- The paper presents DeepEval, a comprehensive benchmark framework to test LMMs in interpreting layered image semantics.
- It details a tripartite evaluation covering fine-grained description selection, title matching, and deep semantic understanding.
- Results reveal a significant gap between LMM performance and human interpretation, highlighting the need for improved model architectures.
Can Large Multimodal Models Uncover Deep Semantics Behind Images?
Introduction
The comprehension of deep semantics in images represents a formidable challenge in AI research, particularly given the superficial focus of many multimodal systems on individual image components rather than the underlying meanings. The paper "Can Large Multimodal Models Uncover Deep Semantics Behind Images?" introduces a new benchmark framework, DeepEval, designed to evaluate the proficiency of Large Multimodal Models (LMMs) in understanding the deeper semantics of visual content beyond their surface-level attributes. The introduction of DeepEval marks a significant step towards progressing LMMs beyond basic descriptive tasks to more sophisticated semantic interpretation.
DeepEval Dataset and Benchmark
DeepEval serves as a comprehensive dataset paired with three subtasks aimed at dissecting multiple layers of semantic understanding:
- Fine-grained Description Selection - Evaluates LMMs' ability to pick the most accurate surface-level description among alternatives.
- In-depth Title Matching - Tests the models' capability to match images with appropriate titles that capture the broader context.
- Deep Semantics Understanding - Assesses how well models grasp the profound semantic layers within images.
The dataset is human-annotated and incorporates multiple-choice questions derived from cartoons that inherently demand recognition of subtleties such as humor, satire, and philosophical messages.

Figure 1: An example from the DeepEval dataset includes annotated description, annotated title, and the corresponding multiple-choice question for deep semantics from the deep semantics understanding task.
Methodology
The construction of the DeepEval dataset involved rigorous processes such as image collection, annotation, and option generation. Each cartoon image is annotated with detailed descriptions, titles, and connotations, ensuring the dataset covers diverse semantic categories—humorous, critical, touching, philosophical, inspiring, and satirical.
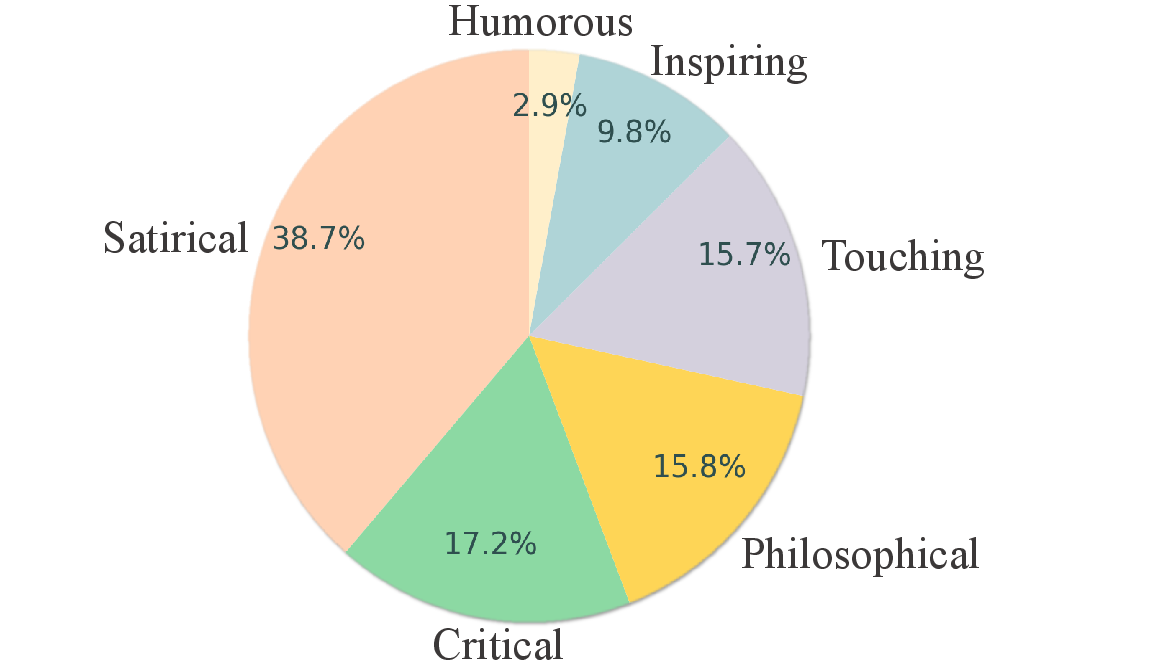
Figure 2: The distribution of six categories of DeepEval dataset.
LMMs were evaluated to identify their relative strengths across different semantic categories. Models like GPT-4V and several open-source competitors were benchmarked, providing insights into their capabilities and deficiencies compared with human interpretation.
Results
The evaluation results illustrate a significant disparity between human semantic understanding and that of even the most advanced LMMs, such as GPT-4V. While models generally perform well in surface-level description tasks, their accuracy notably declines in tasks requiring deeper semantic interpretation.
