- The paper introduces Trajectory Replay (TR) to sample full trajectories using backward sampling, significantly enhancing offline RL performance.
- It incorporates weighted target estimation to balance exploration and exploitation, effectively reducing sampling of out-of-distribution actions.
- Empirical evaluations on D4RL benchmarks demonstrate that prioritized trajectory replay (PTR) accelerates learning in complex, sparse reward tasks.
Prioritized Trajectory Replay: A Replay Memory for Data-driven Reinforcement Learning
The paper "Prioritized Trajectory Replay: A Replay Memory for Data-driven Reinforcement Learning" explores the significance of data sampling techniques for offline Reinforcement Learning (RL) and proposes novel methodologies to enhance the efficiency of RL algorithms. The focus lies on trajectory-based sampling as opposed to state-transition-based sampling, which has shown limited success in offline RL. The proposal introduces a memory technique, Trajectory Replay (TR) and its prioritized form (PTR), demonstrating their integration with existing offline RL algorithms on the D4RL benchmark.
Introduction to Trajectory Replay
Offline RL has garnered substantial interest due to its utility in scenarios where interaction with real environments is costly. Traditional offline RL practices primarily emphasize on conservative training algorithms and network architectures. However, data sampling, a crucial component for improving learning efficacy, remains underexplored.
This paucity of exploration in offline RL is addressed by introducing Trajectory Replay (TR), which facilitates sampling from complete trajectories rather than isolated state transitions. TR leverages backward sampling, thereby enriching the learning process with information from successive state transitions.
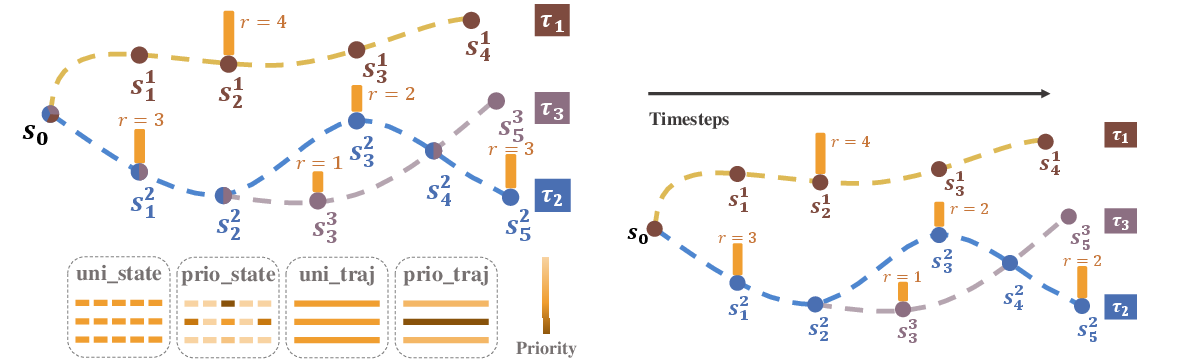
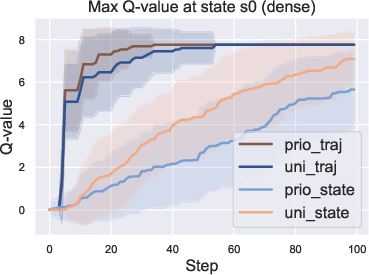
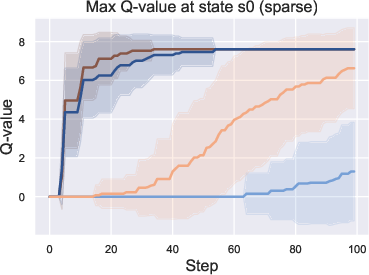
Figure 1: A motivating example on finite data. Left: The illustration of state transitions in three trajectories τi started at state s0, with the reward r for labeled state or 0 for others, and four different sampling techniques. Middle and right: Curves of the estimated maximum Q-value at state s0 learned on these three trajectories. The solid line is the averaged value over 50 seeds, and the shaded area the standard variance. The oracle value, taking into account the discount factor, is slightly less than 8.
Implementation of Prioritized Trajectory Replay
Trajectory Replay: Backward Sampling Strategy
TR stores offline data as trajectories and implements backward sampling of these trajectories. This approach allows for accelerated reward propagation, which is particularly advantageous in sparse reward environments. The backward sampling of TR is effectively illustrated in the backward sampling process, where the last state transitions are sampled first, allowing earlier states to leverage the learned knowledge from later states.
Weighted Target Estimation
To address extrapolation errors, which are significant challenges in offline RL, TR is extended by formulating a weighted target estimation. This extension combines the standard Q-learning update with a SARSA-style update, balancing exploration and exploitation while averting sampling of out-of-distribution (OOD) actions.
