- The paper introduces a training-free semantic segmentation method that uses GPT-3 to generate detailed subclass descriptors for improved feature differentiation.
- It employs techniques like attention weight calculation, upsampling, and CRF post-processing to refine segmentation outcomes without additional training.
- Results on COCO-Stuff and PASCAL datasets show enhanced accuracy, with a 5.1% improvement over baseline, demonstrating the method’s practical value.
Training-Free Semantic Segmentation via LLM-Supervision: An In-Depth Analysis
The paper "Training-Free Semantic Segmentation via LLM-Supervision" (2404.00701) introduces a novel approach to text-supervised semantic segmentation that leverages LLMs to refine class descriptors without requiring additional training. This method addresses a critical yet underexplored area in language-driven semantic segmentation by focusing on improving the accuracy and effectiveness of class descriptors. The core idea is to use LLMs to generate detailed subclass names for each class, thereby enhancing feature differentiation and enabling more precise pixel-level understanding.
Methodological Overview
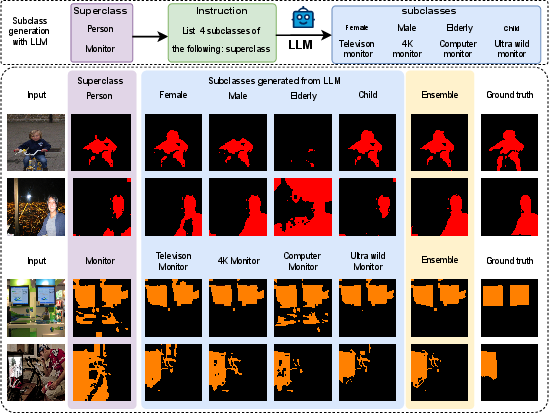
Figure 1: Overview of the proposed approach, highlighting the generation of subclasses using an LLM and subsequent refinement of segmentation results through ensembling.
The proposed approach, as illustrated in (Figure 1), consists of three main contributions. First, an LLM, specifically GPT-3, generates subclass names for each class to address the challenge of similar semantic features in traditional text-guided semantic segmentation. Second, an advanced text-supervised semantic segmentation method is implemented, using the generated subclass descriptors as target labels. Third, an ensembling technique is introduced to combine segmentation maps from different subclass descriptors with the original superclass representation.
Subclass Generation
The process begins with employing the GPT-3 model to automatically generate detailed subclasses, providing more informative and distinguishable features for each class. The prompt P1 is used to guide GPT-3 in generating subclasses for a given superclass name:
1
2
|
Q: List n subclasses of the following: {class-name}
A: Here are n commonly seen subclasses of {class-name}: |
To optimize performance, a few-shot adaptation is implemented using the prompt P2, which includes two examples of desired outputs:
1
2
3
4
5
6
|
Q1: List 3 subclasses of the person:
A1: female, male, child
Q2: List 3 subclasses of the boat:
A2: fishing boat, cruise ship, ship
Q: List n subclasses of the following: {class-name}
A: Here are n commonly seen subclasses of {class-name}: |
The number of generated subclass names n is set to 10, and an experiment examining the impact of varying the number of superclasses is included in the supplemental material.
