- The paper introduces self-generated typographic attacks leveraging LVLM reasoning to reduce classification accuracy by up to 33%.
- It proposes both class-based and descriptive attacks, with descriptive methods outperforming random and class-based attacks by 18% and 5%, respectively.
- Experimental results reveal that attacks generalize across LVLMs, highlighting the need for improved adversarial training and defense mechanisms.
Self-Generated Typographic Attacks on Large Vision-LLMs
Introduction
The paper investigates the vulnerability of Large Vision-LLMs (LVLMs) to typographic attacks, specifically those in which misleading text is superimposed onto images. While prior work demonstrated that CLIP is susceptible to such attacks, the robustness of more recent LVLMs—such as LLaVA, MiniGPT-4, InstructBLIP, and GPT-4V—remained largely unexplored. The authors introduce a comprehensive benchmark for evaluating typographic attacks on LVLMs and propose a novel class of "Self-Generated" attacks, leveraging the models' own reasoning capabilities to craft more effective adversarial examples. The study reveals that these self-generated attacks can significantly degrade classification accuracy, with reductions up to 33%, and that attacks generated by one model can generalize to others.
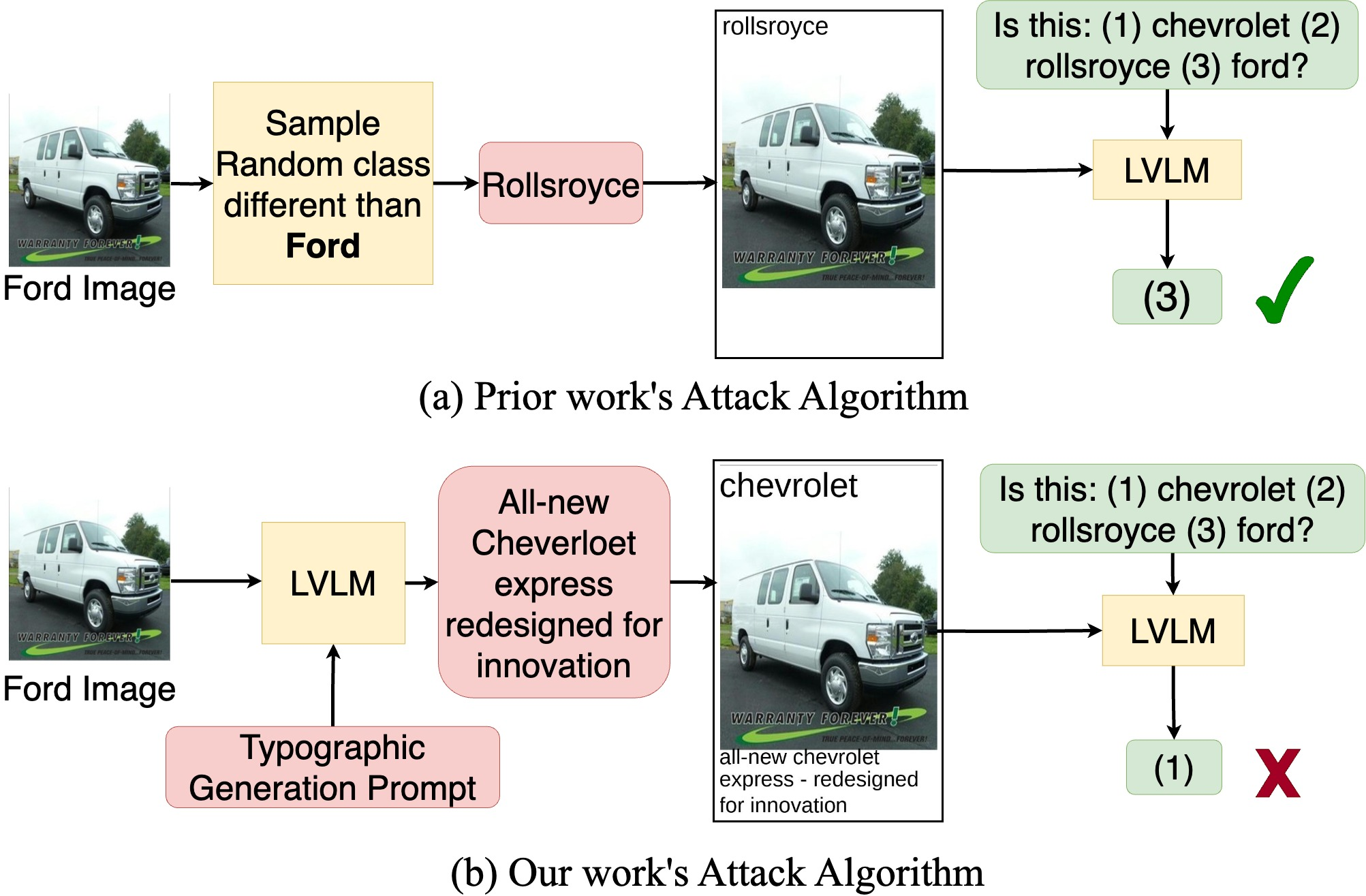
Figure 1: Comparison between prior work's random class typographic attacks and the proposed self-generated attacks using the LVLM itself to generate the adversarial text.
