Mirror Gradient: Towards Robust Multimodal Recommender Systems via Exploring Flat Local Minima
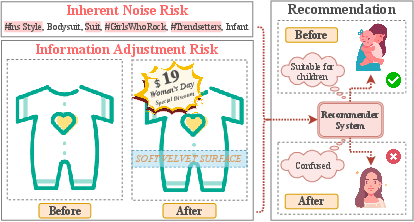
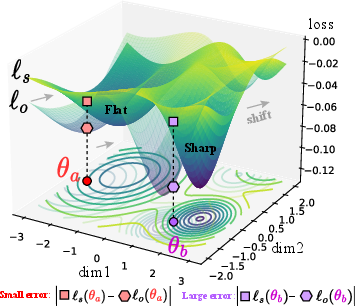
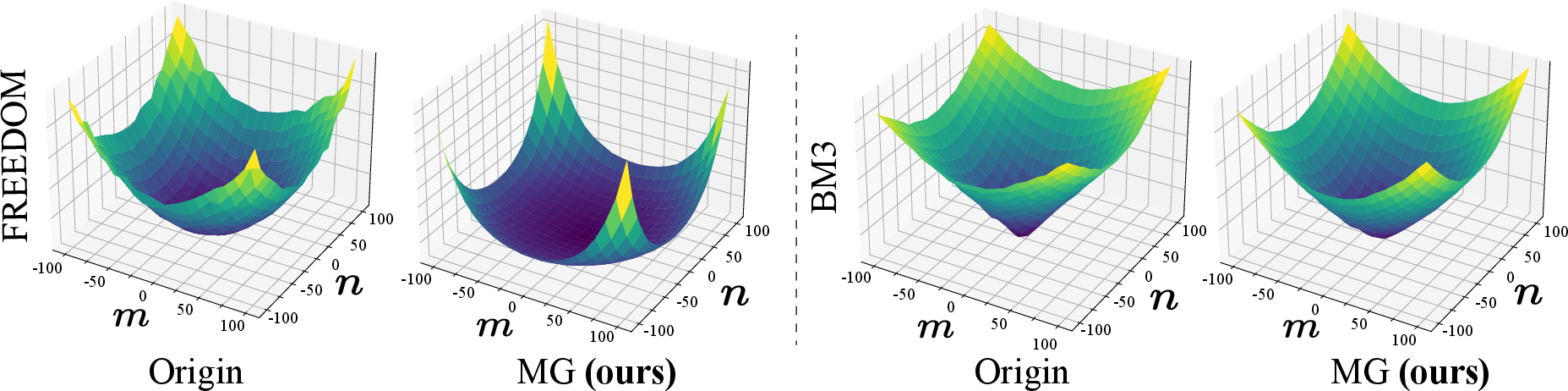
Abstract: Multimodal recommender systems utilize various types of information to model user preferences and item features, helping users discover items aligned with their interests. The integration of multimodal information mitigates the inherent challenges in recommender systems, e.g., the data sparsity problem and cold-start issues. However, it simultaneously magnifies certain risks from multimodal information inputs, such as information adjustment risk and inherent noise risk. These risks pose crucial challenges to the robustness of recommendation models. In this paper, we analyze multimodal recommender systems from the novel perspective of flat local minima and propose a concise yet effective gradient strategy called Mirror Gradient (MG). This strategy can implicitly enhance the model's robustness during the optimization process, mitigating instability risks arising from multimodal information inputs. We also provide strong theoretical evidence and conduct extensive empirical experiments to show the superiority of MG across various multimodal recommendation models and benchmarks. Furthermore, we find that the proposed MG can complement existing robust training methods and be easily extended to diverse advanced recommendation models, making it a promising new and fundamental paradigm for training multimodal recommender systems. The code is released at https://github.com/Qrange-group/Mirror-Gradient.
- Harnessing multimodal data integration to advance precision oncology. Nature Reviews Cancer 22, 2 (2022), 114–126.
- Léon Bottou. 2012. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade: Second Edition. Springer, 421–436.
- Huiyuan Chen and Jing Li. 2019. Adversarial tensor factorization for context-aware recommendation. In Proceedings of the 13th ACM Conference on Recommender Systems. 363–367.
- Bias and debias in recommender system: A survey and future directions. ACM Transactions on Information Systems 41, 3 (2023), 1–39.
