Multivariate Time Series Classification: A Deep Learning Approach
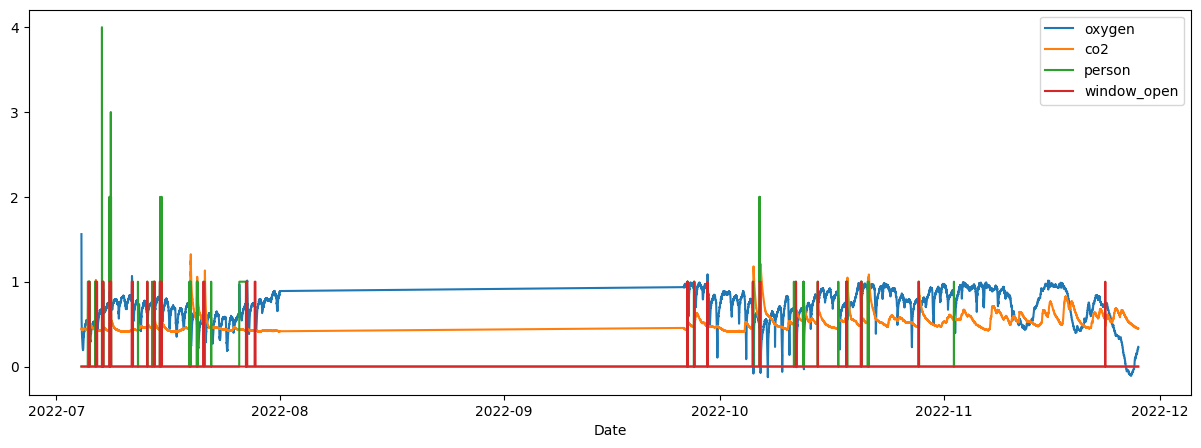
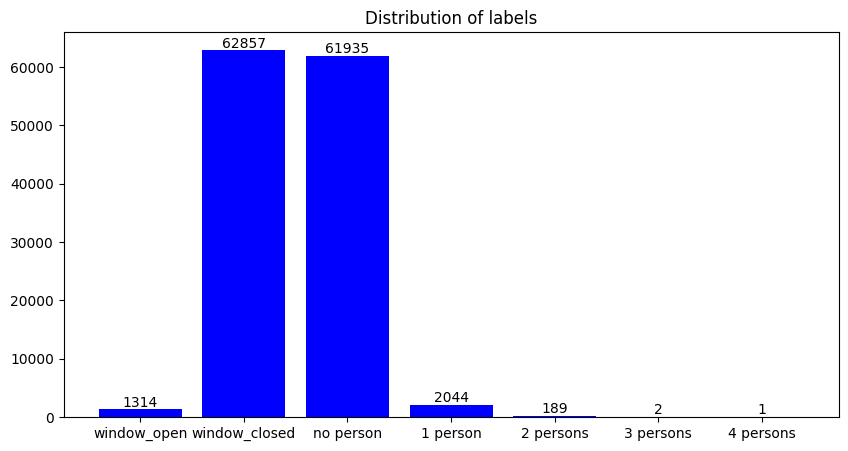
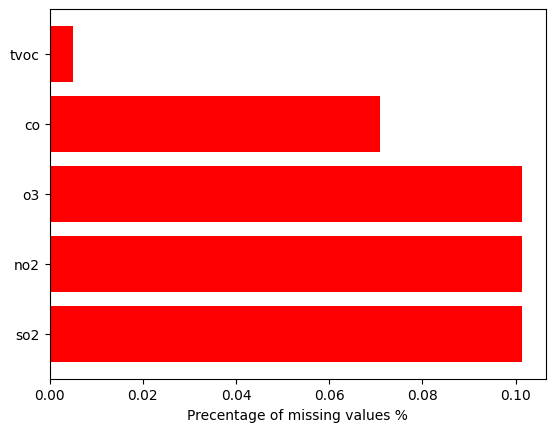
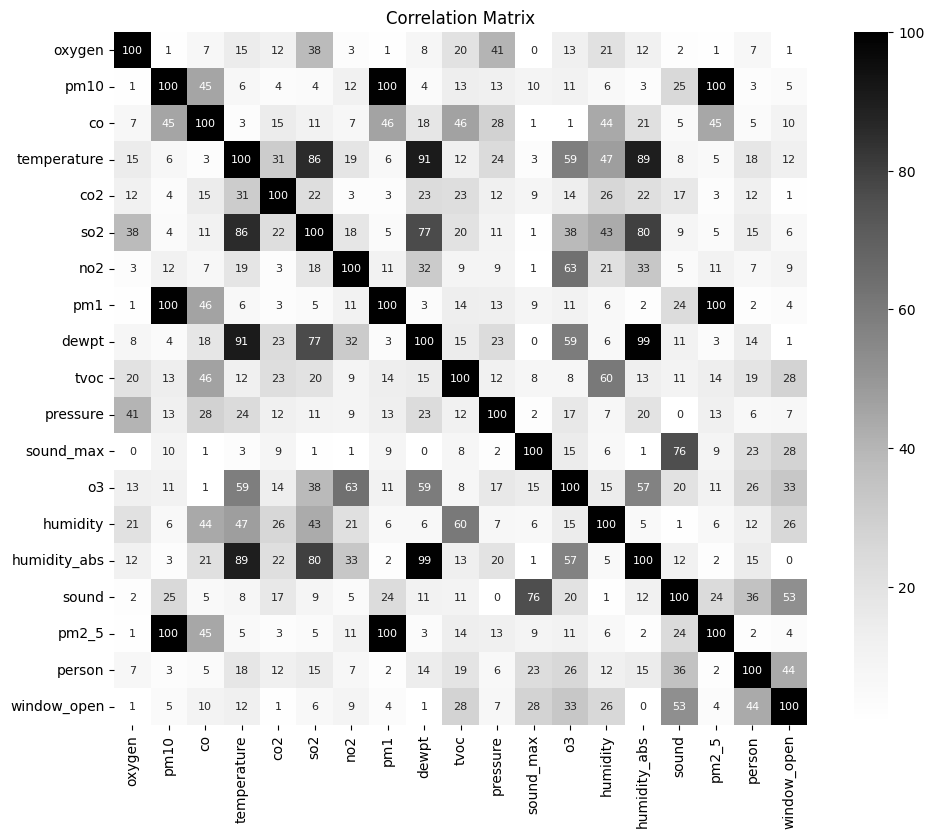
Abstract: This paper investigates different methods and various neural network architectures applicable in the time series classification domain. The data is obtained from a fleet of gas sensors that measure and track quantities such as oxygen and sound. With the help of this data, we can detect events such as occupancy in a specific environment. At first, we analyze the time series data to understand the effect of different parameters, such as the sequence length, when training our models. These models employ Fully Convolutional Networks (FCN) and Long Short-Term Memory (LSTM) for supervised learning and Recurrent Autoencoders for semisupervised learning. Throughout this study, we spot the differences between these methods based on metrics such as precision and recall identifying which technique best suits this problem.
