- The paper introduces a large-scale corpus with over 45K human-annotated propositions for enhanced proposition-level analysis in NLI.
- It employs flexible token subset representation and models like T5 and BERT to improve segmentation accuracy and entailment classification.
- The dataset facilitates applications like hallucination detection and cross-domain generalization, advancing nuanced text understanding.
PropSegmEnt: A Large-Scale Corpus for Proposition-Level Segmentation and Entailment Recognition
Introduction
The paper "PropSegmEnt" introduces a comprehensive corpus aimed at enhancing Natural Language Inference (NLI) by recognizing textual entailment at the proposition level, rather than the conventional sentence or paragraph level. The dataset, named PROPSEGMENT, consists of over 45K human-annotated propositions, which are evaluated for entailment with respect to topically aligned documents. This corpus serves as a significant tool for improving the granularity and accuracy of entailment recognition in NLI tasks.
Dataset and Methodology
Corpus Construction
PROPSEGMENT features document clusters from WIKIPEDIA and news sources, with each cluster containing related documents. The dataset is designed to facilitate two primary tasks:
- Propositional Segmentation (T1): A system must identify and segment meaningful propositions within a sentence.
- Propositional Entailment (T2): Each proposition is classified as either entailed, neutral, or contradicted by a document from the same cluster.
This segmentation is done by expert annotators who label the propositions based on token subsets within sentences.
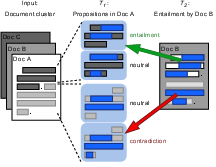
Figure 1: Task overview for propositional segmentation and entailment classification within document clusters.
Proposition Representation
Unlike conventional methods, which rely on predicate-argument structures, PROPSEGMENT adopts a more flexible approach that represents propositions as subsets of tokens in a sentence. This is to address the granularity mismatches seen with OpenIE and SRL systems, enabling a comprehensive extraction of propositions for entailment evaluation.
Modeling and Baselines
The authors establish baseline models for both segmentation and entailment tasks using Seq2Seq frameworks like T5 and encoder-tagger models like BERT. The Seq2Seq models outperform the simpler BERT baseline, suggesting the importance of modeling the joint probability of proposition outputs.
Evaluation Metrics
For propositional segmentation, the performance is measured using precision, recall, and F1 scores, with Jaccard similarity applied to assess the matching between predicted and gold propositions. For entailment, the accuracy and balanced accuracy metrics are employed, given the label imbalance in the dataset.
Applications and Analysis
Hallucination Detection
One of the proposed applications of PROPSEGMENT is in detecting hallucinations in text summarization. The proposition-level entailment allows for identifying unfaithful content in summaries by analyzing non-entailed propositions.
Cross-Domain Generalization
The paper investigates cross-domain generalization by evaluating model performance on unseen domains. It reveals how the model can maintain performance across syntactically and semantically varied documents from both Wikipedia and news domains.
Conclusion
PROPSEGMENT marks a pivotal advancement in NLI by promoting the proposition-level analysis of entailment relationships. The dataset not only aids in developing more nuanced models for understanding text but also holds promise for applications in hallucination detection and document comparison tasks. Future exploration could involve more balanced contradiction examples and applications to broader text classification tasks.