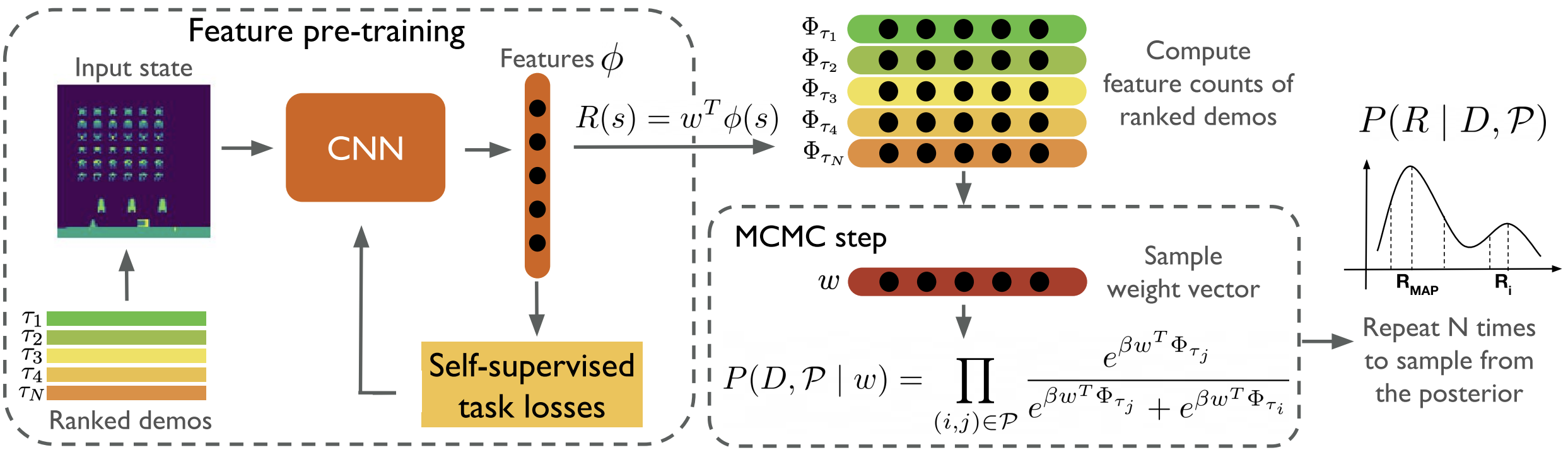
- The paper presents a comprehensive review of imitation learning by categorizing key methods such as behavioral cloning, inverse reinforcement, and adversarial techniques.
- It details the challenges like covariate shift, computational complexity, and domain discrepancies, offering insights into potential solutions including interactive learning strategies.
- The survey underscores the practical implications for autonomous systems in robotics and AI by leveraging expert demonstrations for adaptable and robust policy learning.
A Survey of Imitation Learning: Algorithms, Recent Developments, and Challenges
The paper "A Survey of Imitation Learning: Algorithms, Recent Developments, and Challenges" provides an exhaustive review of imitation learning (IL), underlining its relevance and applications in robotics and AI. It addresses the fundamental aspects, current advancements, and challenges within IL, emphasizing its potential for enabling autonomous systems to learn from expert demonstrations.
Introduction to Imitation Learning
Imitation Learning is defined as the process through which an autonomous agent learns desired behavior by imitating an expert’s actions. Unlike manual programming or reward-based reinforcement learning, IL offers a versatile and adaptive framework by requiring only expert demonstrations without the cumbersome task of specifying explicit rules or reward functions. This learning paradigm is valuable in applications like autonomous driving, robotics, and AI-driven gaming, where flexible and adaptable behaviors are mandatory.
The major benefits of IL include its ability to leverage human expertise to teach machines, bypassing the need for explicit programming. Moreover, IL mitigates the complexity involved in designing reward functions for dynamic and unpredictable environments, often encountered in real-world applications.
Temporal Evolution and Categorization
The paper outlines the evolution of IL from its inception, showcasing how recent computational advances and the burgeoning interest in AI applications have invigorated the field (Figure 1).
