- The paper introduces RPEST, a model integrating structural and textual embeddings to improve relation prediction in knowledge graphs.
- It employs Node2Vec for structural representations and Glove-driven bidirectional LSTM layers for efficient textual encoding.
- Experimental results on FB15K show a mean rank of 1.53 and Hits@1 of 74%, outperforming models like KG-BERT, TransR, and TransE.
Knowledge Graph Completion using Structural and Textual Embeddings
Introduction
The paper "Knowledge Graph Completion using Structural and Textual Embeddings" (2404.16206) addresses the persistent issue of incompleteness in Knowledge Graphs (KGs) by focusing on the Relation Prediction (RP) task. This task involves identifying valid relations between existing node pairs in a KG, which is crucial for enhancing applications such as question-answering and recommendation systems. The authors propose a novel model that integrates both structural and textual embeddings to improve the accuracy of the RP task, leveraging the strengths of walk-based embeddings and LLM embeddings.
Background
Knowledge Graphs, constructed from a set of triples (h,r,t), face the issue of incompleteness due to their vast and dynamic nature. While Link Prediction (LP) has been the focus of much research, the Relation Prediction task, which identifies possible relations between nodes, is equally significant. The paper identifies three categories of KGC models based on how they utilize KG data: structural information models, meta-information models, and hybrid models combining both. Previous approaches have often fallen short by optimally leveraging the combination of structural and textual data to enhance KG completion.
Methodology
The proposed model, RPEST, seeks to estimate the probability of each predefined relation in a KG using a unique combination of structural and textual embeddings.
- Structural Representation: This is achieved through Node2Vec, an unsupervised learning algorithm that crafts high-quality node representations by performing biased random walks, capturing the structural context of the nodes in the graph.
- Textual Representation: The model leverages pre-trained Glove embeddings, which offer efficient word-level text encodings that are then enhanced through bidirectional LSTM layers to provide contextualized node embeddings. This component omits the costly fine-tuning phase associated with Masked LLMs (MLMs).
The model architecture incorporates a neural prediction layer to integrate these representations, employing attention mechanisms and recurrent neural networks to fine-tune the interpretation of relation possibilities.
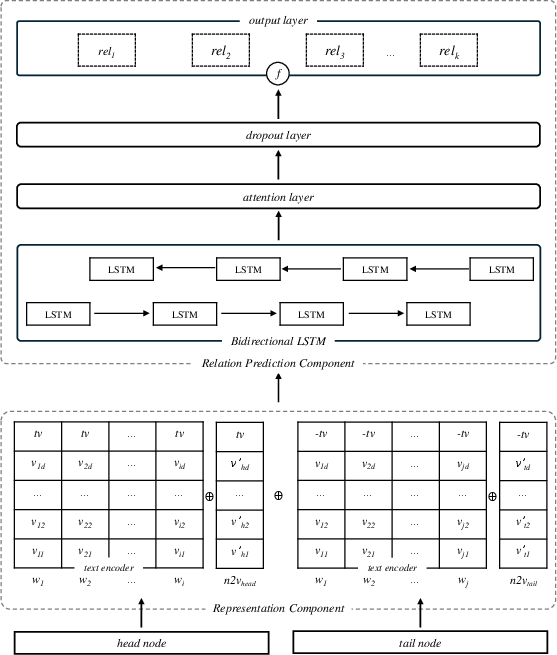
Figure 1: Our model's diagram showing the node representation component and the relations prediction component.
Experimental Setup and Results
Experiments were conducted on the Freebase dataset (FB15K), a well-regarded benchmark in the KG domain. The results against existing models demonstrate the effectiveness of incorporating both structural and textual inputs:
- Mean Rank: The model achieved a mean rank of 1.53, outperforming previous models such as KG-BERT that reported 1.69.
- Hits@1: With a score of 74%, the model demonstrated superior predictive precision, emphasizing its capability in exact relation prediction when compared to models like TransR and TransE.
The ablation study highlighted the contributions of each component. The structural embeddings vastly improved ranking results, while the textual embeddings from Glove offered notable consistency and computational efficiency compared to BERT-based approaches.
Implications and Future Work
The results underscore the pivotal role of integrating structural and textual information in KGC tasks. By avoiding the extensive computational demands of fine-tuning MLMs, the model presents a scalable solution for enhancing the utility of KGs in various applications. The approach could be explored further by integrating more sophisticated PLMs or alternative structural representation techniques. Enhancements could include the use of transformer-based architectures that could potentially capture more nuanced relationships in the data.
Conclusion
The study presented herein outlines a strategic innovation for relation prediction in KGs by synthesizing structural and textual embeddings. The approach not only advances the state-of-the-art in RP tasks but also posits a framework that is adaptable for future research addressing KG incompleteness. Building on this work could catalyze further developments in the field, particularly in resource-constrained environments where computational efficiency is critical.