- Hervé Abdi and Lynne J Williams “Principal component analysis” In Wiley interdisciplinary reviews: computational statistics 2.4 Wiley Online Library, 2010, pp. 433–459
- Ratnadip Adhikari and Ramesh K Agrawal “An introductory study on time series modeling and forecasting” In arXiv preprint arXiv:1302.6613, 2013
- “Optuna: A Next-generation Hyperparameter Optimization Framework” In Proceedings of the 25rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2019
- “API design for machine learning software: experiences from the scikit-learn project” In ECML PKDD Workshop: Languages for Data Mining and Machine Learning, 2013, pp. 108–122
- “Pearson correlation coefficient” In Noise reduction in speech processing Springer, 2009, pp. 1–4
- “The relationship between Precision-Recall and ROC curves” In Proceedings of the 23rd international conference on Machine learning, 2006, pp. 233–240
- “Long short-term memory” In Supervised sequence labelling with recurrent neural networks Springer, 2012, pp. 37–45
- “Array programming with NumPy” In Nature 585.7825 Springer ScienceBusiness Media LLC, 2020, pp. 357–362 DOI: 10.1038/s41586-020-2649-2
- “Deep residual learning for image recognition” In Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
- Sepp Hochreiter “Untersuchungen zu dynamischen neuronalen Netzen” In Diploma, Technische Universität München 91.1, 1991
- “Long short-term memory” In Neural computation 9.8 MIT press, 1997, pp. 1735–1780
- Jeremy Howard “fastai” GitHub, https://github.com/fastai/fastai, 2018
- J.D. Hunter “Matplotlib: A 2D graphics environment” In Computing in Science & Engineering 9.3 IEEE COMPUTER SOC, 2007, pp. 90–95 DOI: 10.1109/MCSE.2007.55
