Autonomic Architecture for Big Data Performance Optimization
Abstract: The big data software stack based on Apache Spark and Hadoop has become mission critical in many enterprises. Performance of Spark and Hadoop jobs depends on a large number of configuration settings. Manual tuning is expensive and brittle. There have been prior efforts to develop on-line and off-line automatic tuning approaches to make the big data stack less dependent on manual tuning. These, however, demonstrated only modest performance improvements with very simple, single-user workloads on small data sets. This paper presents KERMIT - the autonomic architecture for big data capable of automatically tuning Apache Spark and Hadoop on-line, and achieving performance results 30% faster than rule-of-thumb tuning by a human administrator and up to 92% as fast as the fastest possible tuning established by performing an exhaustive search of the tuning parameter space. KERMIT can detect important workload changes with up to 99% accuracy, and predict future workload types with up to 96% accuracy. It is capable of identifying and classifying complex multi-user workloads without being explicitly trained on examples of these workloads. It does not rely on the past workload history to predict the future workload classes and their associated performance. KERMIT can identify and learn new workload classes, and adapt to workload drift, without human intervention.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves several aspects insufficiently specified or evaluated. Future work could address the following concrete gaps:
- Experimental methodology is under-specified: no details on cluster size/topology, hardware, Spark/Hadoop versions, dataset characteristics, workload mix, and multi-tenant contention used to obtain the reported performance and accuracy numbers.
- Scope of evaluation is unclear for “complex multi-user workloads”: no rigorous experiments demonstrating identification/classification under realistic concurrent interference, heterogeneous job mixes, and bursty arrivals.
- No baseline comparisons beyond “rule-of-thumb” and exhaustive search: missing head-to-head evaluation against modern autotuners, Bayesian optimization, bandit-based tuning, or gradient-free search methods for high-dimensional Spark/Hadoop configs.
- “Explorer” search algorithm lacks formal analysis: no complexity/scaling guarantees, convergence criteria, worst-case search cost, or safety constraints when exploring high-dimensional parameter spaces.
- Unspecified feature vector
𝔉_t: the paper does not define the exact metrics, measurement sources, aggregation functions, and normalization used in observation windows; no sensitivity analysis to feature selection. - Observation windowing is not justified: no rationale or empirical study for window length, stride, and their impact on detection/classification/prediction accuracy or latency.
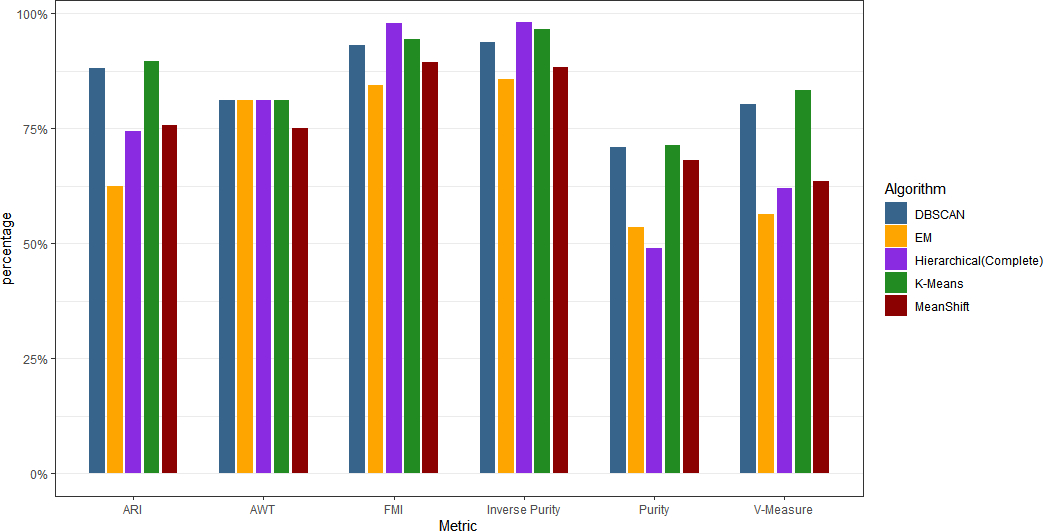
- DBSCAN hyperparameters are not addressed: how
epsandminPtsare selected, tuned, or adapted; robustness to parameter choices and cluster shape; handling noise/outliers in workload clustering. - Drift detection via L2 distance of mean vectors may be insufficient: no treatment of covariance shifts, heavy tails, multimodality, or temporal dependence; lack of comparison to other drift detectors or adaptive thresholds.
