Logic-Skill Programming: An Optimization-based Approach to Sequential Skill Planning
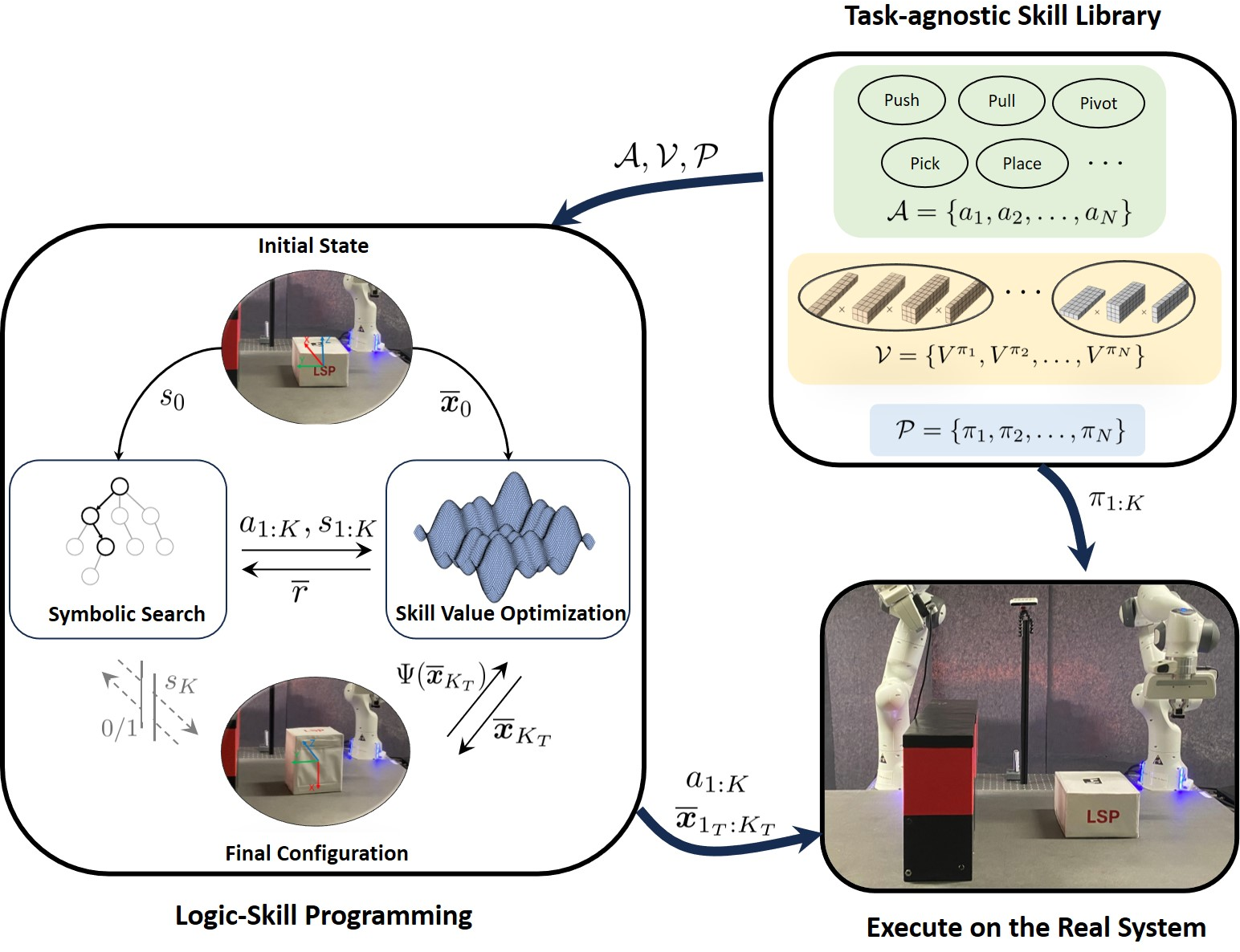
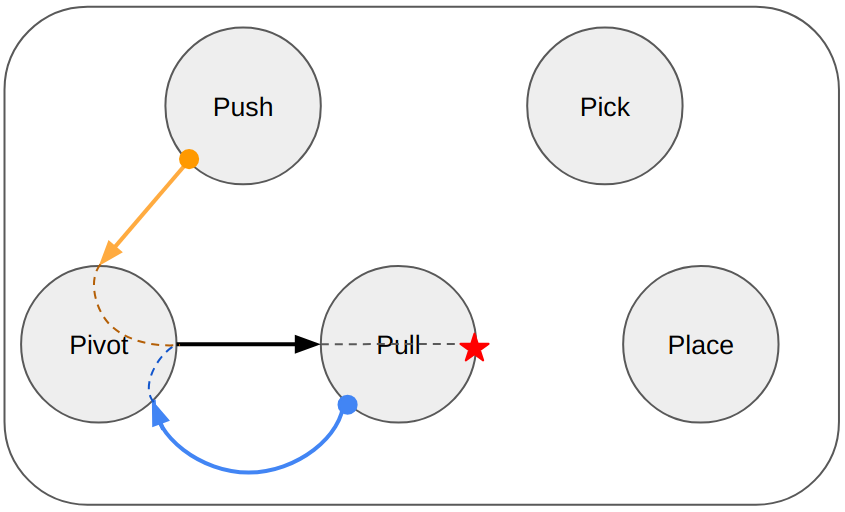
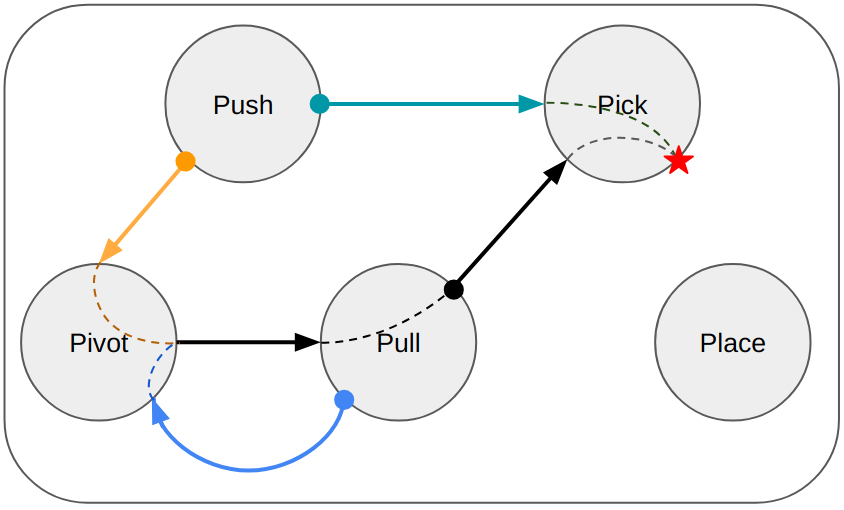
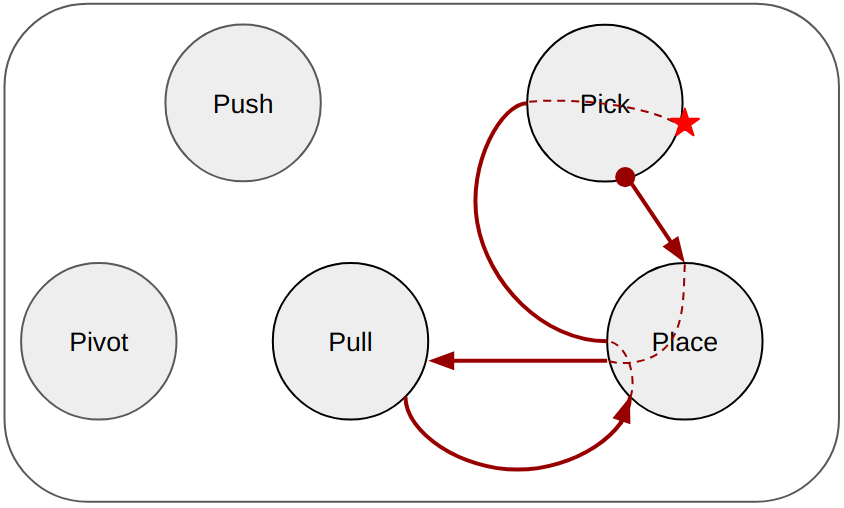
Abstract: Recent advances in robot skill learning have unlocked the potential to construct task-agnostic skill libraries, facilitating the seamless sequencing of multiple simple manipulation primitives (aka. skills) to tackle significantly more complex tasks. Nevertheless, determining the optimal sequence for independently learned skills remains an open problem, particularly when the objective is given solely in terms of the final geometric configuration rather than a symbolic goal. To address this challenge, we propose Logic-Skill Programming (LSP), an optimization-based approach that sequences independently learned skills to solve long-horizon tasks. We formulate a first-order extension of a mathematical program to optimize the overall cumulative reward of all skills within a plan, abstracted by the sum of value functions. To solve such programs, we leverage the use of tensor train factorization to construct the value function space, and rely on alternations between symbolic search and skill value optimization to find the appropriate skill skeleton and optimal subgoal sequence. Experimental results indicate that the obtained value functions provide a superior approximation of cumulative rewards compared to state-of-the-art reinforcement learning methods. Furthermore, we validate LSP in three manipulation domains, encompassing both prehensile and non-prehensile primitives. The results demonstrate its capability to identify the optimal solution over the full logic and geometric path. The real-robot experiments showcase the effectiveness of our approach to cope with contact uncertainty and external disturbances in the real world.
- Pddl— the planning domain definition language. Technical Report, Tech. Rep., 1998.
- Stap: Sequencing task-agnostic policies. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 7951–7958. IEEE, 2023.
- AIRobot. https://github.com/Improbable-AI/airobot, 2019.
- Diffusion policy: Visuomotor policy learning via action diffusion. arXiv preprint arXiv:2303.04137, 2023.
- Pybullet, a python module for physics simulation for games, robotics and machine learning. https://pybullet.org, 2016–2019.
