- The paper demonstrates that LLMs, particularly GPT-4, perform competitively in KG construction and excel in reasoning tasks, sometimes outperforming fine-tuned models.
- The paper employs comprehensive experiments across eight datasets to assess zero-shot and one-shot performances, revealing both strengths and limitations of current LLMs.
- The paper introduces innovative concepts such as Virtual Knowledge Extraction and AutoKG, paving the way for automated knowledge graph construction using multi-agent systems.
LLMs for Knowledge Graphs: Capabilities and Opportunities
The paper explores the application of LLMs such as GPT-4 in the construction and reasoning of Knowledge Graphs (KGs). It conducts comprehensive experiments to evaluate the efficacy of LLMs across several tasks pertinent to KGs, such as entity and relation extraction, event extraction, link prediction, and question answering. The findings also lay the groundwork for future research avenues, including the introduction of a novel task named Virtual Knowledge Extraction and the proposition of an automated framework (AutoKG) utilizing multi-agent systems.
Evaluative Overview of LLMs
The study methodically evaluates the capabilities of GPT-4 and other models like ChatGPT in KG-related tasks, comparing their zero-shot and one-shot performances against fully supervised state-of-the-art (SOTA) models. The evaluation spans eight datasets, providing a granular insight into each model's competency for both KG construction and reasoning.
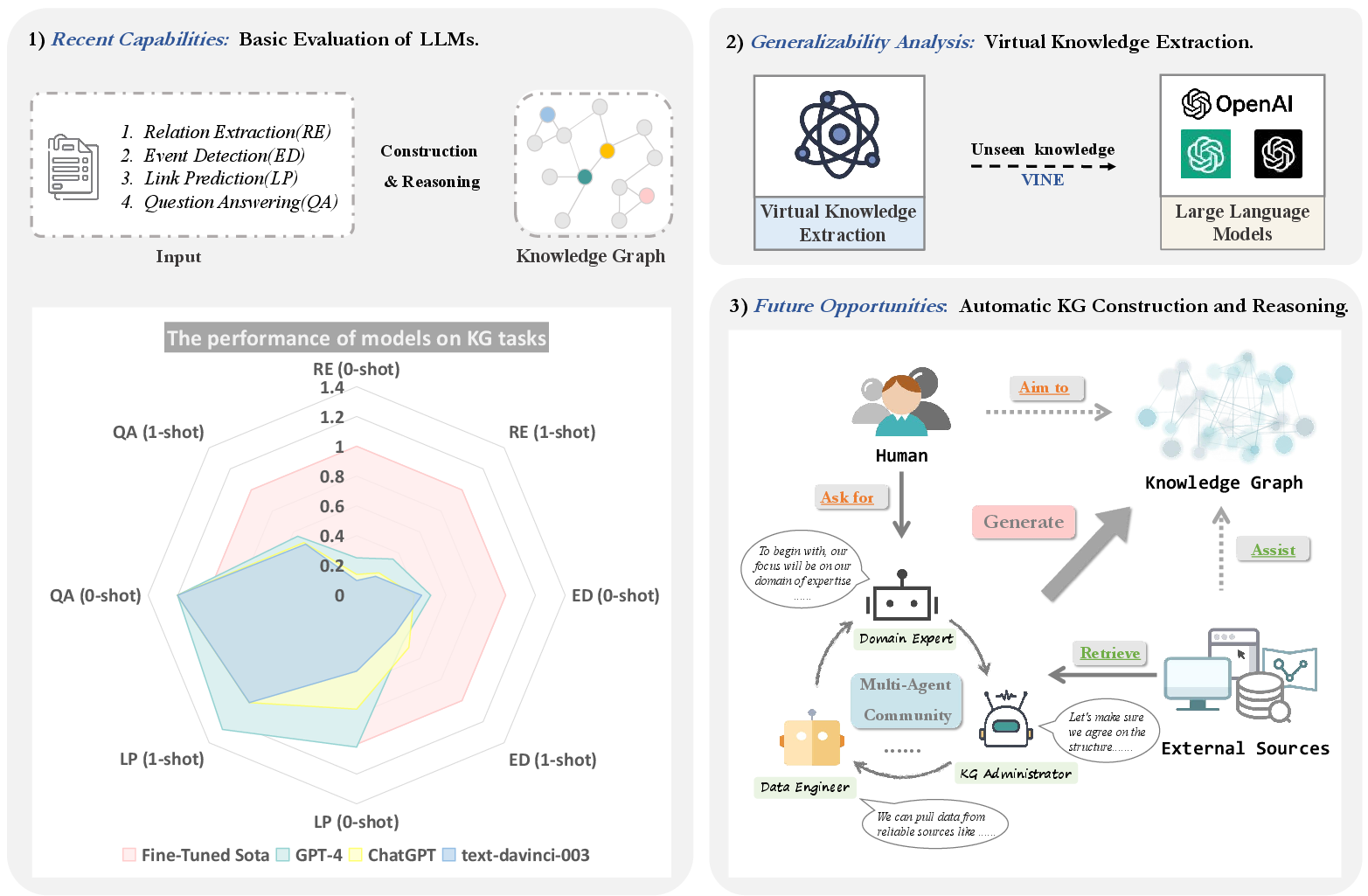
Figure 1: Overview of the methodology and components: evaluation of models, virtual knowledge extraction, and automatic KG proposal.
The quantitative analysis reveals that while GPT-4 exhibits competent performance in KG construction tasks, it particularly excels in reasoning tasks, on occasion even outperforming fine-tuned models. Such observations are based on benchmark datasets such as SciERC and Re-TACRED, alongside new synthetic data setups.

Figure 2: Performance examples of ChatGPT and GPT-4 across various datasets illustrating different extraction scenarios.
Exploring Generalization and Virtual Knowledge
A significant inquiry within the paper involves determining whether the capabilities observed in LLMs are due to their memorization of extensive pre-trained data or their inherent generalization ability. To this end, the concept of Virtual Knowledge Extraction is introduced, along with the construction of a synthetic dataset named VINE. Results show that models like GPT-4 possess notable abstraction and generalization capabilities, augmenting their adaptability to previously unseen data.

Figure 3: Prompts used in Virtual Knowledge Extraction, exhibiting the capability to handle novel conceptual data.
Future Directions: AutoKG and Multi-Agent Systems
The research explores the potential of constructing KGs using a fully automated process, termed AutoKG, which employs multiple interactive agents. These agents, relying on LLMs' core competencies, are designed to communicate and collaborate to build and reason over KGs. Through an iterative dialogue mechanism and external knowledge sourcing, AutoKG represents a step toward improving efficiency and adaptability in KG-related tasks.

Figure 4: Schematic of AutoKG, outlining the interaction between agents and integration with LLMs for enhanced KG tasks.
Conclusion
The paper effectively demonstrates the considerable promise held by LLMs in enhancing knowledge graph construction and reasoning. It highlights the critical role of LLMs as inference tools rather than pure information retrieval agents. Furthermore, the proposition of AutoKG provides a glimpse into how AI-driven agent systems could revolutionize KG ecosystems. Future research endeavors will likely explore multimodal inputs and further automatize these processes, addressing current challenges such as the token limit in APIs and ensuring factual accuracy.