- The paper introduces CenterRadarNet, a framework that enhances 3D object detection and tracking using novel 4D FMCW radar data.
- It employs a Conv3D HR3D backbone with parallel detection and appearance heads to extract robust features and improve object re-identification.
- Experimental results on the K-Radar benchmark demonstrate state-of-the-art performance and improved detection accuracy under adverse conditions.
CenterRadarNet: Joint 3D Object Detection and Tracking Framework using 4D FMCW Radar
The paper "CenterRadarNet: Joint 3D Object Detection and Tracking Framework using 4D FMCW Radar" presents a novel approach leveraging 4D FMCW radar data for joint 3D object detection and tracking, addressing limitations seen in previous 3D radar tensor methods. It introduces CenterRadarNet, a comprehensive framework designed to enhance perception capabilities in autonomous and assisted driving systems, particularly under challenging weather conditions.
Introduction
Robust perception in autonomous vehicles remains critical due to varying driving conditions. While cameras and LiDAR have dominated perception systems, radar provides weather-resistant sensing, complementing these systems with its capability to preserve spatiotemporal information via raw radio-frequency (RF) radar tensors. Existing methods often handle 3D radar tensors but lack the ability to infer detailed size, orientation, and identity simultaneously. CenterRadarNet addresses these gaps by using 4D radar data to predict 3D bounding boxes and appearance features for object re-identification, enabling simultaneous detection and re-ID tasks.

Figure 1: CenterRadarNet is a comprehensive framework designed for 3D object detection and tracking, specifically utilizing 4D FMCW radar tensors as its input. The architecture is comprised of three main components: a Conv3D backbone for feature extraction, specialized object detection and appearance heads for accurate object recognition, and an online tracker.
Framework Overview
CenterRadarNet proposes a single-stage 3D object detection architecture comprising a 3D backbone called HR3D, inspired by HRNet, and separate object detection and appearance heads. The architecture retains high-resolution representation and aggregates multi-scale features crucial for accurate object detection. The detection heads work in parallel to classify and regress bounding box attributes, simultaneously learning appearance embeddings for re-ID tasks.
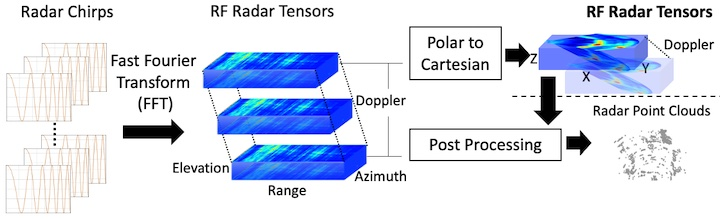
Figure 2: Radar Signal Processing and Representation. We use RF radar tensors after the polar to Cartesian coordinate transform as our model input.
HR3D backbone processes the input radar tensors, preserving spatial resolution while learning volumetric spatial features. A strategic feature aggregation mechanism enhances feature learning for better detection accuracy of large objects, directly influencing the model’s ability to handle complex driving scenarios.
Detection and Appearance Embedding
The object detection pipeline adopts a dense keypoint learning approach, extending the functionality of previous detectors by integrating appearance features. A critical innovation in training includes leveraging a statistical CA-CFAR algorithm to quantify radar visibility, enhancing detection accuracy of traditionally hard-to-detect objects.
CenterRadarNet's training strategy employs cross-frame joint detection and appearance training, emphasizing the extraction of discriminative appearance features essential for effective object re-ID. A triplet loss function assists in learning robust embeddings, crucial for the association task in tracking.
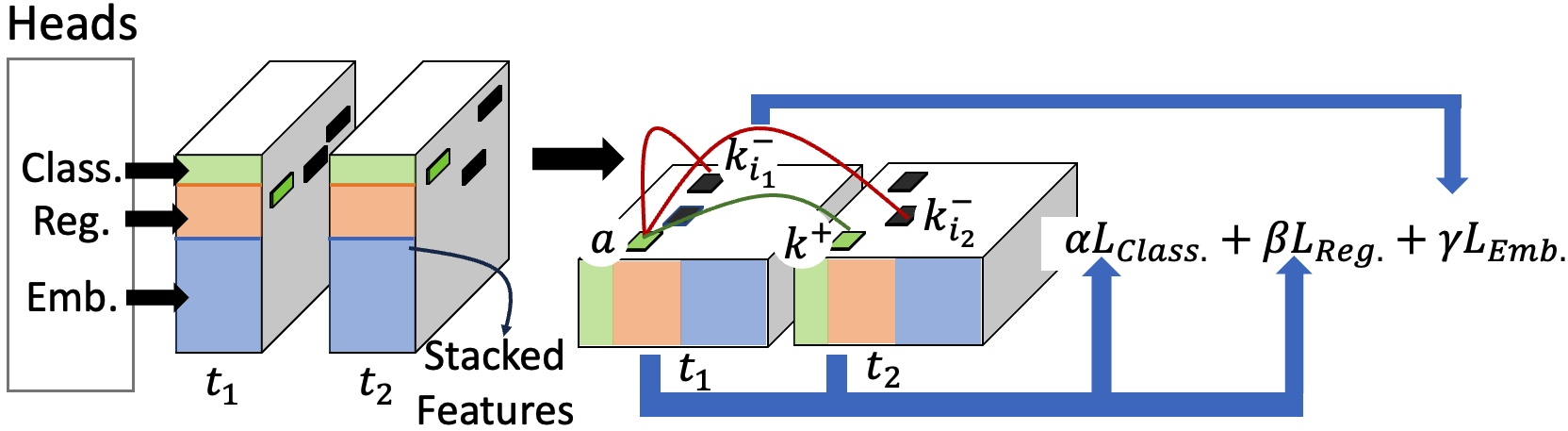
Figure 3: Joint detection and appearance embedding training procedure.