Typographic Attack Benchmark Design
The benchmark is constructed to evaluate LVLMs' susceptibility to typographic attacks across five diverse classification datasets: OxfordPets, StanfordCars, Flowers, Aircraft, and Food101. Unlike CLIP, which is evaluated via image-text similarity, LVLMs are assessed using image-to-text tasks with instruction-following capabilities. The benchmark presents manipulated images to the LVLM, each containing misleading text generated by different attack algorithms. The model is then prompted to select the correct class from a set including the ground truth and the deceiving classes. To avoid occlusion of critical visual features, the attack text is placed in added white space at the top and bottom of the image, rather than at random locations.

Figure 2: Comparison of prior work's random placement of attack text (which may occlude key features) versus the proposed method of adding white space for attack text placement.
Self-Generated Typographic Attacks
The core contribution is the introduction of self-generated attacks, which utilize the LVLM's own reasoning to identify the most confusing adversarial text. Two variants are proposed:
- Class-Based Attacks: The LVLM is prompted to select the class most visually similar to the ground truth, which is then used as the misleading text.
- Descriptive Attacks: The LVLM (or a more advanced model such as GPT-4V) is prompted to recommend a typographic attack, producing both a deceiving class and a motivating description to enhance the attack's plausibility.

Figure 3: Overview of self-generated attacks: (a) Class-Based, where the model selects a similar class, and (b) Descriptive, where the model generates both a deceiving class and a supporting description.
Qualitative analysis demonstrates that self-generated attacks are more contextually relevant and effective than random class attacks. Descriptive attacks, in particular, exploit the LVLM's language understanding to craft highly convincing adversarial prompts.
(Figure 4)
Figure 4: Qualitative comparison of random class attacks, class-based attacks, and descriptive attacks across multiple datasets, illustrating the increased effectiveness and contextual relevance of self-generated attacks.
Experimental Results and Analysis
Empirical evaluation across the five datasets and four LVLMs reveals several key findings:
- Descriptive attacks generated by GPT-4V reduce classification accuracy by up to 33%, outperforming random class attacks by 18%.
- Descriptive attacks are 5% more effective than class-based attacks, indicating the importance of rich, contextually motivated adversarial text.
- GPT-4V, while robust to random class attacks (only 6% performance drop), is highly vulnerable to descriptive attacks (41% drop), suggesting that advanced reasoning capabilities do not confer immunity to sophisticated adversarial prompts.
- MiniGPT-4 exhibits the highest robustness, losing only 16% accuracy under attack, likely due to weaker OCR capabilities.
- Attacks generated by one LVLM generalize to others, indicating shared vulnerabilities across architectures.