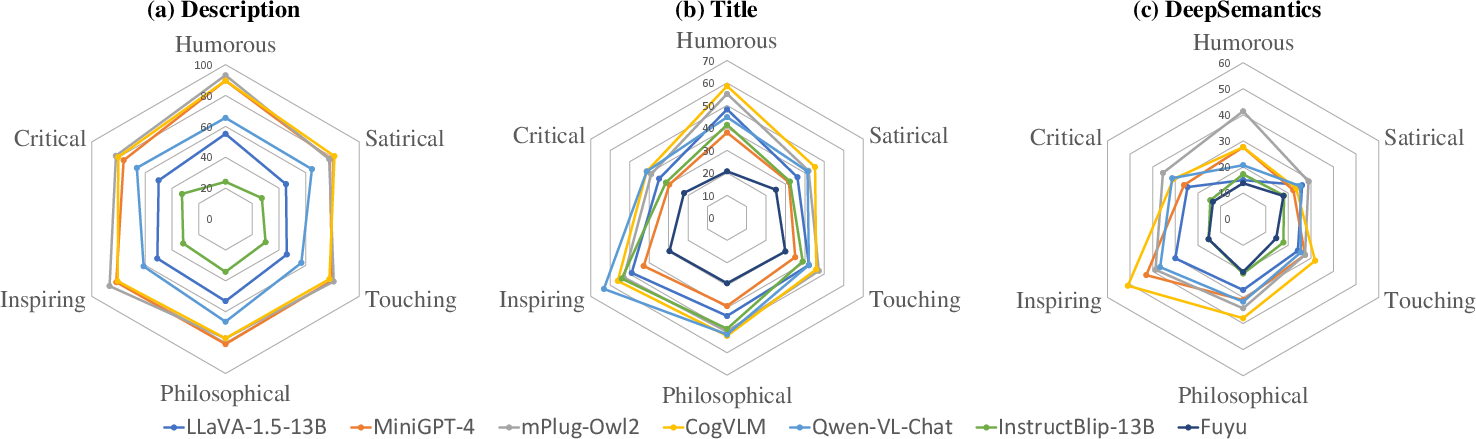
Figure 3: The radar charts represent the performance of several typical models in understanding images across different categories in our three tasks.
A specific focus was placed on the ability of models to benefit from additional descriptive context during inference. The inclusion of detailed surface-level descriptions was shown to improve the comprehension of deep semantics, though the enhancement was modest, indicating room for further advancements in model training methods and architectures.
Trade-offs and Implementation Considerations
The paper highlights a trade-off between model size and performance, reaffirming that larger models tend to demonstrate superior performance, albeit with greater computational requirements and potentially increased inference times. However, even large models like GPT-4V indicate variability in performance across semantic categories, suggesting that size alone is insufficient for achieving human-like proficiency.
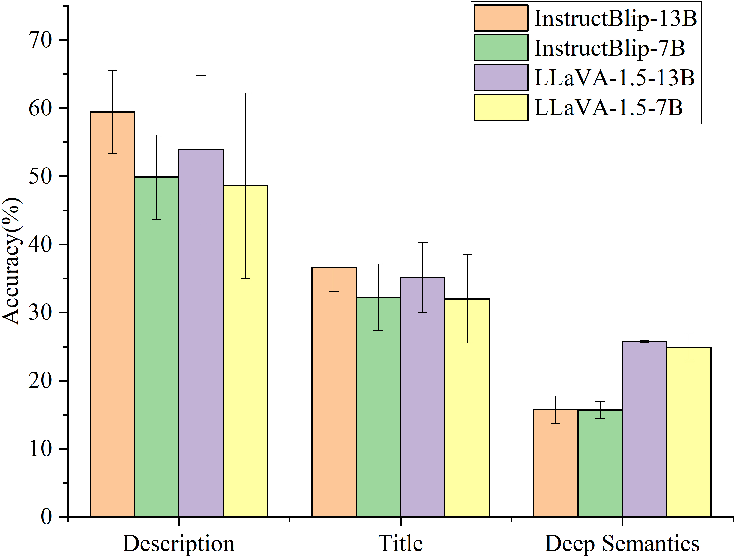
Figure 4: Comparison of the average accuracy and variance results between InstructBlip-13B vs InstructBlip-7B and LLaVA-1.5-13B vs LLaVA-1.5-7B.
Conclusion
This research emphasizes the inadequacy of current LMMs to fully capture and reproduce the deep semantics in visual content at a level comparable to humans. It opens avenues for future work to focus on improving model architectures and training methodologies that leverage extended context and nuanced understanding. As models continue to scale and integrate more sophisticated training paradigms, they may close the existing performance gap in deep semantic understanding, ultimately bringing AI closer to genuine perceptual intelligence. The DeepEval benchmark stands as a crucial tool for measuring progress in this domain, providing a structured means to challenge and refine LMM capabilities.