Online Tracking
The framework incorporates an online tracking mechanism using learned appearance embeddings alongside bounding box attributes. A modified BoT-SorT tracking algorithm integrates DIoU as the assignment cost, optimizing the association process, especially under fast-moving vehicle conditions and complex maneuvers.
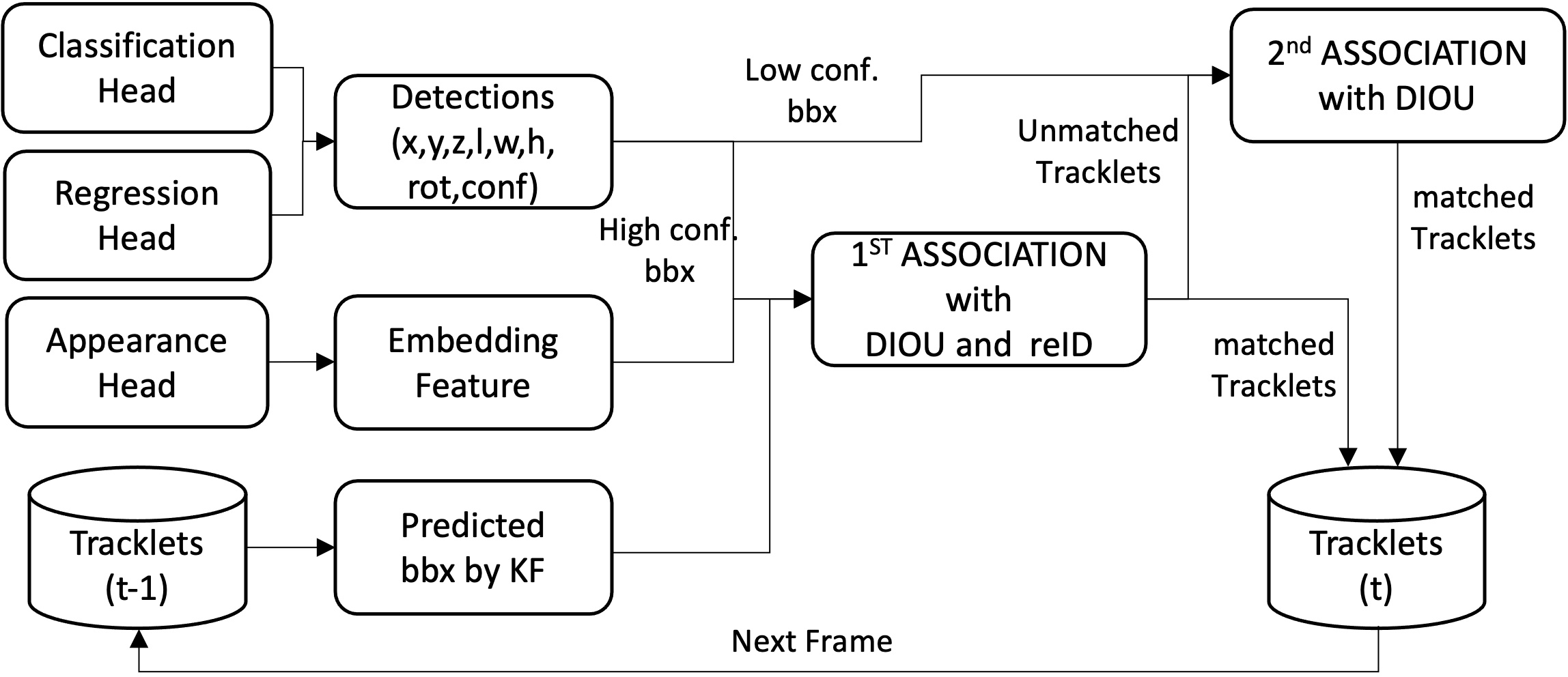
Figure 4: The pipeline of our online tracker. The state of detection is from the classification, regression heads and the embedding features are from the appearance head. The 'conf' in detection describes the confidence score of the bounding box, which is used as the threshold of 'KF' means the Kalman filter and 'bbx' refers to the bounding boxes identified within a single frame.