Training-Free Semantic Segmentation
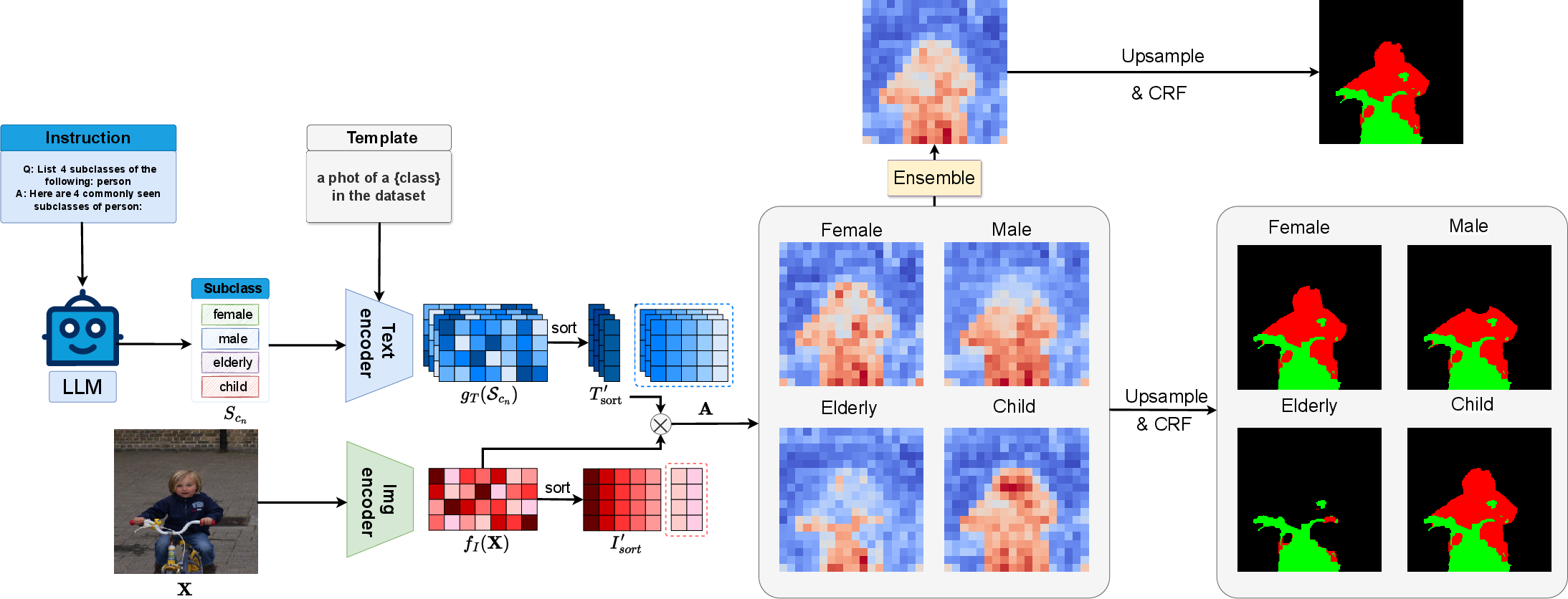
Figure 2: Training-free semantic segmentation via LLM supervision, detailing the process from LLM-generated subcategories to final prediction through similarity calculation, upsampling, and CRF refinement.
The generated subclasses are then applied to an advanced text-supervised semantic segmentation approach, leveraging SimSeg as the baseline. Each superclass label c is input into GPT-3 to generate a list of subclass sets Scn. The features of the generated subclasses are represented as [gT(Scn)]∈Rn×mt×d. The test image X is input into the image encoder to extract image features, denoted as fI(X)∈Rmi×d. The locality-driven alignment (LoDA) technique is adopted, and the textual features are arranged in descending order:
Tsort∈Rn×mt×d=sortd([gT(Scn)])
The attention weight A is calculated as:
A∈Rn×mi=[fI(X)]×Tsort′
Several post-processing steps are implemented, including upsampling and conditional random field (CRF), to achieve more accurate mask results without additional training.
Ensembling of Subclass Descriptors
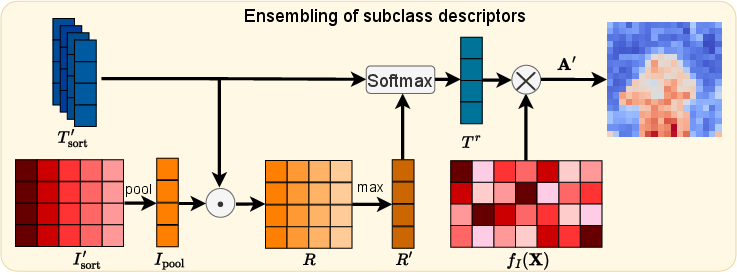
Figure 3: Ensembling of subclass descriptors, illustrating the integration of descriptors from different subclasses to achieve more accurate segmentation results.
To merge segmentation results from various subclasses, a subclass descriptor ensembling technique is proposed. The image features [fI(X)]∈Rmi×d undergo feature selection:
Isort∈Rmi×d=sortd([fI(X)])
Locally responsive features Isort′∈R5×d are selected, and an average pooling operation is applied. The relationship weights R∈Rn×d between the pooled image features Ipool∈Rd and the textual features Tsort′ are calculated:
R∈Rn×d=Ipool⋅Tsort′
The similarity between the textual features Tr and the image features [fI(X)] is calculated to obtain the final attention weights A′:
A′∈Rmi=[fI(X)]×Tr
Using A′, upsampling and CRF post-processing operations are performed to generate a more precise mask.