Prioritized Trajectory Sampling Metrics
Building on TR, the introduction of Prioritized Trajectory Replay (PTR) enhances sampling efficiency by utilizing various trajectory priority metrics. These include trajectory quality metrics (e.g., reward mean) and uncertainty measures. Theoretical criticism prioritizes the sampling efficiency through probabilistic selections based on these trajectory attributes.
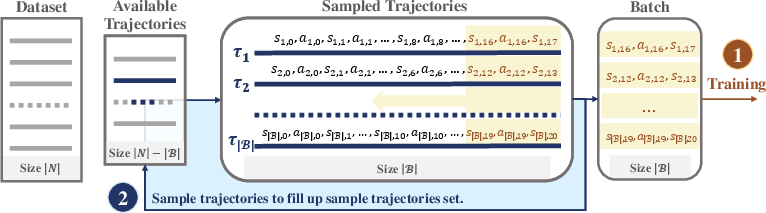
Figure 2: Overview of the process of data sampling based on Trajectory Replay.
Experimental Evaluation
Empirical evaluations performed on D4RL benchmarks, consisting of Mujoco, Adroit, and AntMaze datasets, demonstrate significant improvements when TR and PTR are applied. The backward sampling in TR notably benefits sparse reward tasks, as evidenced by increased normalized scores on these datasets. Moreover, PTR, utilizing prioritized sampling, further boosts performance, with reward quality and uncertainty effectively guiding trajectory prioritization in different environments.
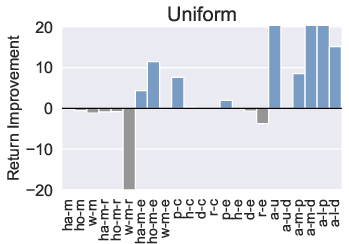
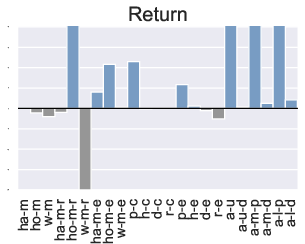
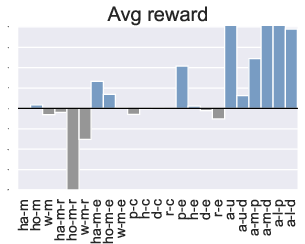
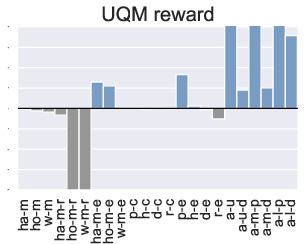
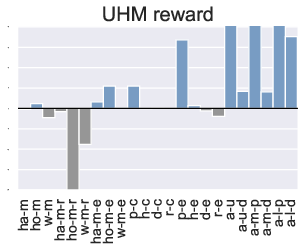
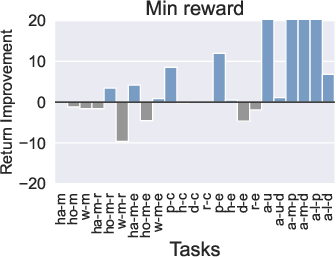
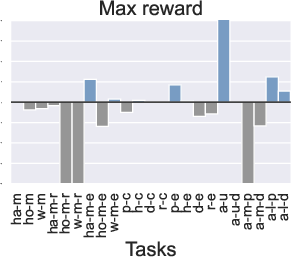
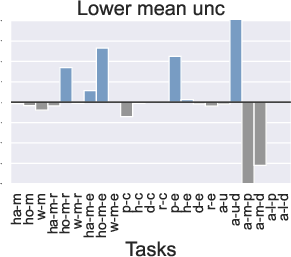
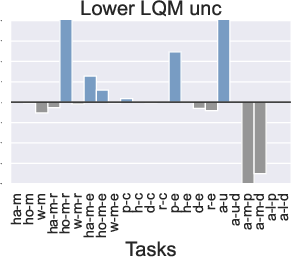
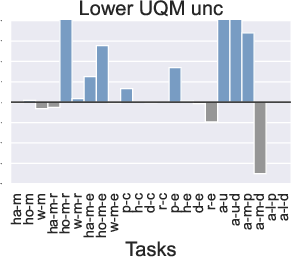
Figure 3: Comparison of the performance of PTR compared to TD3+BC under 10 different trajectory priority metrics. In the figure we restrict the performance difference to a maximum of 20.
Computationally, PTR incurs slightly higher costs, primarily due to trajectory maintenance and priority updates, yet these are justified by the substantial gains in learning efficiency.
Conclusion
The paper underscores the importance of trajectory-based sampling techniques in offline RL, introducing Trajectory Replay (TR) and its prioritized variant (PTR) as versatile tools for improving algorithm performance. While demonstrating remarkable practical advancements, this work opens avenues for refining trajectory prioritization metrics and exploring enhancements in target computation methods. The integration of these techniques with complex RL frameworks holds promise for advancing data-driven AI capabilities in various domains.