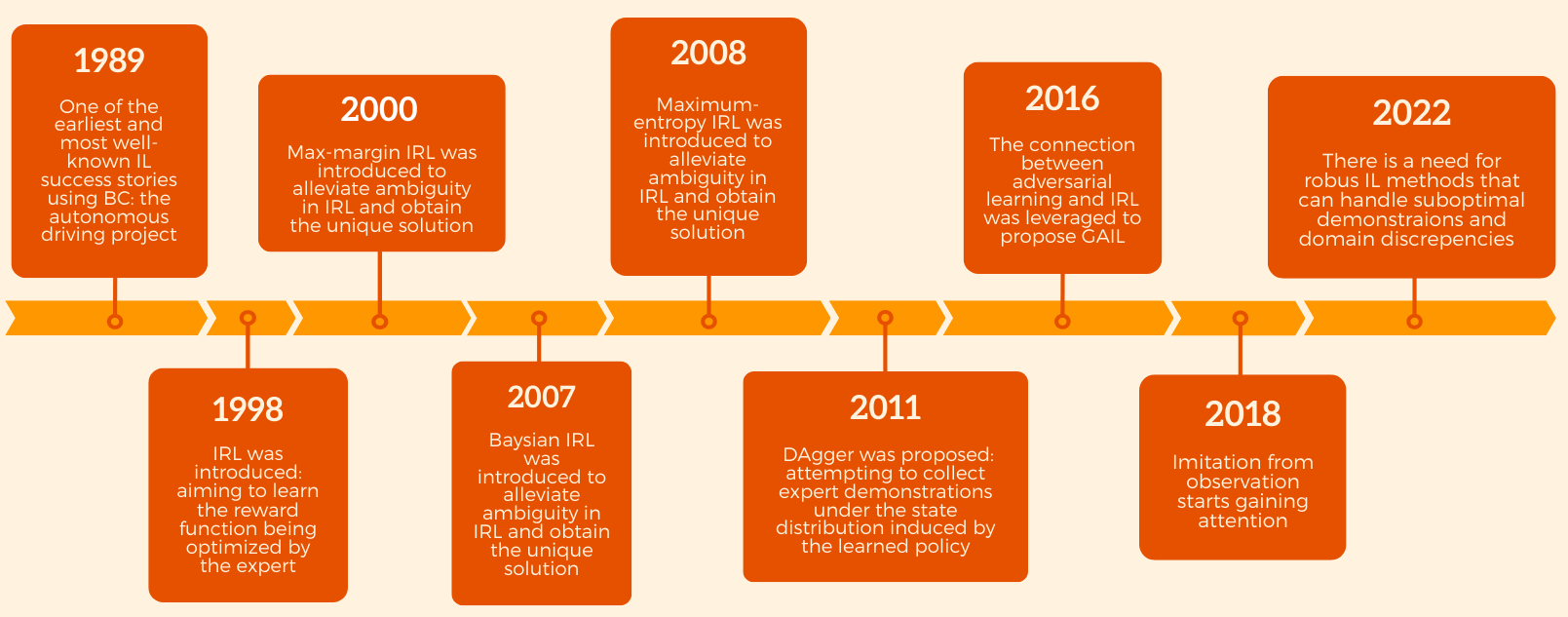
Figure 1: A historical timeline of IL research illustrating key achievements in the field.
The primary methodologies within IL are categorized into Behavioral Cloning (BC) and Inverse Reinforcement Learning (IRL), each with specific formulations, strengths, and limitations.
Behavioral Cloning
BC formulates IL as a supervised learning problem where the agent learns the mapping between states and actions based on expert demonstrations. It requires no model of environment dynamics but suffers from the covariate shift problem, where discrepancies between training and test distributions can degrade performance.
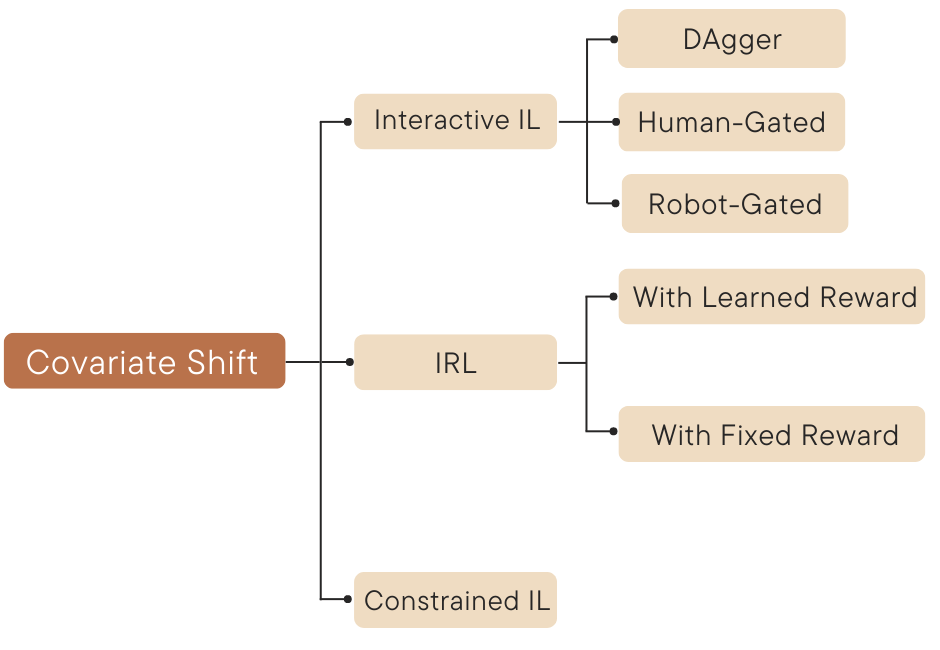
Figure 2: A categorization of methods addressing the covariate shift problem.