- Plotly Technologies Inc. “Collaborative data science”, 2015 URL: https://plot.ly
- “Batch normalization: Accelerating deep network training by reducing internal covariate shift” In International conference on machine learning, 2015, pp. 448–456 pmlr
- “Inceptiontime: Finding alexnet for time series classification” In Data Mining and Knowledge Discovery 34.6 Springer, 2020, pp. 1936–1962
- Tung Kieu, Bin Yang and Christian S Jensen “Outlier detection for multidimensional time series using deep neural networks” In 2018 19th IEEE international conference on mobile data management (MDM), 2018, pp. 125–134 IEEE
- “Deep learning for extreme multi-label text classification” In Proceedings of the 40th international ACM SIGIR conference on research and development in information retrieval, 2017, pp. 115–124
- Jonathan Long, Evan Shelhamer and Trevor Darrell “Fully convolutional networks for semantic segmentation” In Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3431–3440
- “Sgdr: Stochastic gradient descent with warm restarts” In arXiv preprint arXiv:1608.03983, 2016
- Naveen Sai Madiraju “Deep temporal clustering: Fully unsupervised learning of time-domain features”, 2018
- Wes McKinney “Data Structures for Statistical Computing in Python” In Proceedings of the 9th Python in Science Conference, 2010, pp. 56–61 DOI: 10.25080/Majora-92bf1922-00a
- Ignacio Oguiza “tsai - A state-of-the-art deep learning library for time series and sequential data”, Github, 2022 URL: https://github.com/timeseriesAI/tsai
- “PyTorch: An Imperative Style, High-Performance Deep Learning Library” In Advances in Neural Information Processing Systems 32 Curran Associates, Inc., 2019, pp. 8024–8035 URL: http://papers.neurips.cc/paper/9015-pytorch-an-imperative-style-high-performance-deep-learning-library.pdf