- Welch’s test in
ChangeDetectormay violate time-series assumptions: no assessment of autocorrelation effects, non-stationarity, or multiple-comparison false positives in streaming settings. - Synchronization risk between plugin and monitor: when desynchronization occurs, the system defaults to a generic config without recovery strategy, impact assessment, or mitigation plan.
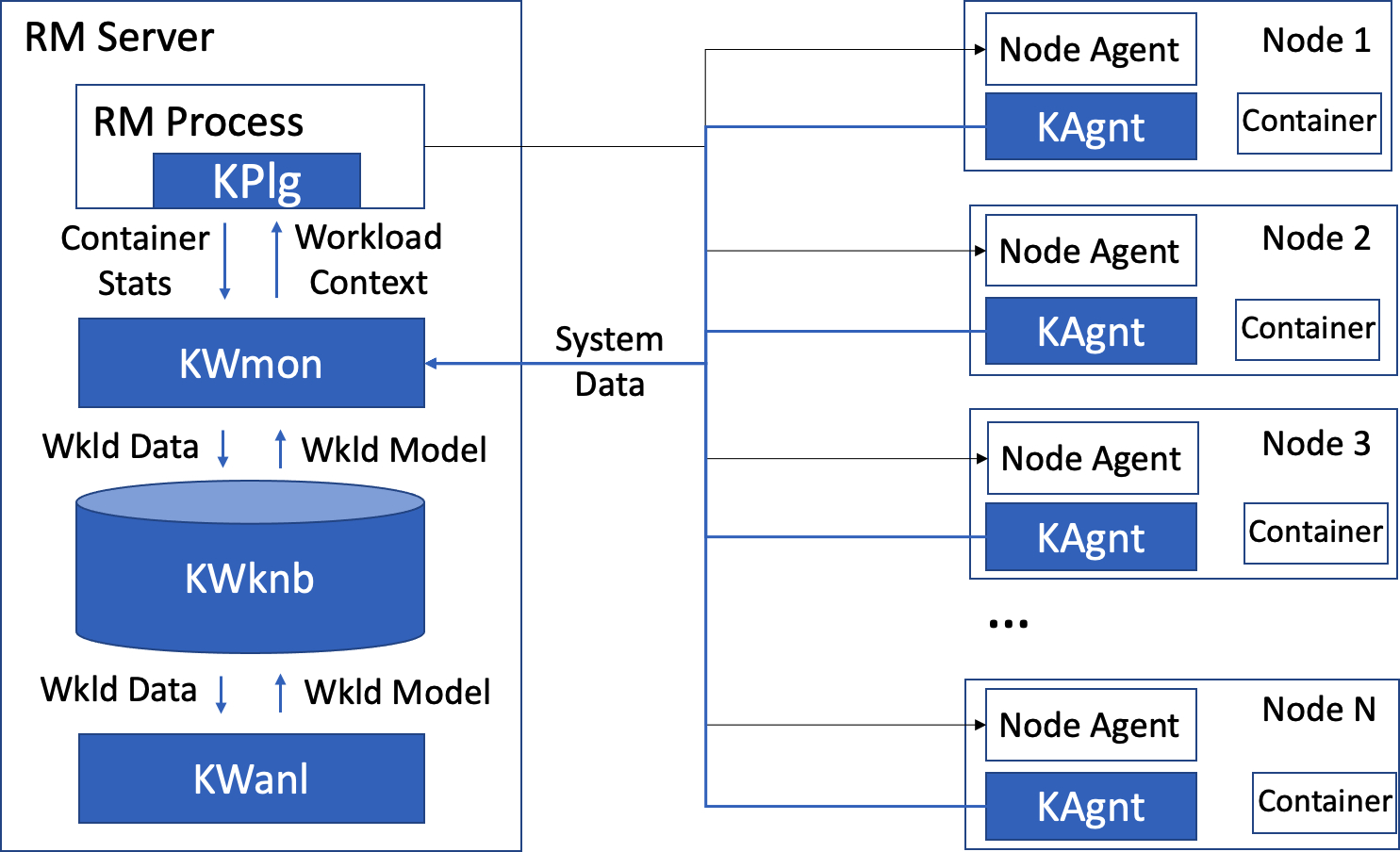
- Overhead of KERMIT components is unquantified: CPU/memory/network costs of
KAgnt,KWmon,KWanl, streaming ingestion, and off-line pipelines; impact on job latency and cluster throughput under load. - Online tuning safety is not discussed: which parameters are modified at runtime, whether changes force job restarts or violate application correctness (e.g., executor memory/parallelism adjustments causing OOM or skew).