Challenges and Solutions:
Inverse Reinforcement Learning
IRL infers the underlying reward function from an expert’s behavior, which the agent then optimizes using RL. This methodology effectively addresses covariate shift and ensures more robust policy learning compared to BC.
Key Difficulties:
Adversarial Imitation Learning
AIL frameworks like Generative Adversarial Imitation Learning (GAIL) and its derivatives provide computational efficiency by framing the learning problem as a game between the agent and a discriminator. AIL avoids solving explicit RL problems iteratively, leveraging adversarial training to simplify policy optimization.
AIL Extensions:
- Refinements in discriminator loss functions and off-policy methods expand AIL’s applicability and efficiency.
- Utilization of Wasserstein distances enhances training stability, fostering progress in integrating adversarial mechanisms in IL.
Imitation from Observation
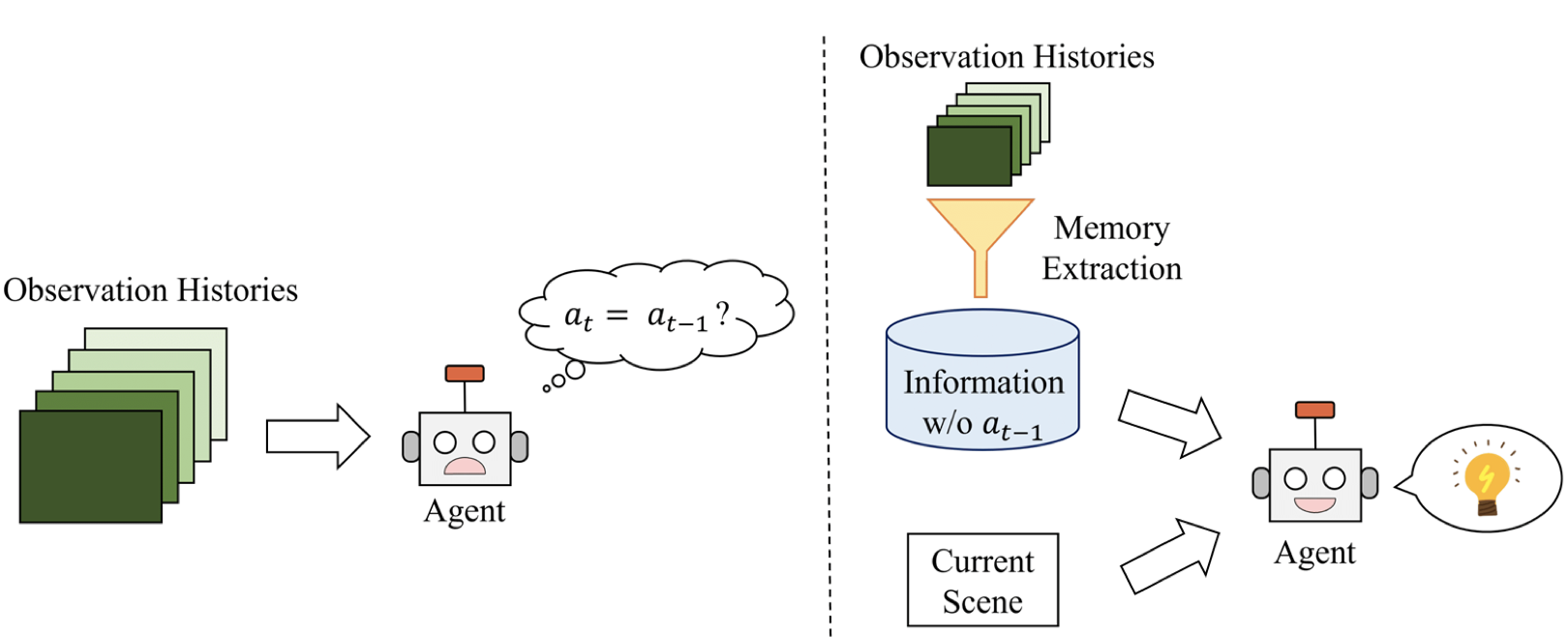
Unlike traditional IL, where both states and actions are known, Imitation from Observation (IfO) leverages demonstrations with unknown actions, making widespread resources like videos viable for learning policies. This approach bears significant potential in accessibility and flexibility for real-world applications, such as robotics and human-like imitation strategies (Figure 5).
