Optimal Goal-Reaching Reinforcement Learning via Quasimetric Learning
Published 3 Apr 2023 in cs.LG | (2304.01203v7)
Abstract: In goal-reaching reinforcement learning (RL), the optimal value function has a particular geometry, called quasimetric structure. This paper introduces Quasimetric Reinforcement Learning (QRL), a new RL method that utilizes quasimetric models to learn optimal value functions. Distinct from prior approaches, the QRL objective is specifically designed for quasimetrics, and provides strong theoretical recovery guarantees. Empirically, we conduct thorough analyses on a discretized MountainCar environment, identifying properties of QRL and its advantages over alternatives. On offline and online goal-reaching benchmarks, QRL also demonstrates improved sample efficiency and performance, across both state-based and image-based observations.
The paper introduces a novel QRL method that uses quasimetric structures to optimize goal-conditioned value functions in reinforcement learning.
The paper provides rigorous theoretical guarantees, showing an O(√ε) approximation of the optimal value function under varied function approximations.
The paper demonstrates that QRL outperforms traditional RL methods in offline and online benchmarks with improved convergence and sample efficiency.
Optimal Goal-Reaching Reinforcement Learning via Quasimetric Learning
The paper "Optimal Goal-Reaching Reinforcement Learning via Quasimetric Learning" introduces Quasimetric Reinforcement Learning (QRL), a novel method for goal-reaching tasks in reinforcement learning (RL) that exploits quasimetric structures to learn optimal value functions. The authors present a unique approach that integrates quasimetric models into RL to provide strong theoretical guarantees and empirical improvements.
Introduction
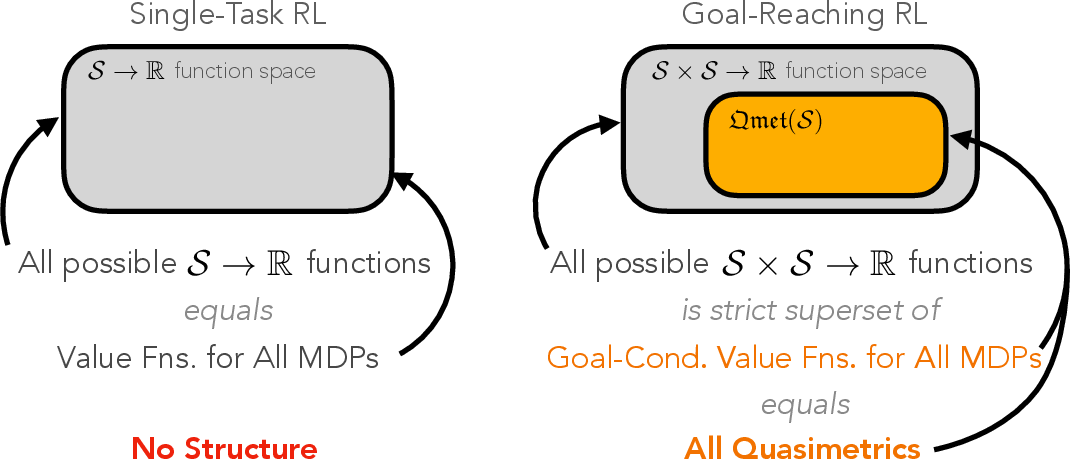
In RL, the value function plays a central role by modeling the cost-to-go function, a critical component of decision-making algorithms. In traditional single-goal RL, value functions V∗(s) can represent any real-valued function V∗:S→R, where S is the state space. However, in multi-goal settings, the optimal value function assumes a quasimetric structure, which respects the triangle inequality and can accommodate asymmetries found in many real-world dynamics.
Figure 1: In multi-goal RL, the set of all possible (optimal) value functions is exactly the set of \qmetC{quasimetrics.