- Xingqun Qi, Tianhui Wang and Jiaming Liu “Comparison of support vector machine and softmax classifiers in computer vision” In 2017 Second International Conference on Mechanical, Control and Computer Engineering (ICMCCE), 2017, pp. 151–155 IEEE
- “Study the influence of normalization/transformation process on the accuracy of supervised classification” In 2020 Third International Conference on Smart Systems and Inventive Technology (ICSSIT), 2020, pp. 729–735 IEEE
- Robert H Shumway, David S Stoffer and David S Stoffer “Time series analysis and its applications” Springer, 2000
- Jesper E Van Engelen and Holger H Hoos “A survey on semi-supervised learning” In Machine learning 109.2 Springer, 2020, pp. 373–440
- Vladimir Vapnik “The nature of statistical learning theory” Springer science & business media, 1999
- “Attention is all you need” In Advances in neural information processing systems 30, 2017
- Zhiguang Wang, Weizhong Yan and Tim Oates “Time series classification from scratch with deep neural networks: A strong baseline” In 2017 International joint conference on neural networks (IJCNN), 2017, pp. 1578–1585 IEEE
- Yuan Yao, Lorenzo Rosasco and Andrea Caponnetto “On early stopping in gradient descent learning” In Constructive Approximation 26.2 Springer, 2007, pp. 289–315
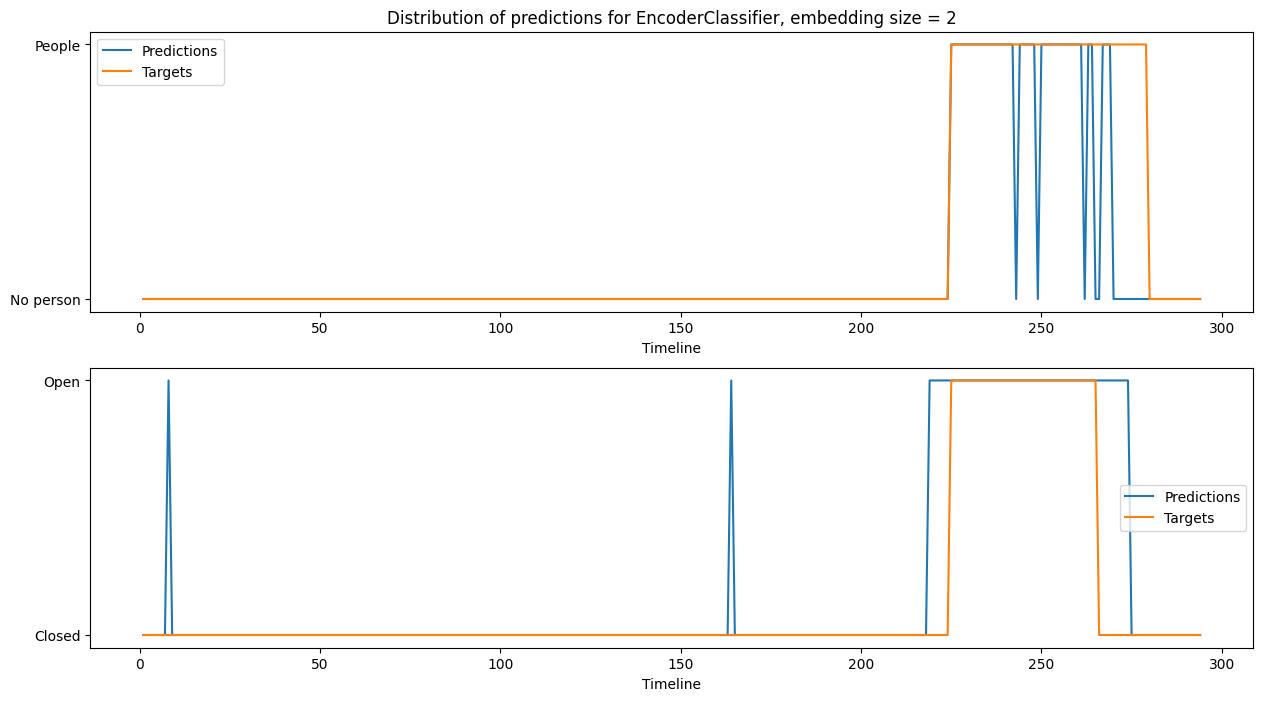
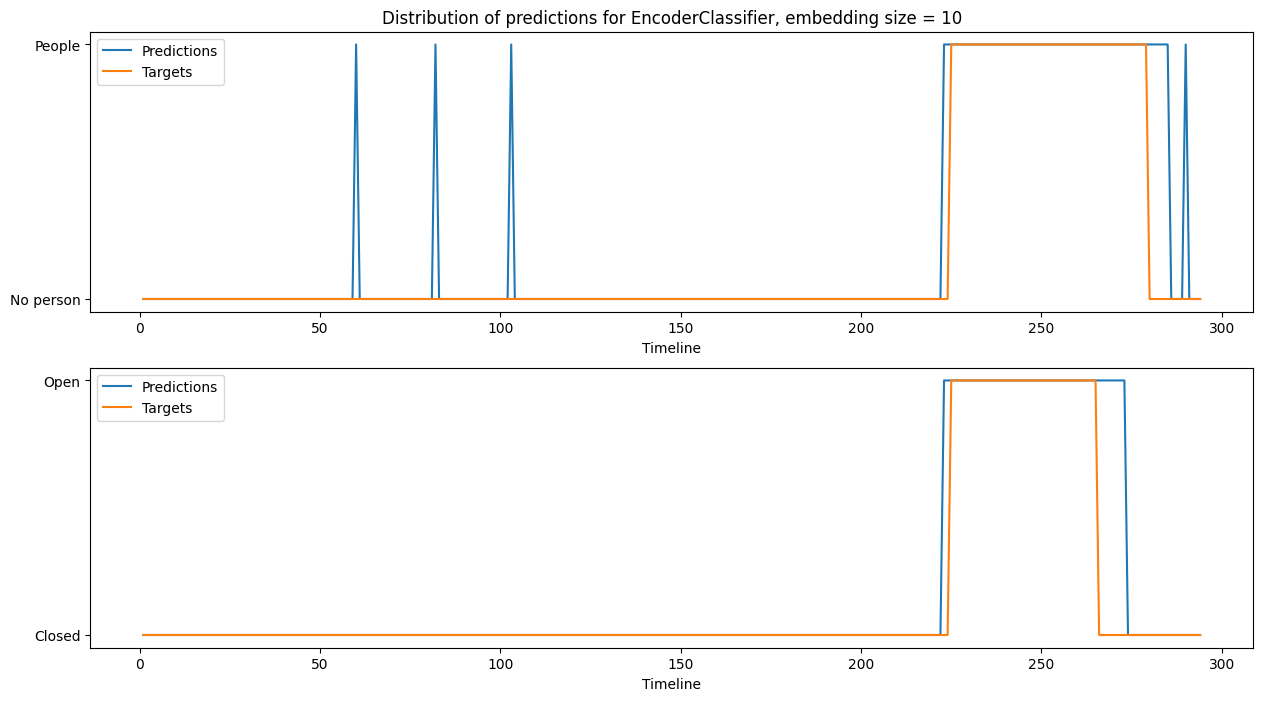
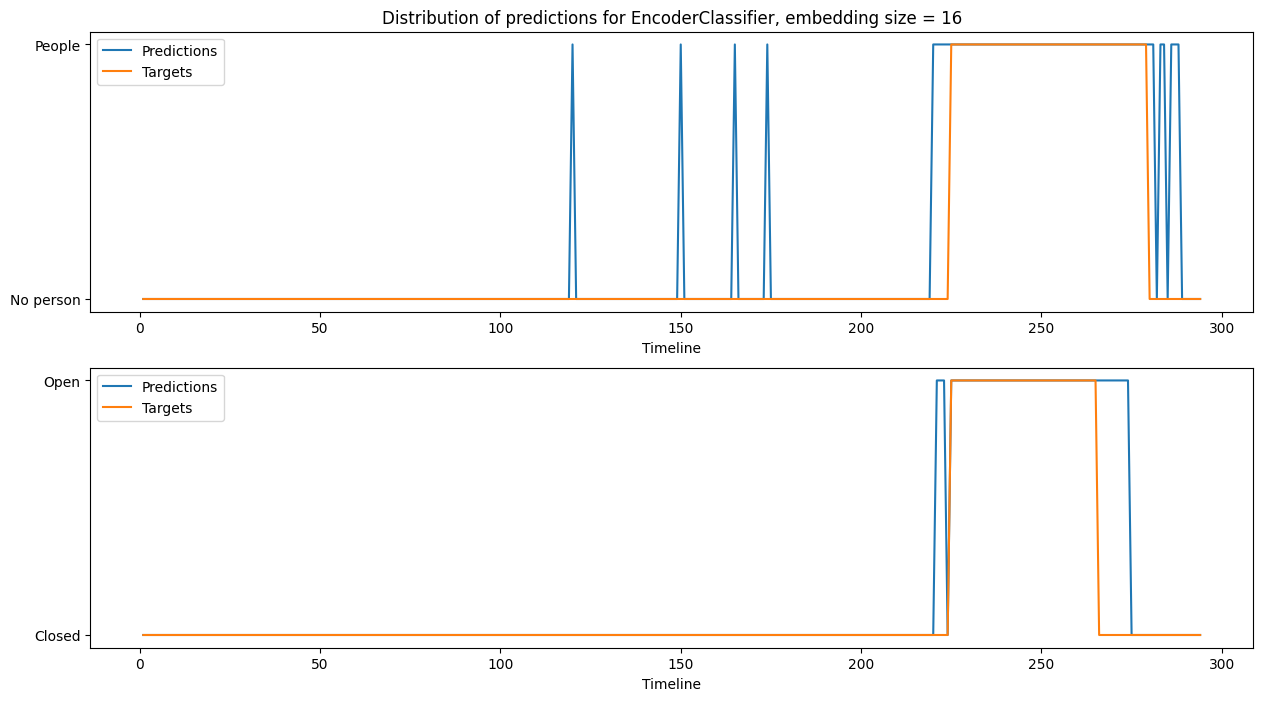
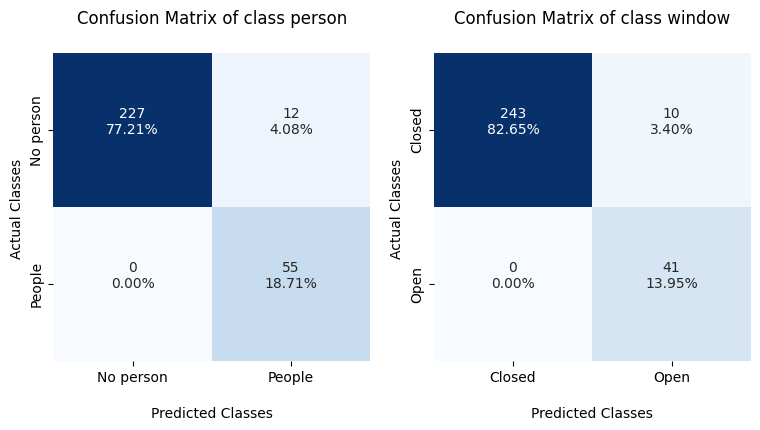
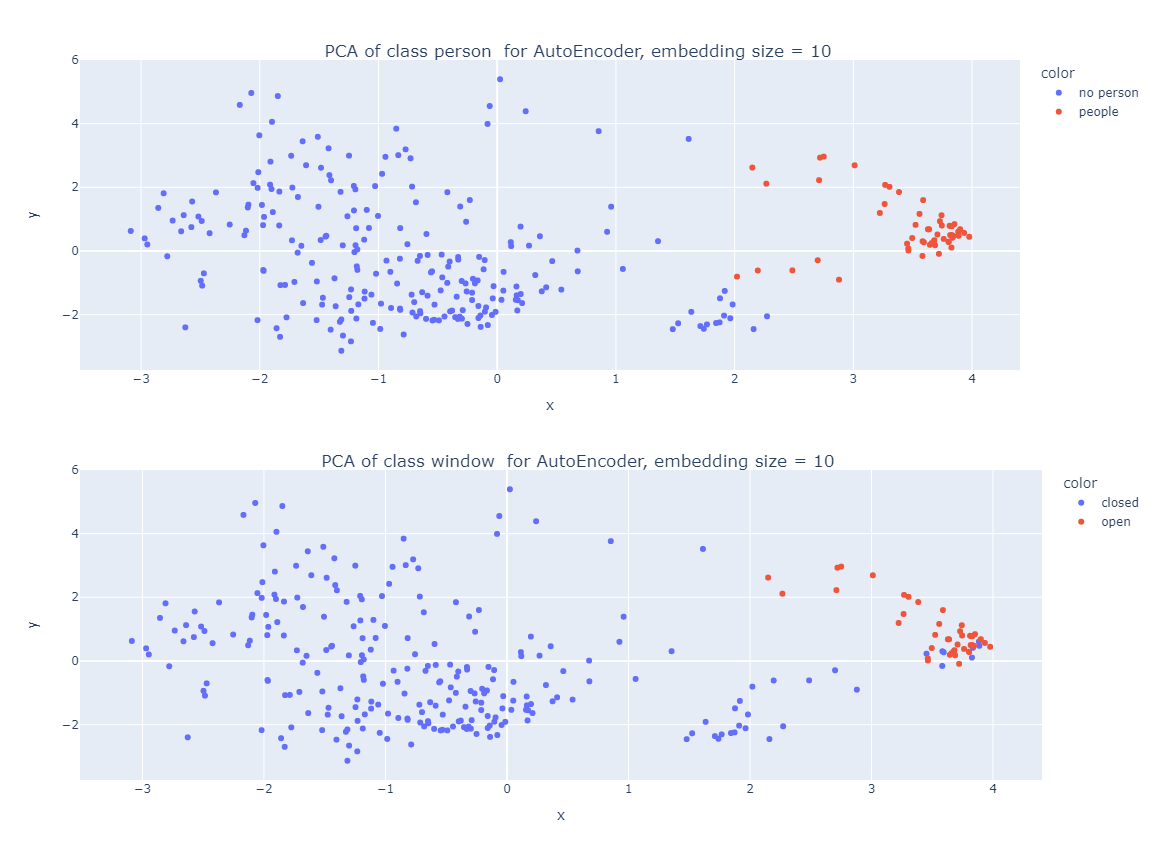
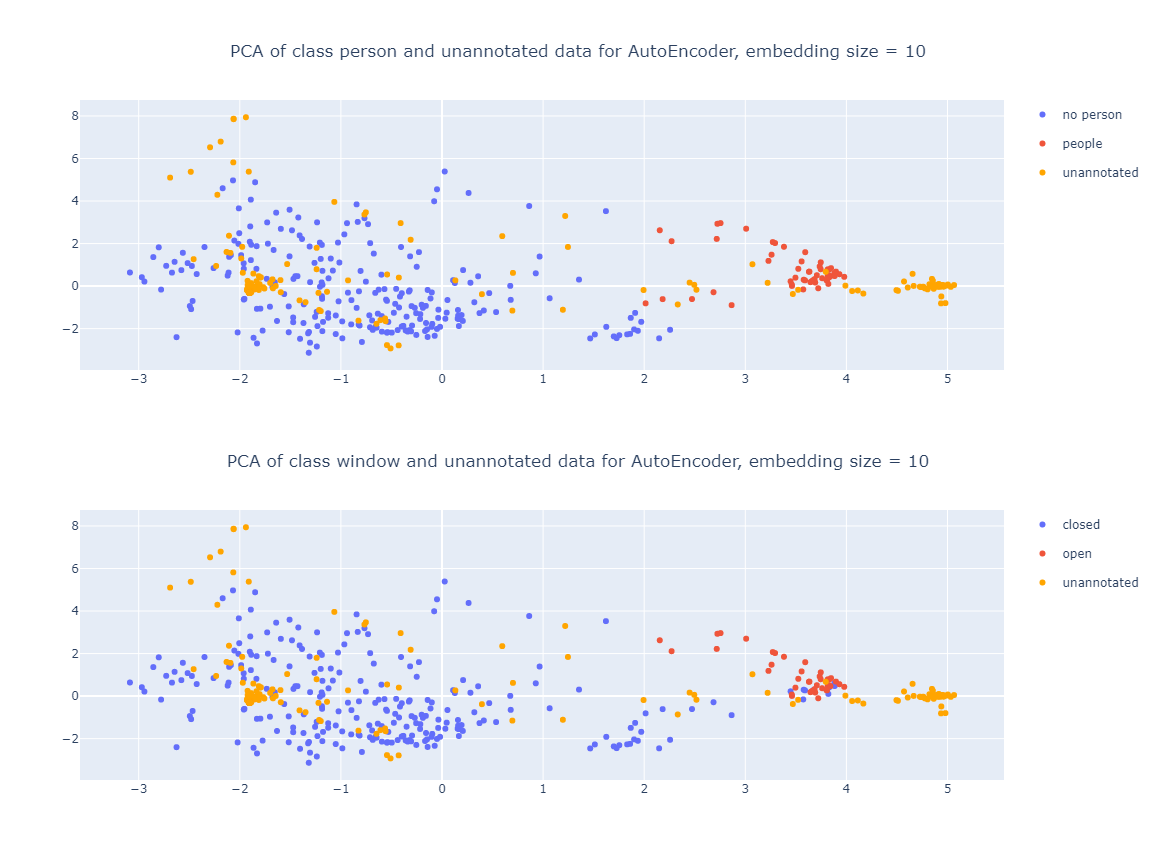
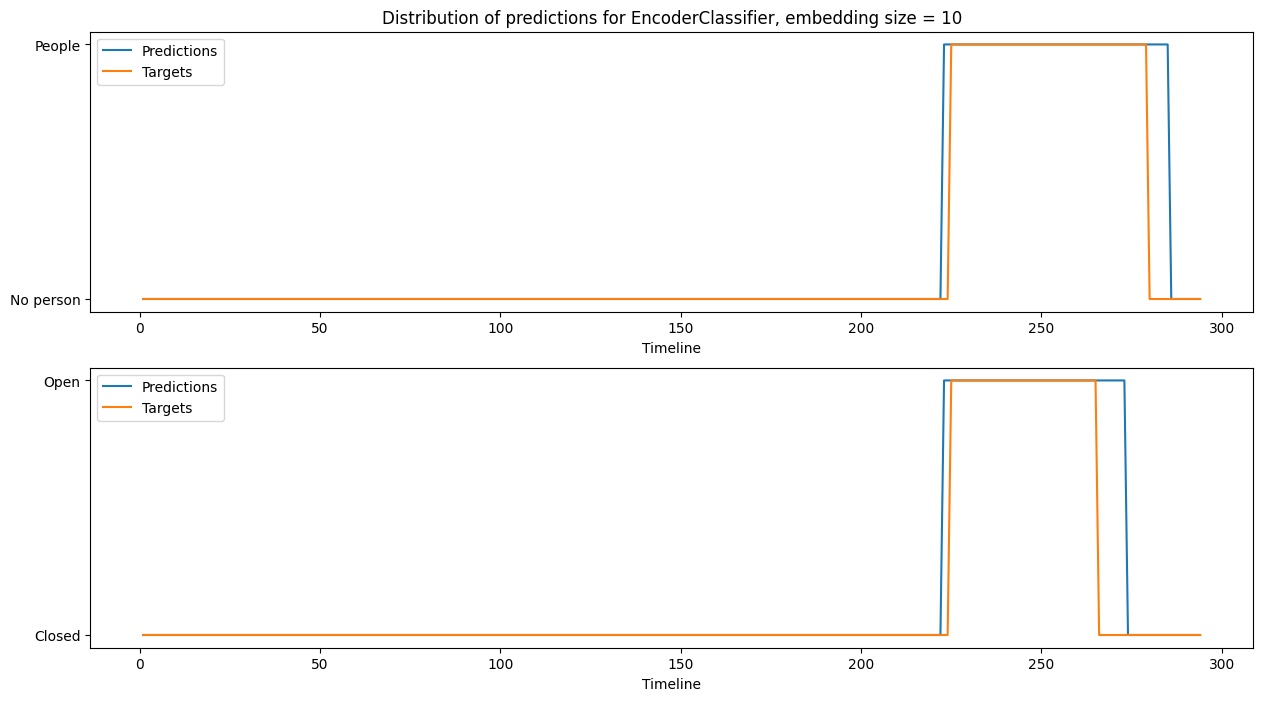
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