Experimental Evaluation
CenterRadarNet demonstrates state-of-the-art results on the K-Radar 3D object detection benchmark. The robustness of the approach is evident across diverse driving scenarios, validating the framework’s applicability to real-world conditions. The experiments highlight the efficacy and precision of feature extraction without the need for human-engineered signal processing stages, showcasing superior AP scores over existing methods.
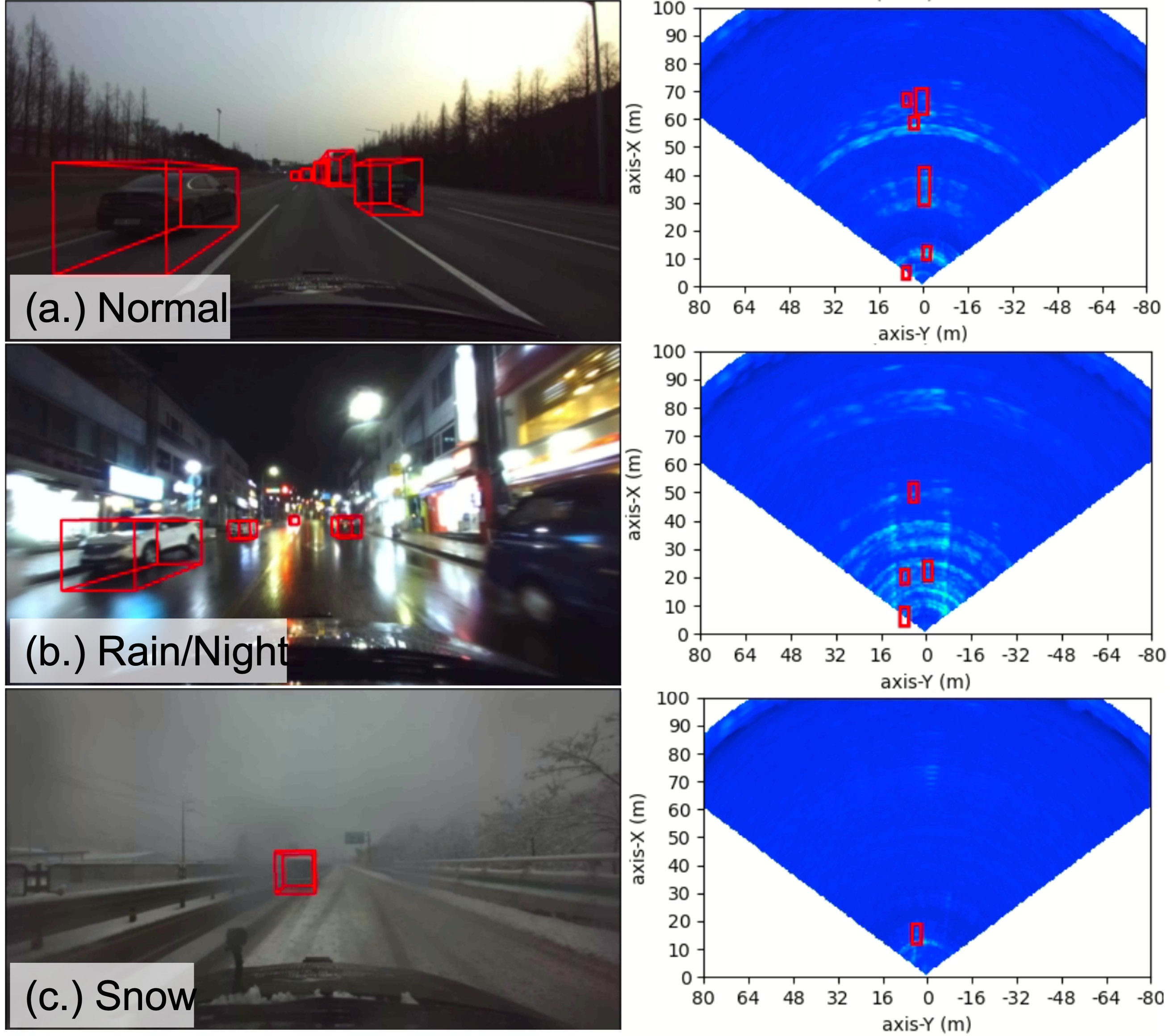
Figure 5: CenterRadarNet's prediction results on the K-Radar test set are visualized in both the front camera's field of view and the radar Bird's Eye View (BEV) with power intensity serving as the background. The successful detection of objects under various weather conditions attests to the robustness of using radar as the sensor input.
Conclusion
CenterRadarNet represents a significant advancement in radar-based perception for autonomous driving, paving the way for more reliable sensor fusion strategies and robust environmental understanding, regardless of adverse weather conditions. Future directions may involve expanding its applications to include more diverse object categories and leveraging larger, more varied datasets for training enhancements. Through its innovative architecture, CenterRadarNet sets a promising precedent for the continued integration of radar in autonomous vehicle sensor suites.