Quasimetric Reinforcement Learning
Objective Function
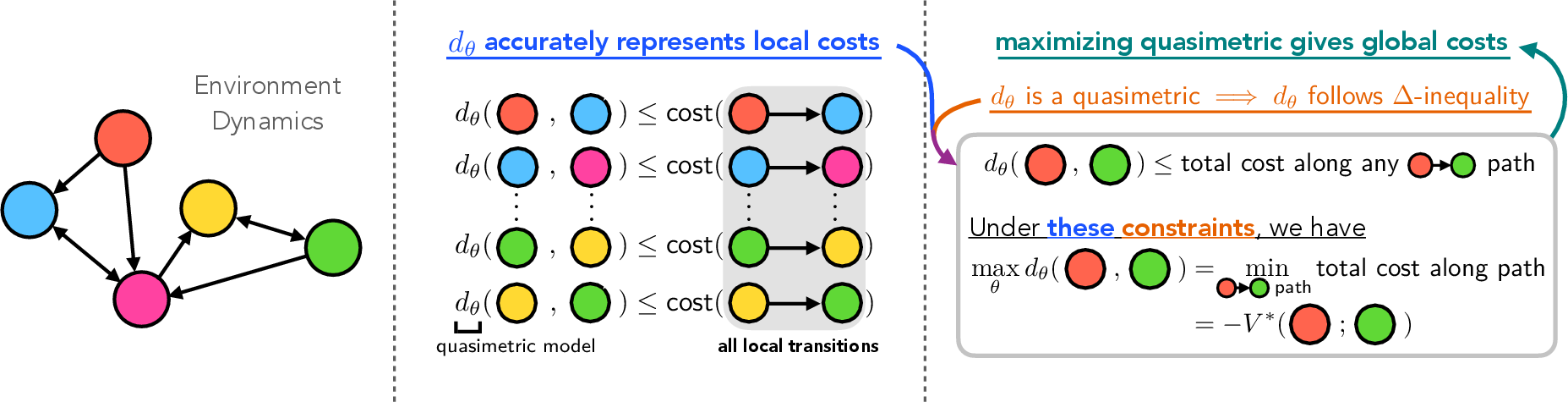
QRL seeks to optimize a quasimetric model $d_\theta \in \mqmet(\mathcal{S})$ to learn the optimal goal-conditioned value functionV∗. The process involves maximizing the expected quasimetric distance from current states to goal states:
θmaxEs∼pstate,g∼pgoal[dθ(s,g)]
While ensuring that the local transition costs are modeled accurately:
∀(s,a,s′,r)transition,relu(dθ(s,s′)+r)2≤ϵ2
This objective exploits the inherent triangle inequality properties of quasimetric models, facilitating the accurate modeling of the optimal cost-to-go.
Figure 2: QRL objective finds length of the shortest path connecting two states, \ie, the \optC{optimal value.
Theoretical Guarantees
The paper provides rigorous proofs demonstrating how QRL guarantees recovery of the optimal value function under both idealized and realistic function approximation scenarios. Theoretical results confirm that optimizing over the space of quasimetrics yields O(ϵ) approximations of the optimal value.
Experimental Analysis
QRL is evaluated in both offline and online settings across various benchmarks. Results show that QRL significantly outperforms traditional methods, including Q-Learning and Contrastive RL, in terms of learning speed, sample efficiency, and final performance.
