Gemma: Open Models Based on Gemini Research and Technology
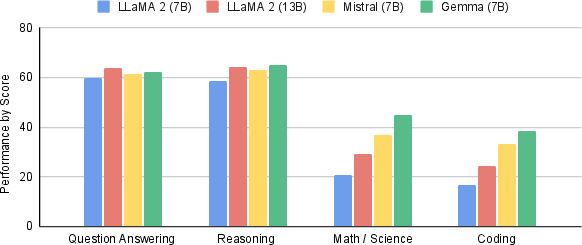
Abstract: This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
- The falcon series of open language models, 2023.
- Concrete problems in AI safety. arXiv preprint, 2016.
- Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023.
- Program synthesis with large language models. CoRR, abs/2108.07732, 2021. URL https://arxiv.org/abs/2108.07732.
- Constitutional ai: Harmlessness from ai feedback, 2022.
- Pathways: Asynchronous distributed dataflow for ml, 2022.
- PIQA: reasoning about physical commonsense in natural language. CoRR, abs/1911.11641, 2019. URL http://arxiv.org/abs/1911.11641.
- Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39, 1952.
- Quantifying memorization across neural language models. arXiv preprint arXiv:2202.07646, 2022.
- Evaluating large language models trained on code. CoRR, abs/2107.03374, 2021. URL https://arxiv.org/abs/2107.03374.
- Palm: Scaling language modeling with pathways, 2022.
- Deep reinforcement learning from human preferences. Advances in Neural Information Processing Systems, 30, 2017.
- Boolq: Exploring the surprising difficulty of natural yes/no questions. CoRR, abs/1905.10044, 2019. URL http://arxiv.org/abs/1905.10044.
- Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018.
- Training verifiers to solve math word problems. CoRR, abs/2110.14168, 2021. URL https://arxiv.org/abs/2110.14168.
- Large scale distributed deep networks. In F. Pereira, C. Burges, L. Bottou, and K. Weinberger, editors, Advances in Neural Information Processing Systems, volume 25. Curran Associates, Inc., 2012. URL https://proceedings.neurips.cc/paper_files/paper/2012/file/6aca97005c68f1206823815f66102863-Paper.pdf.
- BERT: pre-training of deep bidirectional transformers for language understanding. CoRR, abs/1810.04805, 2018. URL http://arxiv.org/abs/1810.04805.
- Gemini Team. Gemini: A family of highly capable multimodal models, 2023.
- Measuring massive multitask language understanding. CoRR, abs/2009.03300, 2020. URL https://arxiv.org/abs/2009.03300.
- Measuring mathematical problem solving with the math dataset. NeurIPS, 2021.
- Preventing verbatim memorization in language models gives a false sense of privacy. arXiv preprint arXiv:2210.17546, 2022.
- Mistral 7b, 2023.
- Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. CoRR, abs/1705.03551, 2017. URL http://arxiv.org/abs/1705.03551.
- How our principles helped define alphafold’s release, 2022.
- T. Kudo and J. Richardson. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In E. Blanco and W. Lu, editors, Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 66–71, Brussels, Belgium, Nov. 2018. Association for Computational Linguistics. 10.18653/v1/D18-2012. URL https://aclanthology.org/D18-2012.
- Madlad-400: A multilingual and document-level large audited dataset. arXiv preprint arXiv:2309.04662, 2023.
- Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:452–466, 2019. 10.1162/tacl_a_00276. URL https://aclanthology.org/Q19-1026.
- Deep learning. nature, 521(7553):436–444, 2015.
- Efficient estimation of word representations in vector space. In Y. Bengio and Y. LeCun, editors, 1st International Conference on Learning Representations, ICLR 2013, Scottsdale, Arizona, USA, May 2-4, 2013, Workshop Track Proceedings, 2013. URL http://arxiv.org/abs/1301.3781.
- Scalable extraction of training data from (production) language models. arXiv preprint arXiv:2311.17035, 2023.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35, 2022.
- How to catch an ai liar: Lie detection in black-box llms by asking unrelated questions, 2023.
- The LAMBADA dataset: Word prediction requiring a broad discourse context. CoRR, abs/1606.06031, 2016. URL http://arxiv.org/abs/1606.06031.
- Exploring the limits of transfer learning with a unified text-to-text transformer. CoRR, abs/1910.10683, 2019. URL http://arxiv.org/abs/1910.10683.
- Scaling up models and data with t5x and seqio, 2022.
- Scaling up models and data with t5x and seqio. Journal of Machine Learning Research, 24(377):1–8, 2023.
- WINOGRANDE: an adversarial winograd schema challenge at scale. CoRR, abs/1907.10641, 2019. URL http://arxiv.org/abs/1907.10641.
- Socialiqa: Commonsense reasoning about social interactions. CoRR, abs/1904.09728, 2019. URL http://arxiv.org/abs/1904.09728.
- N. Shazeer. Fast transformer decoding: One write-head is all you need. CoRR, abs/1911.02150, 2019. URL http://arxiv.org/abs/1911.02150.
- N. Shazeer. GLU variants improve transformer. CoRR, abs/2002.05202, 2020. URL https://arxiv.org/abs/2002.05202.
- Defining and characterizing reward gaming. In NeurIPS, 2022.
- Roformer: Enhanced transformer with rotary position embedding. CoRR, abs/2104.09864, 2021. URL https://arxiv.org/abs/2104.09864.
- Sequence to sequence learning with neural networks. CoRR, abs/1409.3215, 2014. URL http://arxiv.org/abs/1409.3215.
- Challenging big-bench tasks and whether chain-of-thought can solve them, 2022.
- Commonsenseqa: A question answering challenge targeting commonsense knowledge, 2019.
- Llama: Open and efficient foundation language models, 2023a.
- Llama 2: Open foundation and fine-tuned chat models, 2023b.
- Attention is all you need. CoRR, abs/1706.03762, 2017. URL http://arxiv.org/abs/1706.03762.
- Chain of thought prompting elicits reasoning in large language models. CoRR, abs/2201.11903, 2022. URL https://arxiv.org/abs/2201.11903.
- Ethical and social risks of harm from language models. CoRR, abs/2112.04359, 2021. URL https://arxiv.org/abs/2112.04359.
- R. J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8, 1992.
- XLA. Xla: Optimizing compiler for tensorflow, 2019. URL https://www.tensorflow.org/xla.
- GSPMD: general and scalable parallelization for ML computation graphs. CoRR, abs/2105.04663, 2021. URL https://arxiv.org/abs/2105.04663.
- B. Zhang and R. Sennrich. Root mean square layer normalization. CoRR, abs/1910.07467, 2019. URL http://arxiv.org/abs/1910.07467.
- Judging llm-as-a-judge with mt-bench and chatbot arena, 2023.
- Agieval: A human-centric benchmark for evaluating foundation models, 2023.
- Representation engineering: A top-down approach to ai transparency, 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.