- Interaction with resource managers is narrow: integration details are provided for one RM plugin; generalization to YARN, Kubernetes, and standalone Spark/Hadoop (and their scheduling/fairness policies) is untested.
- Multi-objective trade-offs are ignored: KERMIT optimizes “performance” without addressing cost, energy, fairness among users, SLA adherence, or tail-latency minimization; no policy mechanism to balance objectives.
- Adaptation speed vs. stability is unstudied: risk of thrashing under frequent drift, oscillations between configs, or repeated searches; need for dampening/cooldown policies and rollback mechanisms.
- Workload anticipation “when” and “which” claims lack specifics: prediction horizons, uncertainty estimates, and triggering criteria for proactive reconfiguration are not quantified or validated.
- Zero-shot/few-shot synthetic class generation is under-evaluated: potential combinatorial explosion of hybrid classes, criteria for synthesis, calibration of synthetic prototypes, and empirical validation in noisy, real multi-user environments.
- Training data quality and label noise risks: automated labeling relies on clustering and change detection; no error-analysis or mitigation for mislabeling cascades into supervised models.
- Off-line pipeline scheduling is undefined: resource allocation, retraining frequency, handling of stale models, and consistency guarantees between training batches and online deployment.
- WorkloadDB lifecycle management is missing: retention policies, compaction, versioning across Spark/Hadoop releases, cross-cluster sharing, and privacy/security controls for stored workload signatures/configs.
- Security and adversarial robustness are only hinted: potential poisoning by crafted workloads, denial-of-service via forced drift, and defenses for the knowledge base and controllers are not addressed.
- Scalability to heterogeneous clusters is not shown: varying node capacities, tiered storage, network bottlenecks, and rack-awareness impacts on feature vectors and tuning decisions.
- Generalization beyond Spark/Hadoop is unproven: claims of broad applicability to Hive/HBase/Tez or other analytics frameworks lack integration specifics and empirical validation.
- Parameter selection strategy is opaque: the mapping from workload characteristics to the subset of tunable parameters (among hundreds in Spark/Hadoop) is not formalized; no feature-to-parameter attribution.
- Impact on correctness and reproducibility is not discussed: assurance that tuned configurations preserve semantic equivalence, determinism, and compliance with application-level constraints.
- Reproducibility artifacts are absent: no code, datasets, configuration sets, or detailed protocols for independent verification of the reported gains and accuracies.
- Handling of long-running streaming jobs is unclear: how continuous workloads with evolving states, caches, and checkpoints are detected, classified, and tuned without disruption.
- Failure management is partial: beyond recognizing changed workload features after node loss, there is no integration with cluster auto-repair, capacity rebalancing, or controller failover strategies.
- Governance and policy controls are missing: auditability of changes, approval workflows, per-tenant quotas, and guardrails for safe tuning in regulated or mission-critical environments.
Collections
Sign up for free to add this paper to one or more collections.