- A survey on adversarial recommender systems: from attack/defense strategies to generative adversarial networks. ACM Computing Surveys (CSUR) 54, 2 (2021), 1–38.
- Benoit et al Dherin. 2021. The Geometric Occam’s Razor Implicit in Deep Learning. arXiv preprint arXiv:2111.15090 (2021).
- Efficient sharpness-aware minimization for improved training of neural networks. arXiv preprint arXiv:2110.03141 (2021).
- Enhancing the robustness of neural collaborative filtering systems under malicious attacks. IEEE Transactions on Multimedia 21, 3 (2018), 555–565.
- Adaptive subgradient methods for online learning and stochastic optimization. Journal of machine learning research 12, 7 (2011).
- Sharpness-aware minimization for efficiently improving generalization. arXiv preprint arXiv:2010.01412 (2020).
- Graph neural networks for recommender system. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining. 1623–1625.
- Alex Graves. 2013. Generating sequences with recurrent neural networks. arXiv preprint arXiv:1308.0850 (2013).
- Dynamically Expandable Graph Convolution for Streaming Recommendation. arXiv preprint arXiv:2303.11700 (2023).
- Asymmetric valleys: Beyond sharp and flat local minima. Advances in neural information processing systems 32 (2019).
- Ruining He and Julian McAuley. 2016. VBPR: visual bayesian personalized ranking from implicit feedback. In Proceedings of the AAAI conference on artificial intelligence, Vol. 30.
- Blending pruning criteria for convolutional neural networks. In ICANN 2021: 30th International Conference on Artificial Neural Networks, 2021. Springer, 3–15.
- Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 639–648.
- Sepp Hochreiter and Jürgen Schmidhuber. 1994. Simplifying neural nets by discovering flat minima. Advances in neural information processing systems 7 (1994).
- Sepp Hochreiter and Jürgen Schmidhuber. 1997. Flat minima. Neural computation 9, 1 (1997), 1–42.
- AlterSGD: Finding Flat Minima for Continual Learning by Alternative Training. arXiv preprint arXiv:2107.05804 (2021).
- Understanding Self-attention Mechanism via Dynamical System Perspective. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 1412–1422.
- Layer-wise shared attention network on dynamical system perspective. arXiv preprint arXiv:2210.16101 (2022).
- Dianet: Dense-and-implicit attention network. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 4206–4214.
- Rethinking the pruning criteria for convolutional neural network. Advances in Neural Information Processing Systems 34 (2021), 16305–16318.
- Scalelong: Towards more stable training of diffusion model via scaling network long skip connection. Advances in Neural Information Processing Systems 36 (2024).
- When do flat minima optimizers work? Advances in Neural Information Processing Systems 35 (2022), 16577–16595.
- Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
- Asam: Adaptive sharpness-aware minimization for scale-invariant learning of deep neural networks. In International Conference on Machine Learning. PMLR, 5905–5914.
- Addressing cold-start problem in recommendation systems. In Proceedings of the 2nd international conference on Ubiquitous information management and communication. 208–211.
- Visualizing the loss landscape of neural nets. Advances in neural information processing systems 31 (2018).
- Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597 (2023).
- Adversarial learning to compare: Self-attentive prospective customer recommendation in location based social networks. In Proceedings of the 13th International Conference on Web Search and Data Mining. 349–357.
- Instance enhancement batch normalization: An adaptive regulator of batch noise. In Proceedings of the AAAI conference on artificial intelligence, Vol. 34. 4819–4827.
- Disentangling the Performance Puzzle of Multimodal-aware Recommender Systems. In EvalRS@ KDD (CEUR Workshop Proceedings, Vol. 3450). CEUR-WS. org.
- Image-based recommendations on styles and substitutes. In Proceedings of the 38th international ACM SIGIR conference on research and development in information retrieval. 43–52.
- Make sharpness-aware minimization stronger: A sparsified perturbation approach. Advances in Neural Information Processing Systems 35 (2022), 30950–30962.
- A two-stage embedding model for recommendation with multimodal auxiliary information. Information Sciences 582 (2022), 22–37.
- BPR: Bayesian personalized ranking from implicit feedback. arXiv preprint arXiv:1205.2618 (2012).