Offline Experiments
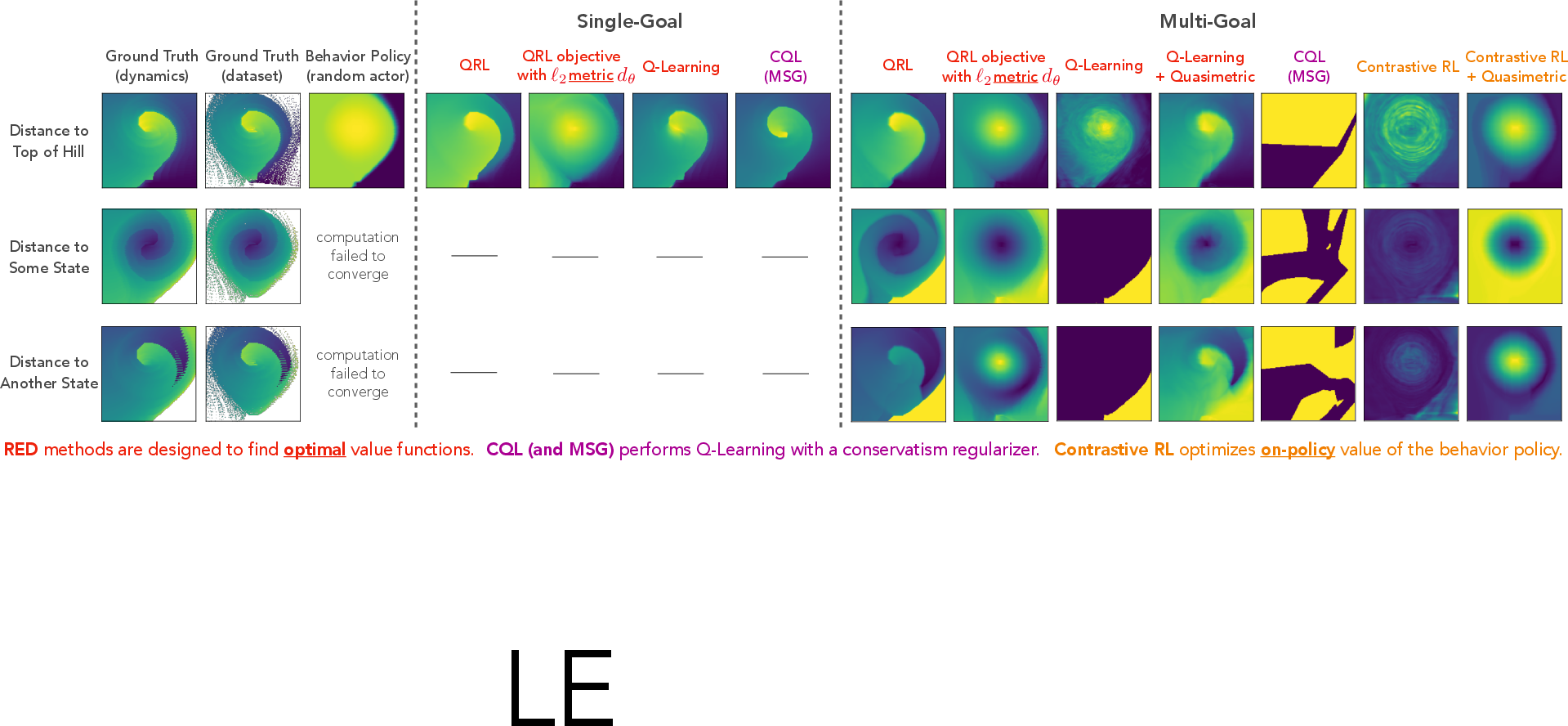
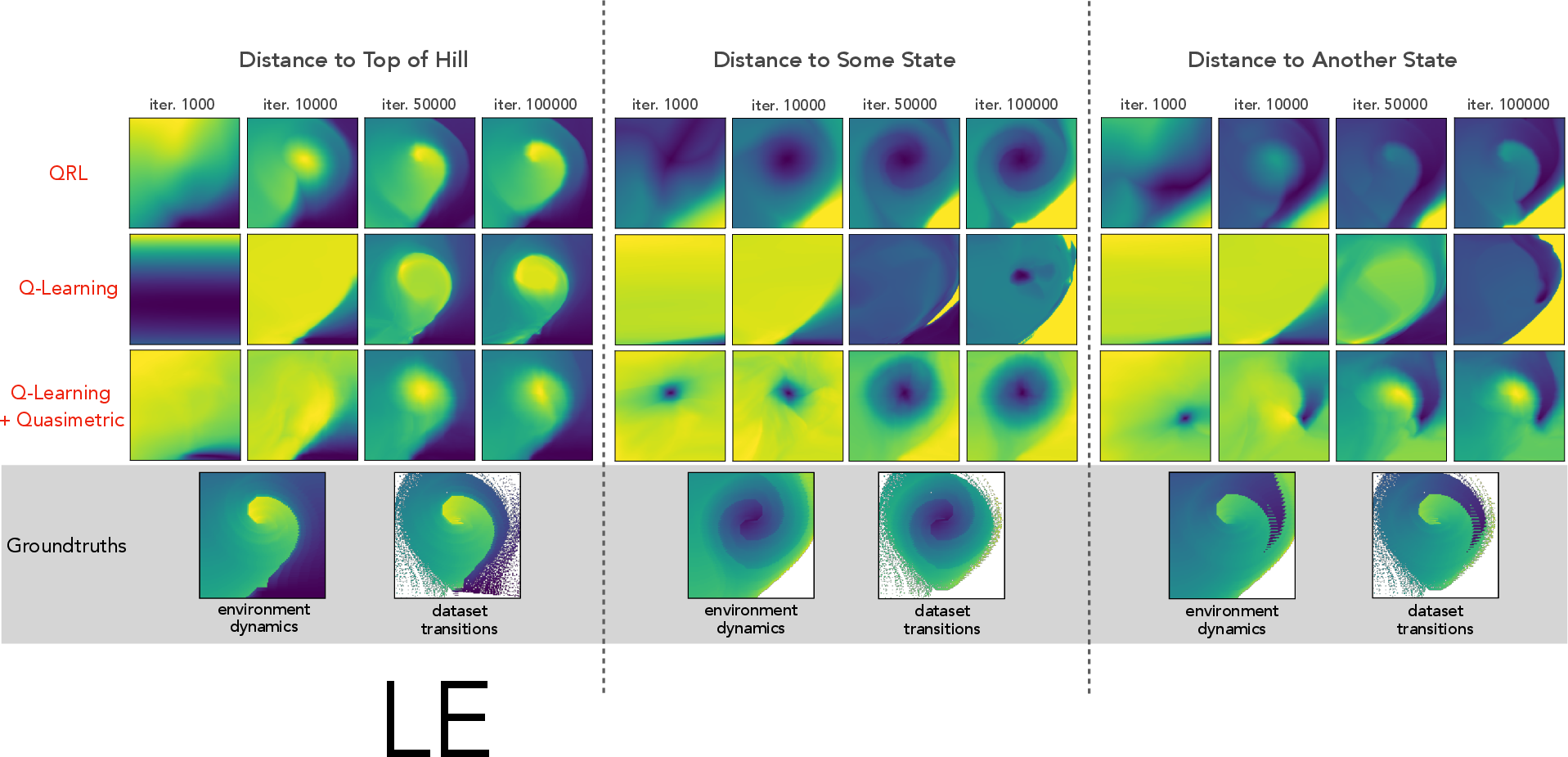
In offline environments such as the discretized \mntcar setting, QRL demonstrates faster convergence and superior value function accuracy compared to Q-Learning variants.
Figure 3: Learned value functions on offline \mntcar. Each plot shows the estimated values from every state towards a single goal.
Online Experiments
On GCRL benchmarks involving the Fetch robot, QRL again exhibits improved sample efficiency even without access to the ground truth reward function, maintaining robust performance across state-based and image-based observations.
Figure 4: Online learning performance on GCRL benchmarks. QRL learns faster and better than baseline methods.
Extensions and Future Directions
Transition and Policy Learning
QRL can be extended to learn optimal Q-functions and policies. The authors propose using quasimetric models to parametrize transitional dynamics, which allows direct estimation of optimal Q-values, providing a robust framework for policy optimization.
Implications
The use of quasimetric models highlights the potential for developing RL algorithms that can inherently account for asymmetrical and geometric properties of environments, possibly leading to more efficient exploration and improved generalization.
Conclusion
"Optimal Goal-Reaching Reinforcement Learning via Quasimetric Learning" demonstrates a compelling approach to leveraging geometric properties in RL, providing both theoretical and empirical enhancements over conventional methods. The implications of integrating quasimetric learning into RL frameworks indicate promising directions for future research in model-based planning and sample-efficient learning.