Experimental Results and Analysis
The method's efficacy is assessed using the COCO-Stuff and PASCAL datasets, with the primary metric being the mean Intersection over Union (mIoU). The results demonstrate that LLM supervision consistently improves performance across different datasets. For instance, on the PASCAL VOC dataset, the approach surpasses SimSeg by 5.1\%. Furthermore, using prompt P2 yields better results than P1, indicating that a few-shot sample approach can improve the generalization of the created subclasses. Visualizations of the segmentation outcomes highlight that LLM supervision captures more detailed information compared to superclass text-supervision.

Figure 4: Segmentation results with LLM-Supervision, showing more informative and precise segmentation outcomes compared to those achieved with superclass textual representations.
Ablation studies reveal that the effectiveness of LLM supervision varies among classes and is influenced by the quality of the generated subclasses. The approach achieves a 50.4\% score for the person superclass due to the distinct features of subclasses like male, female, and child. However, performance is lower for classes like sofa due to fewer distinct subclasses. The ensembling of subclass descriptors is shown to outperform other ensemble methods, ensuring comprehensive coverage and effective capture of diverse aspects within test images.
The impact of superclass importance within the ensemble method is evaluated by varying the weight λ given to the superclass textual representation. Results indicate that performance increases as λ decreases, with λ=0.2 yielding optimal performance. The weakest performance occurs at λ=1.0, highlighting the benefit of including some superclass representation.
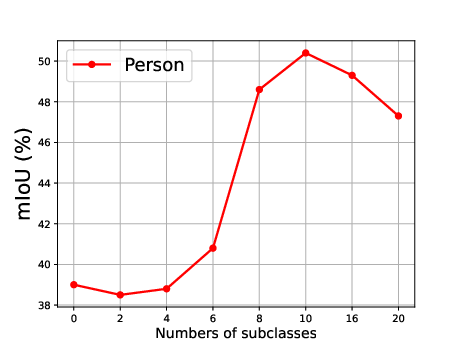
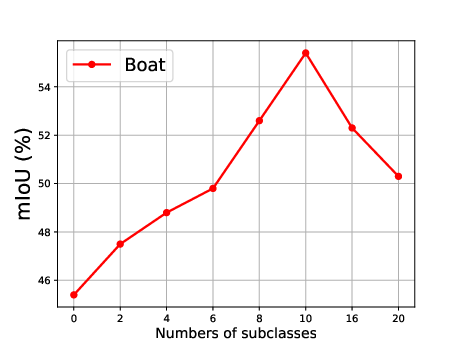
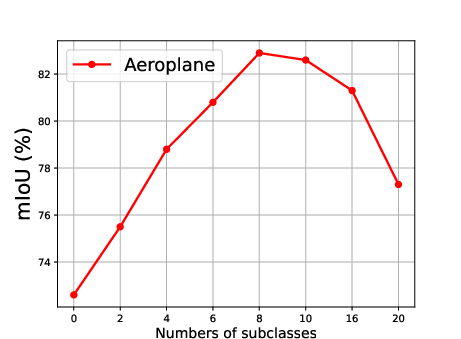
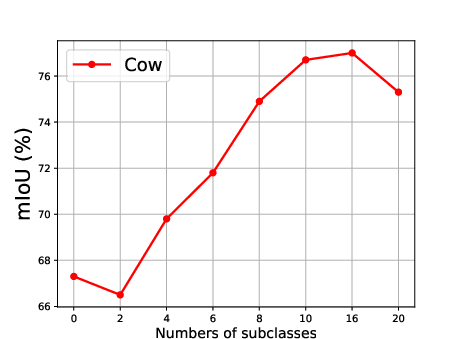
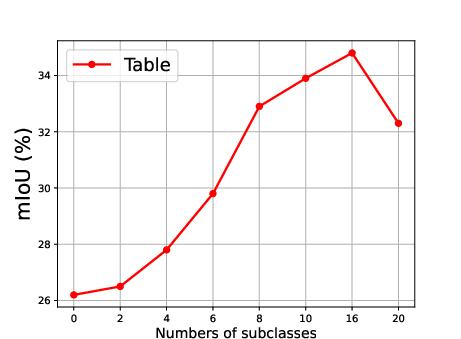
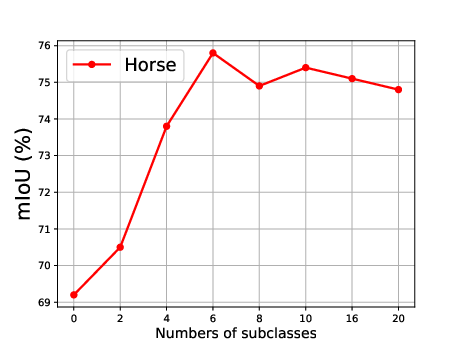
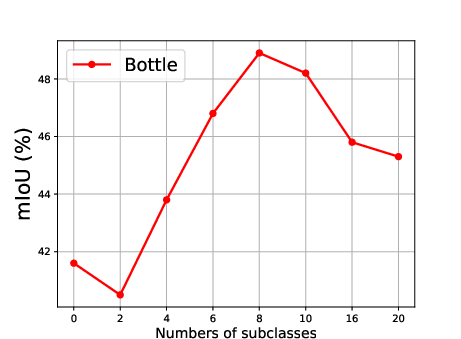

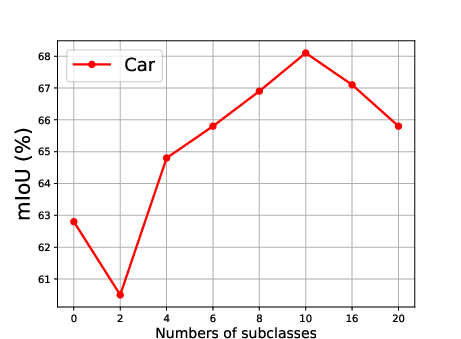
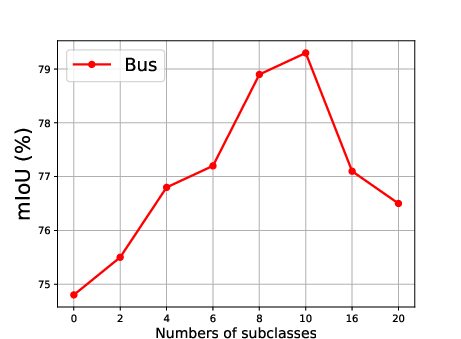
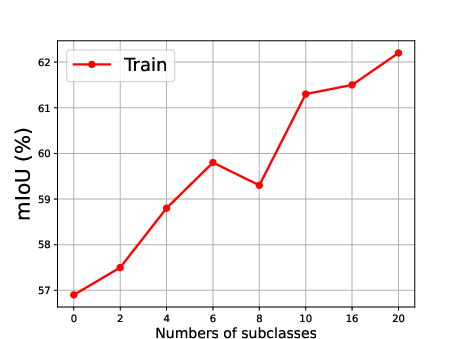
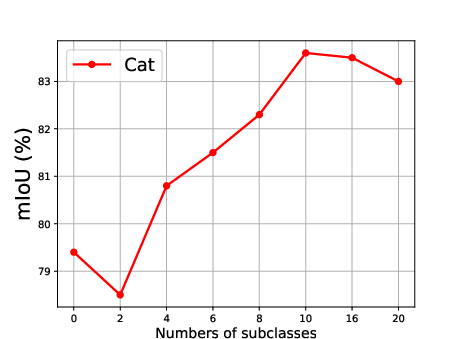
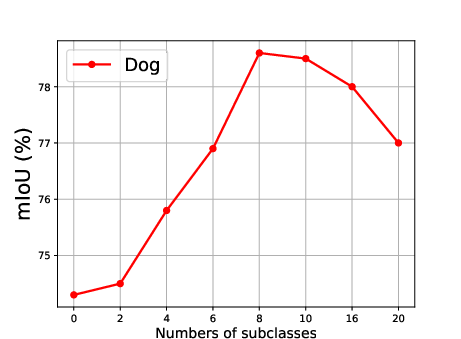
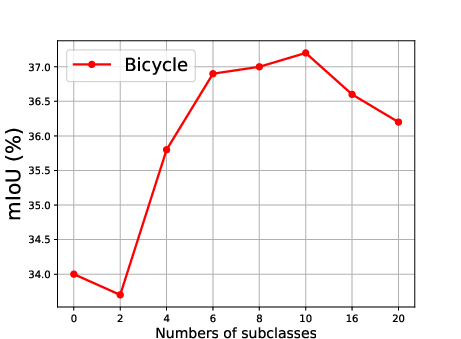
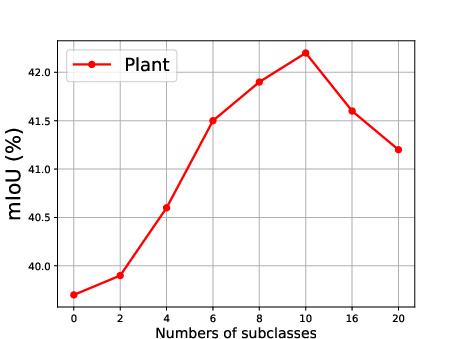
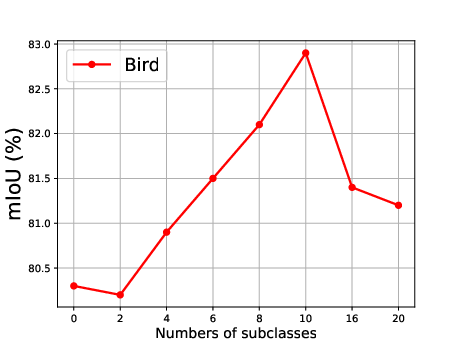
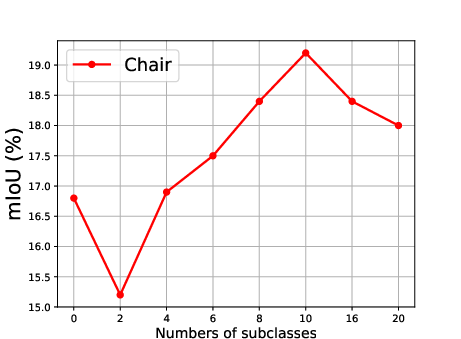
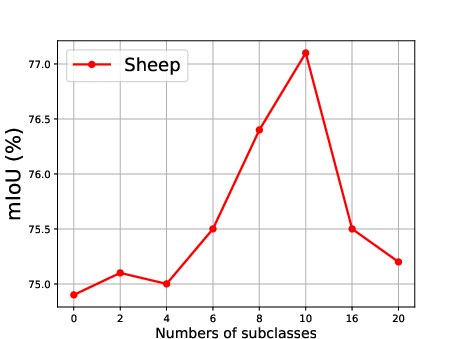
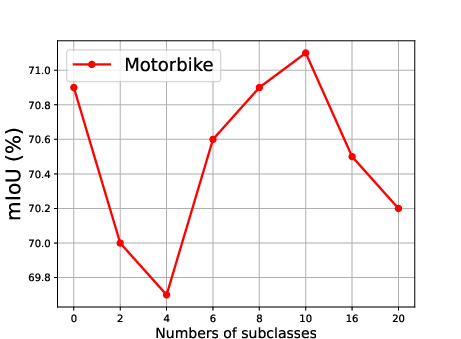
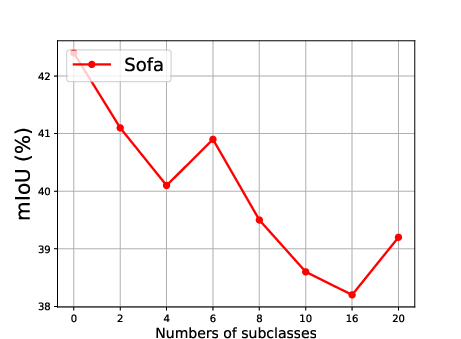
Figure 5: Effect of the number of generated subclasses for each superclass, showing the relationship between the number of subclasses and the mean Intersection over Union (mIoU).
The effect of generating different numbers of subclasses is also analyzed, revealing that segmentation accuracy improves steadily as the number of generated subclasses increases, reaching optimal precision when the number of generated subclasses is 10 (Figure 5).
Limitations and Future Directions

Figure 6: Failure case with LLM-supervision, indicating challenges in segmenting smaller objects and the efficacy of generated subclass representations.
The analysis reveals limitations in segmenting smaller objects and in the quality of generated subclass representations (Figure 6). For instance, the model fails to recognize smaller objects in images and cannot correctly segment certain classes due to limitations in subclass quality. Future work will focus on refining subclass quality and improving the model's generalization capabilities.
Conclusion
The paper presents a training-free semantic segmentation approach that leverages LLM supervision to generate detailed subclasses, enhancing class representation and improving segmentation accuracy. The adaptability, ease of integration, and effectiveness of the proposed method make it a valuable addition to existing zero-shot semantic segmentation frameworks. Comprehensive experiments and ablation studies demonstrate the method's ability to capture precise class-aware features and enhance generalization.