- A tutorial on the cross-entropy method. Annals of operations research, 134:19–67, 2005.
- Implicit behavioral cloning. In Conference on Robot Learning, pages 158–168. PMLR, 2022.
- Pddlstream: Integrating symbolic planners and blackbox samplers via optimistic adaptive planning. In Proceedings of the International Conference on Automated Planning and Scheduling, volume 30, pages 440–448, 2020.
- Integrated task and motion planning. Annual review of control, robotics, and autonomous systems, 4:265–293, 2021.
- Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International conference on machine learning, pages 1861–1870. PMLR, 2018.
- Long-horizon multi-robot rearrangement planning for construction assembly. IEEE Transactions on Robotics, 39(1):239–252, 2022.
- Reactive planar non-prehensile manipulation with hybrid model predictive control. International Journal of Robotics Research (IJRR), 39(7):755–773, 2020.
- Continuous relaxation of symbolic planner for one-shot imitation learning. In 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2635–2642. IEEE, 2019.
- Mixed-integer formulations for optimal control of piecewise-affine systems. In Proceedings of the 22nd ACM International Conference on Hybrid Systems: Computation and Control, pages 230–239, 2019.
- Learning robust perceptive locomotion for quadrupedal robots in the wild. Science Robotics, 7(62):eabk2822, 2022.
- Generative skill chaining: Long-horizon skill planning with diffusion models. In Conference on Robot Learning, pages 2905–2925. PMLR, 2023.
- Non-prehensile planar manipulation via trajectory optimization with complementarity constraints. In 2022 International Conference on Robotics and Automation (ICRA), pages 970–976. IEEE, 2022.
- TT-cross approximation for multidimensional arrays. Linear Algebra and its Applications, 432(1):70–88, 2010.
- Ivan V Oseledets. Tensor-train decomposition. SIAM Journal on Scientific Computing, 33(5):2295–2317, 2011.
- Global planning for contact-rich manipulation via local smoothing of quasi-dynamic contact models. IEEE Transactions on Robotics, 2023.
- A direct method for trajectory optimization of rigid bodies through contact. International Journal of Robotics Research (IJRR), 33(1):69–81, 2014.
- Optimal Grasps and Placements for Task and Motion Planning in Clutter. In Proc. IEEE Intl Conf. on Robotics and Automation (ICRA), pages 3707–3713, 2023.
- Stable-Baselines3: Reliable Reinforcement Learning Implementations. Journal of Machine Learning Research, 22(268):1–8, 2021. URL http://jmlr.org/papers/v22/20-1364.html.
- Reuven Rubinstein. The cross-entropy method for combinatorial and continuous optimization. Methodology and computing in applied probability, 1:127–190, 1999.
- Fast adaptive interpolation of multi-dimensional arrays in tensor train format. The 2011 International Workshop on Multidimensional (nD) Systems, pages 1–8, 2011.
- Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Value Function Spaces: Skill-Centric State Abstractions for Long-Horizon Reasoning. In Proc. Intl Conf. on Learning Representations (ICLR), 2021.
- Tensor Trains for Global Optimization Problems in Robotics. International Journal of Robotics Research (IJRR), 2023.
- Generalized Policy Iteration using Tensor Approximation for Hybrid Control. In Proc. Intl Conf. on Learning Representations (ICLR), 2024.
- Combined task and motion planning through an extensible planner-independent interface layer. In 2014 IEEE international conference on robotics and automation (ICRA), pages 639–646. IEEE, 2014.
- Reinforcement learning: An introduction. MIT press, 2018.
- Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning. Artificial intelligence, 112(1-2):181–211, 1999.
- Marc Toussaint. Logic-geometric programming: an optimization-based approach to combined task and motion planning. In Proceedings of the 24th International Conference on Artificial Intelligence, pages 1930–1936, 2015.
- Differentiable Physics and Stable Modes for Tool-Use and Manipulation Planning. In Proc. of Robotics: Science and Systems (R:SS), 2018. Best Paper Award.
- Sequence-of-Constraints MPC: Reactive Timing-Optimal Control of Sequential Manipulation. In 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 13753–13760. IEEE, 2022.
- Brian C Williams. Cognitive Robotics: Monte Carlo Tree Search. Cambridge MA, 2016. MIT OpenCourseWare.
- Example-Driven Model-Based Reinforcement Learning for Solving Long-Horizon Visuomotor Tasks. In 5th Annual Conference on Robot Learning, 2021.
- Deep affordance foresight: Planning through what can be done in the future. In 2021 IEEE International Conference on Robotics and Automation (ICRA), pages 6206–6213. IEEE, 2021.
- Demonstration-guided optimal control for long-term non-prehensile planar manipulation. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 4999–5005. IEEE, 2023a.
- D-LGP: Dynamic Logic-Geometric Program for Combined Task and Motion Planning. arXiv preprint arXiv:2312.02731, 2023b.
- Sequence-based plan feasibility prediction for efficient task and motion planning. In Proc. Robotics: Science and Systems (R:SS), Daegu, Republic of Korea, July 2023.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.