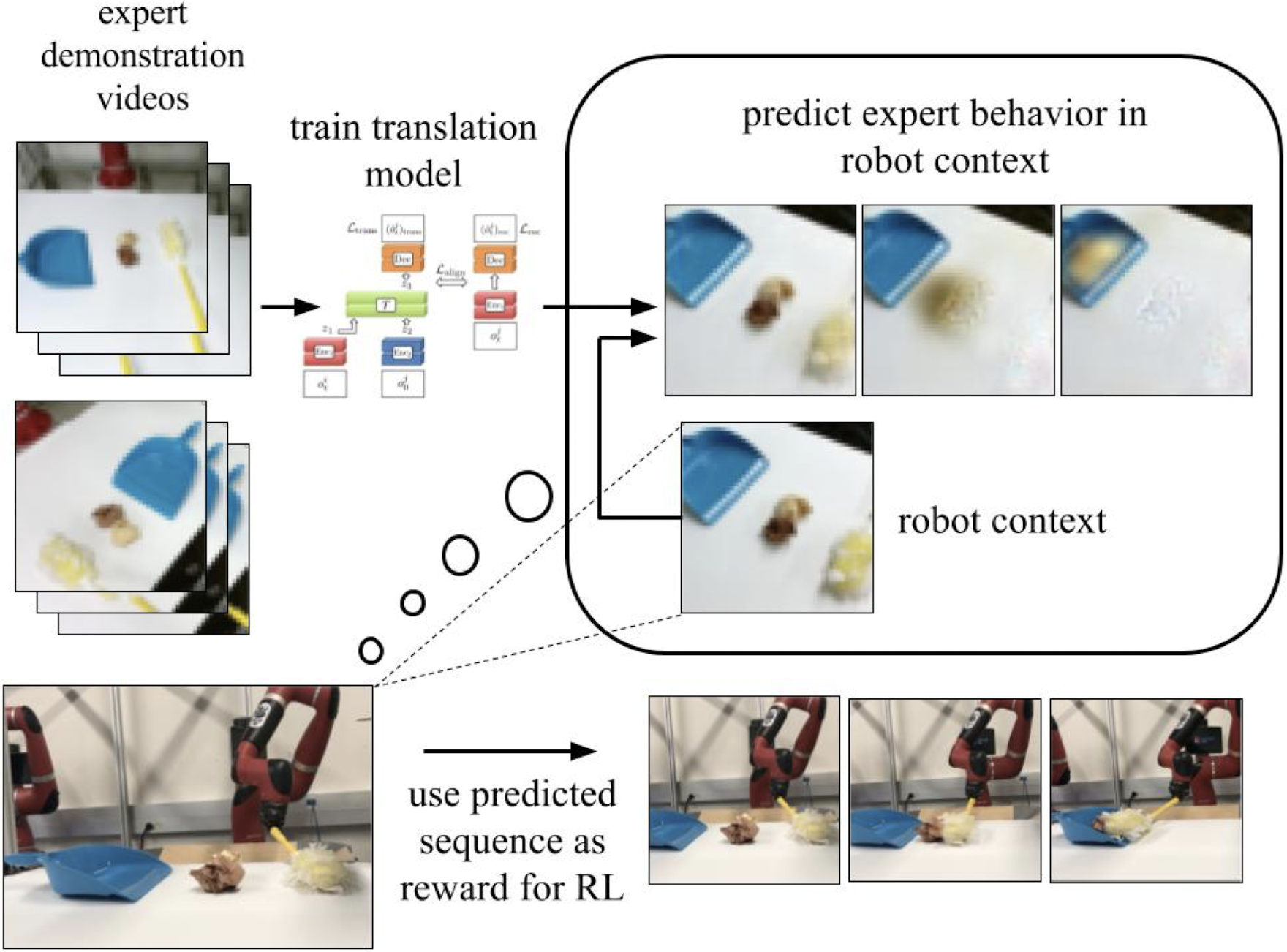
Figure 5: A context translation model is trained on several videos of expert demonstrations.
Challenges and Limitations
Imperfect Demonstrations:
Efforts focus on improving policy robustness by learning from demonstrations of varying quality, addressing human error, and utilizing imperfect or annotated datasets effectively.