- Cornac: A comparative framework for multimodal recommender systems. The Journal of Machine Learning Research 21, 1 (2020), 3803–3807.
- Methods and metrics for cold-start recommendations. In Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval. 253–260.
- Overcoming catastrophic forgetting in incremental few-shot learning by finding flat minima. Advances in neural information processing systems 34 (2021), 6747–6761.
- Enhancing Hierarchy-Aware Graph Networks with Deep Dual Clustering for Session-based Recommendation. In Proceedings of the ACM Web Conference 2023. 165–176.
- On the importance of initialization and momentum in deep learning. In International conference on machine learning. PMLR, 1139–1147.
- Adversarial training towards robust multimedia recommender system. IEEE Transactions on Knowledge and Data Engineering 32, 5 (2019), 855–867.
- Jiaxi Tang and Ke Wang. 2018. Ranking distillation: Learning compact ranking models with high performance for recommender system. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 2289–2298.
- Self-supervised learning for multimedia recommendation. IEEE Transactions on Multimedia (2022).
- Collaborative deep learning for recommender systems. In Proceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining. 1235–1244.
- Dualgnn: Dual graph neural network for multimedia recommendation. IEEE Transactions on Multimedia (2021).
- Graph-refined convolutional network for multimedia recommendation with implicit feedback. In Proceedings of the 28th ACM international conference on multimedia. 3541–3549.
- MMGCN: Multi-modal graph convolution network for personalized recommendation of micro-video. In Proceedings of the 27th ACM international conference on multimedia. 1437–1445.
- Fight fire with fire: towards robust recommender systems via adversarial poisoning training. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1074–1083.
- ConsRec: Learning Consensus Behind Interactions for Group Recommendation. In Proceedings of the ACM Web Conference 2023. 240–250.
- Collaborative knowledge base embedding for recommender systems. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 353–362.
- Diffusion-based graph contrastive learning for recommendation with implicit feedback. In International Conference on Database Systems for Advanced Applications. Springer, 232–247.
- Penalizing gradient norm for efficiently improving generalization in deep learning. In International Conference on Machine Learning. PMLR, 26982–26992.
- Let’s Think Outside the Box: Exploring Leap-of-Thought in Large Language Models with Creative Humor Generation. arXiv preprint arXiv:2312.02439 (2023).
- ASR: Attention-alike Structural Re-parameterization. arXiv preprint arXiv:2304.06345 (2023).
- Sur-adapter: Enhancing text-to-image pre-trained diffusion models with large language models. In Proceedings of the 31st ACM International Conference on Multimedia. 567–578.
- CEM: Machine-Human Chatting Handoff via Causal-Enhance Module. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 3242–3253.
- Enhancing Dyadic Relations with Homogeneous Graphs for Multimodal Recommendation. arXiv preprint arXiv:2301.12097 (2023).
- A Comprehensive Survey on Multimodal Recommender Systems: Taxonomy, Evaluation, and Future Directions. arXiv preprint arXiv:2302.04473 (2023).
- Xin Zhou. 2022. A tale of two graphs: Freezing and denoising graph structures for multimodal recommendation. arXiv preprint arXiv:2211.06924 (2022).
- Evaluating reputation of web services under rating scarcity. In 2016 IEEE International Conference on Services Computing (SCC). IEEE, 211–218.
- Layer-refined graph convolutional networks for recommendation. In 2023 IEEE 39th International Conference on Data Engineering (ICDE). IEEE, 1247–1259.
- Selfcf: A simple framework for self-supervised collaborative filtering. ACM Transactions on Recommender Systems 1, 2 (2023), 1–25.
- Bootstrap latent representations for multi-modal recommendation. In Proceedings of the ACM Web Conference 2023. 845–854.
- Surrogate gap minimization improves sharpness-aware training. arXiv preprint arXiv:2203.08065 (2022).
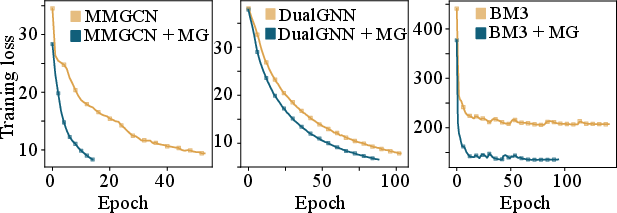
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

