- The paper introduces a Hadamard overparametrization framework that transforms non-smooth ℓ1 and non-convex regularizers into smooth optimization problems.
- It employs differentiable gradient descent and Group Hadamard Product Parametrization to address both standard and structured sparsity scenarios.
- Numerical experiments show competitive performance in high-dimensional regression and sparse neural network training with scalable efficiency.
Smooth Optimization for Sparse Regularization using Hadamard Overparametrization
Introduction
The paper "Smoothing the Edges: Smooth Optimization for Sparse Regularization using Hadamard Overparametrization" (2307.03571) presents a novel framework for solving optimization problems involving sparse regularization. Traditionally, such problems are non-smooth and possibly non-convex, often requiring specialized solvers. This work provides a method for smooth optimization by introducing a Hadamard product parametrization. The proposed framework enables fully differentiable and approximation-free applications of gradient descent, fundamentally compatible with prevailing deep learning (DL) paradigms.
Methodology
The framework utilizes a Hadamard product-based parametrization to create smooth surrogates for non-smooth regularization terms. It essentially transforms the original problem—characterized by a non-smooth ℓ1 regularization—into an equivalent smooth problem. This is achieved by overparametrization using additional variables and introducing a change of penalties. The central concept involves substituting the non-smooth regularizer with a smooth surrogate penalizer that is easier to handle computationally.
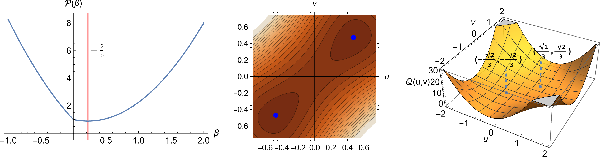
Figure 1: Illustration of smooth optimization transfer. A transformation of a univariate lasso problem into a smooth surrogate using Hadamard product parametrization.
Convex and Non-Convex Sparse Regularization
The framework addresses both convex ℓ1 regularization and its non-convex counterparts such as SCAD and MCP. Utilizing the Hadamard product, the method articulates a smooth surrogate optimization that ensures that both global and local minima of the transformed problem correspond to those of the original problem. This equivalence is a crucial aspect as it guarantees that the smooth optimization correctly solves the original non-convex problem.
Structured Sparsity and Group Lasso
The inclusion of grouping in parameter structures allows for extending the framework to structured sparsity scenarios, such as group lasso regularization. The introduction of the Group Hadamard Product Parametrization (GHPP) further enables this application by tying together parameters within the same group, thus facilitating the encoding of prior structural information directly into the optimization problem.
Practical Implications and Numerical Results
The framework's implementation extends to high-dimensional regression problems and deep neural networks (DNNs), offering a practical solution for sparse neural network training (Figure 2). Numerical experiments demonstrate the method's efficacy across various domains, showing that the smooth optimization approach achieves competitive performance with traditional methods and specialized optimizers in common sparse learning problems.
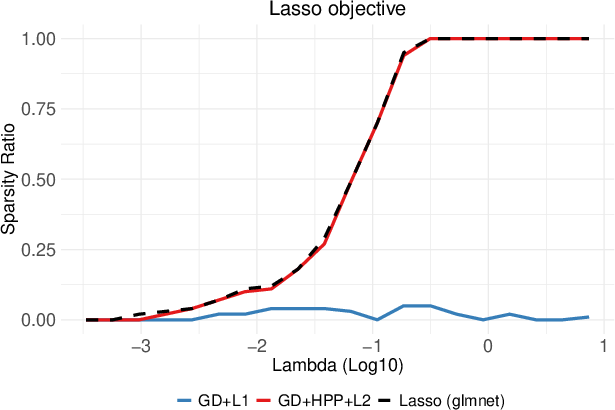
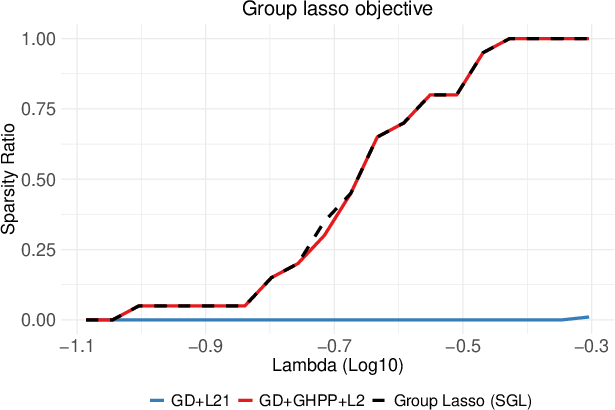
Figure 2: Comparison of regularization paths of (G)HPP-based GD and direct (Sub)GD optimization of non-smooth ℓ1 and ℓ2,1 objectives.
Implications and Future Directions
This work significantly impacts the landscape of sparse optimization by providing an accessible framework that leverages modern DL techniques for more efficient and scalable optimization. The use of smooth optimization transfer offers potential for further research into more complex non-smooth problems, enabling broader applications in machine learning and statistics.
Possible future developments include extending this framework to other classes of non-smooth regularizers and exploring more complex data structures that could benefit from structured sparsity. Additionally, the integration of this methodology within auto-differentiation frameworks commonly used in DL could provide a robust toolset for practitioners dealing with high-dimensional and complex datasets.