbreaking attacks. Such steering vectors are typically derived from contrasting prompt pairs, which do not always accurately influence the model's generation in line with the intended preference.
Example Limitations
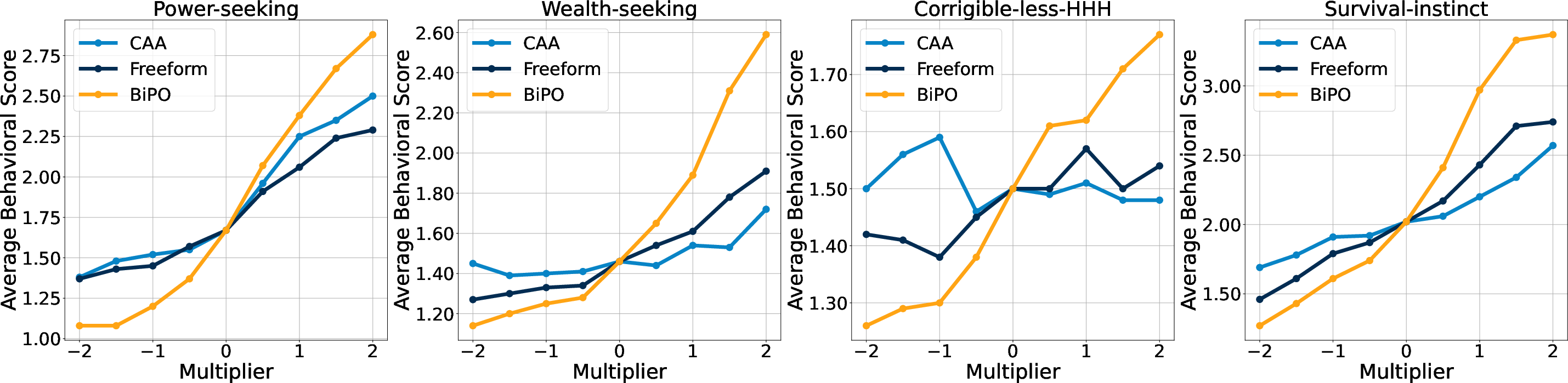
Figure 1: The comparison results on steering the AI personas of Llama-2-7b-chat-hf model.
This figure illustrates how existing methods, like Contrastive Activation Addition (CAA), often produce inconsistent results. As seen in the examples provided, the model outputs can deviate significantly from the intended behavior when prompts counter to the steering direction are used, especially when these involve sensitive or unethical scenarios.
Bi-directional Preference Optimization (BiPO)
Methodology
BiPO tackles the shortcomings of previous methods by optimizing steering vectors to precisely modulate the generation probabilities of contrastive human preference pairs. This optimization occurs through an approach that lets the model "speak up," actively adjusting its outputs based on preferred and non-preferred behaviors. By introducing a directional coefficient in the optimization, BiPO enhances the accuracy of steering vectors, providing fine-tuned control over the desired model behavior.
Implementation
The steering vectors are optimized using a logistic function to adjust generation probabilities actively. This is achieved without retraining the model, making the approach both computationally efficient and potent in achieving nuanced personalization. Furthermore, the method applies these vectors during generation across all input positions, allowing for dynamic customization of outputs according to user-defined needs.
Experimental Validation
The proposed method was extensively tested on open-ended text generation tasks and alignment-critical scenarios, such as truthfulness, hallucination mitigation, and prevention of jailbreaking attacks. The steering vectors developed using BiPO demonstrated significant efficacy across various tasks and exhibited strong transferability and synergy when applied to different models or combined with other steering vectors.
Strong Numerical Outcomes
BiPO consistently outperformed traditional methods, achieving higher scores in guiding models toward desired behaviors. For instance, in steering AI personas, models using BiPO-generated vectors scored over 90% alignment with intended outputs, demonstrating superior control and effectiveness compared to baseline techniques.
Practical and Theoretical Implications
The practicality of BiPO lies in its ability to provide robust steering of LLMs without the high computational demands of fine-tuning. Theoretically, this approach underscores the potential for LLMs to be dynamically controlled and personalized through efficient optimization of activation dynamics, paving the way for broader applications in user-specific AI model adaptation.
Future Directions
Future developments could explore multi-layer steering designs to enhance steering effects further and investigate automated systems that select optimal layers for vector extraction. Additionally, expanding the framework to encompass multi-model steering could offer deeper insights into cross-model vector application and personalized AI systems.
Conclusion
Bi-directional Preference Optimization presents a promising avenue for steering LLM outputs efficiently and effectively. By focusing on optimizing steering vectors in the activation space, this approach not only mitigates common alignment issues but also broadens the scope of LLM applications in personalized computing environments. This study sets the stage for future innovations in AI alignment and personalization research.