Domain Discrepancies:
Techniques for cross-domain IL aim to train agents to perform tasks optimally within their operational context despite differences in dynamics, viewpoints, and embodiment. Advanced methods generalize policies across varied environments without prior alignment or explicit mappings (Figure 6).
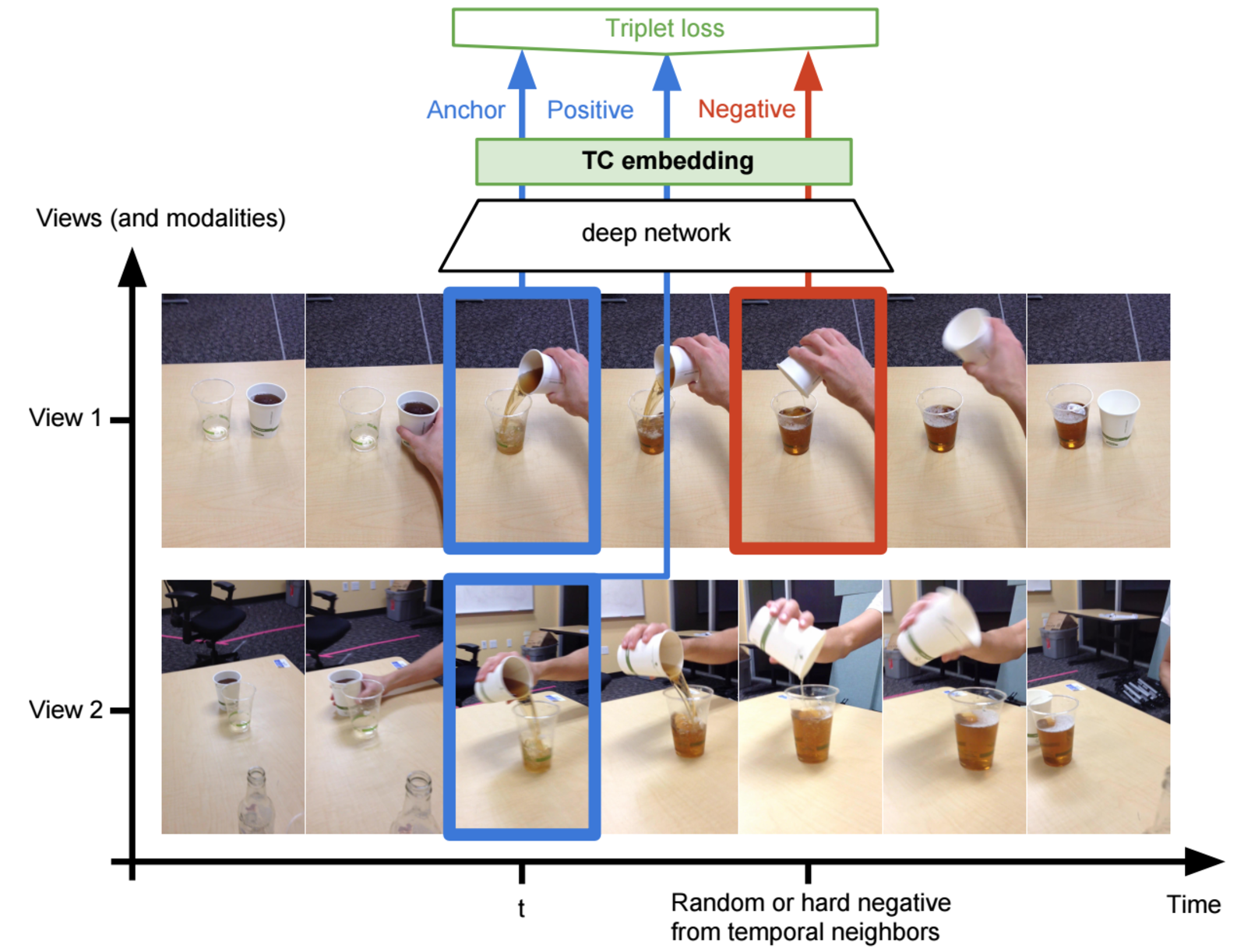
Figure 6: IL against variations in environment dynamics.
Conclusion
The survey comprehensively captures progress in IL, spotlighting its methodologies and categorizing them against current challenges. Future research should address imperfect or incomplete demonstrations and cross-domain learning complexities to unlock IL's potential fully. By continually adapting IL approaches and broadening their applicability, autonomous systems can achieve significantly higher levels of performance and adaptability across diverse domains.