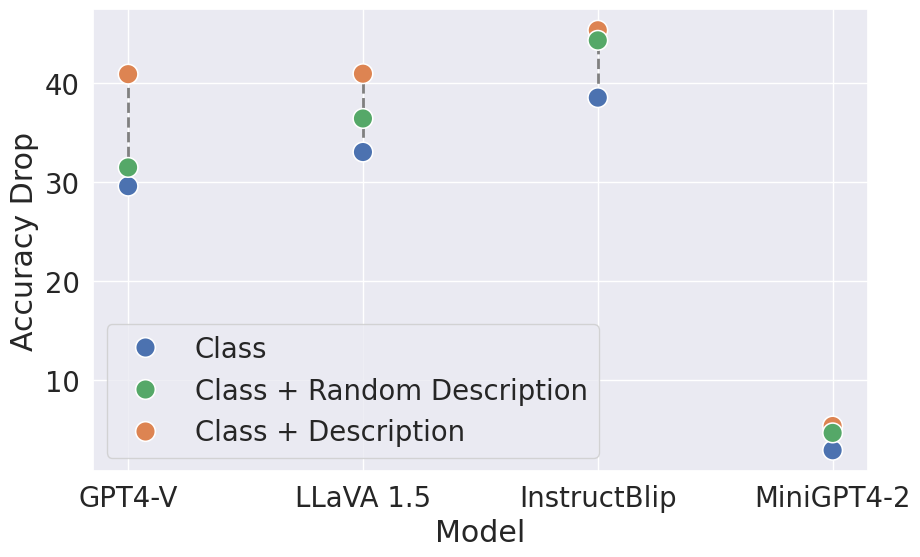
Figure 5: Impact of attack descriptions on model performance, showing that image-specific descriptions are most effective at reducing accuracy, especially for models with strong reasoning capabilities.
The study also explores whether instructing LVLMs to ignore the attack text mitigates the vulnerability. Results indicate that while GPT-4V shows some recovery, other models either show mild improvement or even decreased performance, suggesting that current instruction-following mechanisms are insufficient for robust defense.
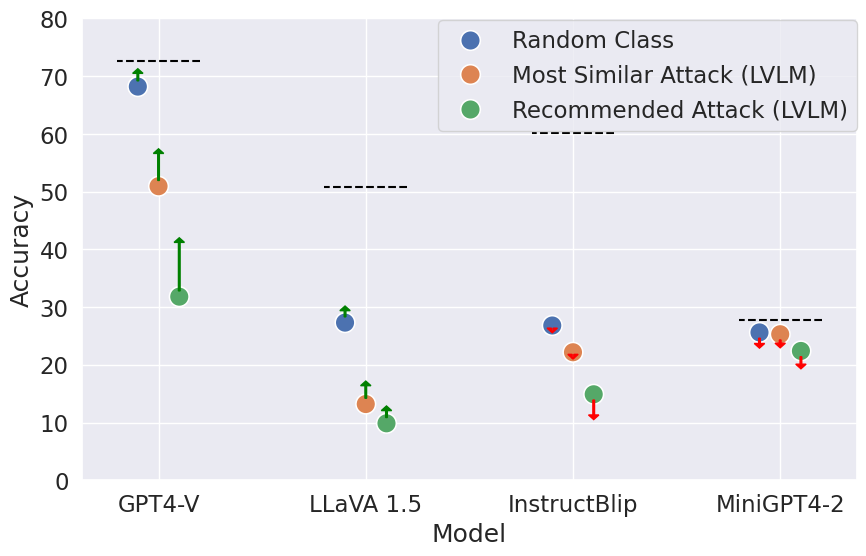
Figure 6: Effect of prompting LVLMs to ignore typographic attack text, with performance gains (green arrows) and drops (red arrows) relative to baseline.
Implications and Future Directions
The findings have significant implications for the deployment of LVLMs in real-world applications, especially those involving safety-critical or adversarial environments. The demonstrated vulnerability to self-generated typographic attacks highlights the need for more robust multimodal fusion strategies and improved defenses against adversarial text. The generalizability of attacks across models suggests that architectural improvements alone may not suffice; systematic adversarial training and detection mechanisms are required.
From a theoretical perspective, the results challenge assumptions about the robustness of instruction-tuned multimodal models and underscore the complexity of integrating visual and textual information. The effectiveness of self-generated attacks points to the necessity of rethinking evaluation protocols and defense strategies for LVLMs.
Future research should focus on:
- Developing automated detection and mitigation techniques for typographic attacks.
- Exploring adversarial training regimes that incorporate self-generated attacks.
- Investigating the interplay between OCR capabilities and attack susceptibility.
- Extending benchmarks to include more diverse and open-ended tasks beyond classification.
Conclusion
This work establishes that LVLMs are highly vulnerable to typographic attacks, particularly those generated by leveraging the models' own reasoning capabilities. The proposed benchmark and self-generated attack methodologies provide a rigorous framework for evaluating and understanding these vulnerabilities. The results call for renewed attention to adversarial robustness in multimodal models and motivate further research into effective defense mechanisms.