Improving Video Violence Recognition with Human Interaction Learning on 3D Skeleton Point Clouds
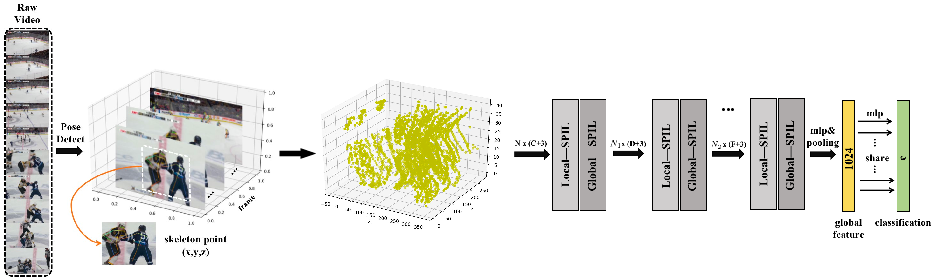
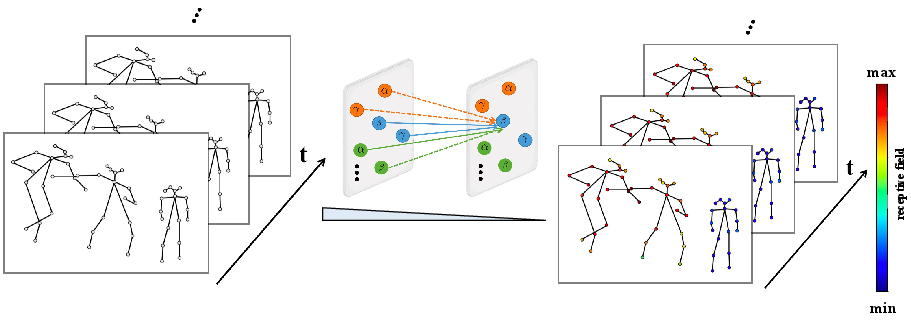
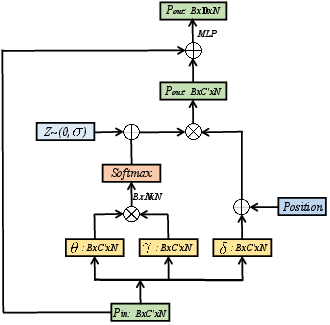
Abstract: Deep learning has proved to be very effective in video action recognition. Video violence recognition attempts to learn the human multi-dynamic behaviours in more complex scenarios. In this work, we develop a method for video violence recognition from a new perspective of skeleton points. Unlike the previous works, we first formulate 3D skeleton point clouds from human skeleton sequences extracted from videos and then perform interaction learning on these 3D skeleton point clouds. Specifically, we propose two types of Skeleton Points Interaction Learning (SPIL) strategies: (i) Local-SPIL: by constructing a specific weight distribution strategy between local regional points, Local-SPIL aims to selectively focus on the most relevant parts of them based on their features and spatial-temporal position information. In order to capture diverse types of relation information, a multi-head mechanism is designed to aggregate different features from independent heads to jointly handle different types of relationships between points. (ii) Global-SPIL: to better learn and refine the features of the unordered and unstructured skeleton points, Global-SPIL employs the self-attention layer that operates directly on the sampled points, which can help to make the output more permutation-invariant and well-suited for our task. Extensive experimental results validate the effectiveness of our approach and show that our model outperforms the existing networks and achieves new state-of-the-art performance on video violence datasets.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

