- The paper establishes convergence rates, robustness, and computational guarantees for Sliced Wasserstein distances in high-dimensional spaces.
- It shows that empirical convergence adapts to sample size and effective dimensionality while maintaining dimension-free robust estimation risks.
- The authors propose efficient computational methods, including Monte Carlo integration and subgradient optimization, to overcome non-convexity challenges.
Statistical, Robustness, and Computational Guarantees for Sliced Wasserstein Distances
Introduction
"Sliced Wasserstein distances" offer a potential solution to the computational challenges faced by the classic Wasserstein distances, especially in high-dimensional spaces. This paper aims to quantify the benefits of using Sliced Wasserstein distances from three perspectives: statistical convergence, robustness to data contamination, and computational efficiency. The sliced version of Wasserstein distances considered here are defined based on the average and maximum Wasserstein distances over one-dimensional projections of high-dimensional distributions. The paper derives explicit empirical convergence rates with dependencies on dimensionality, provides robust estimation risks that are dimension-independent, and furnishes computational methods with formal guarantees for efficient calculation.
Empirical Convergence
The paper provides convergence rates for the empirical Sliced Wasserstein distances that reveal their scalability in high-dimensional settings. These distances exploit projections to lower dimensions, which allows them to mitigate the usual dimensionality curse encountered with classical Wasserstein distances.
For distributions that are log-concave, it is shown that both average- and max-sliced Wasserstein distances exhibit convergence rates dependent on the sample size and the effective dimensionality (rank) of the data's covariance matrix. Specifically, the distance decays as O(n−1/max{2,p}) given n samples, adapting well to the structure of the data.
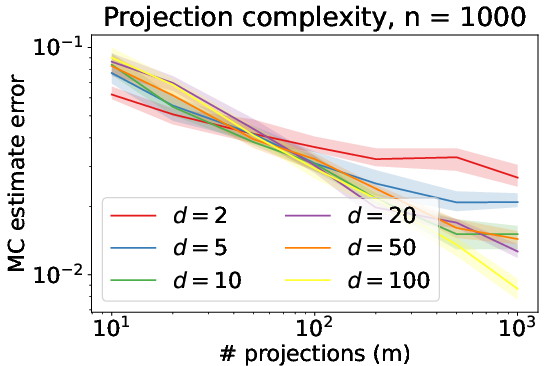
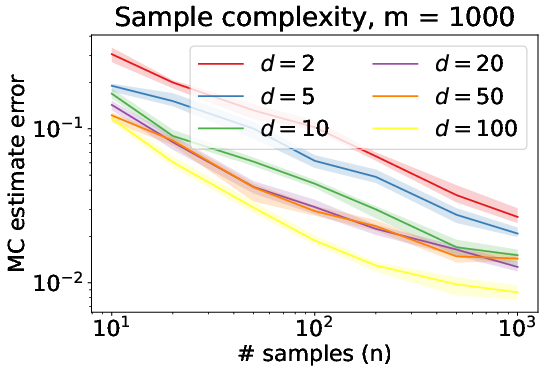
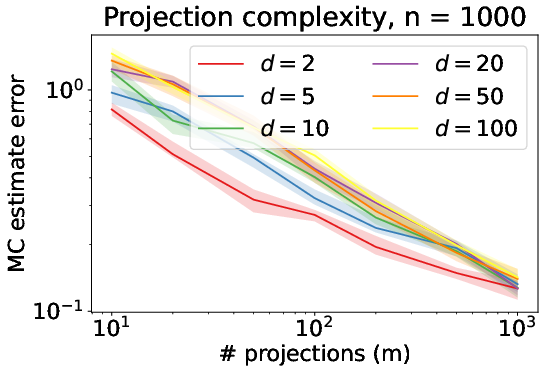
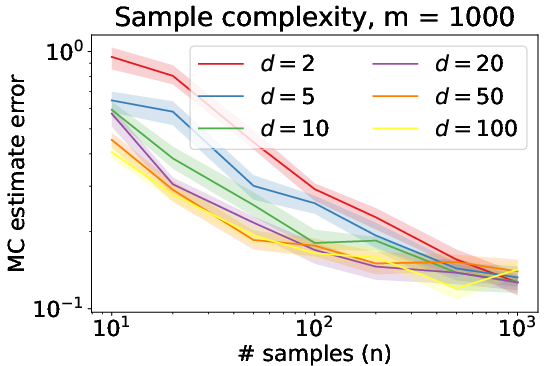
Figure 1: Depiction of absolute deviation of empirical Sliced Wasserstein from true distance under Model (1).
Robustness to Data Contamination
One key advantage of Sliced Wasserstein distances is their robustness to data contamination. The paper demonstrates that these distances admit minimax optimal risk bounds for robust estimation that are dimension-free. Specifically, the worst-case estimation risk over a class of perturbed data decreases without dependence on dimensional factors that commonly impair other metrics like the classic Wasserstein distance.
The results leverage a notion of equivalence in robustness between one-dimensional slicing and robust mean estimation, which facilitates lifting bounds from known mean estimation results to the Wasserstein metrics considered.
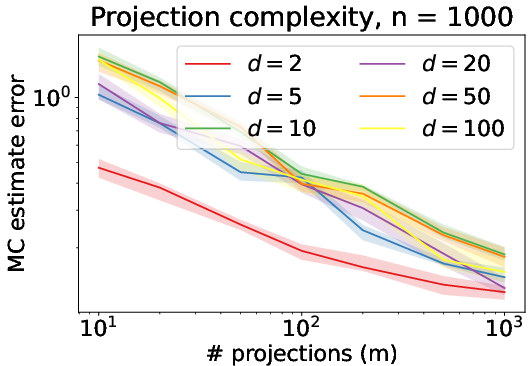
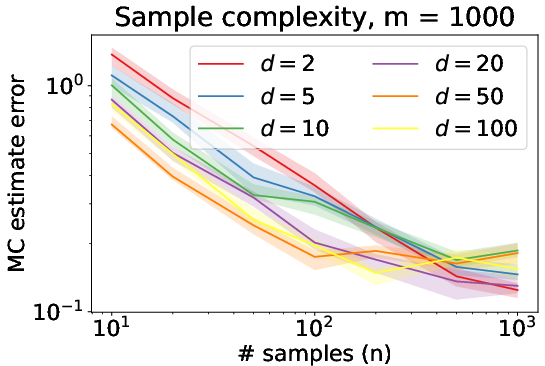
Figure 2: Error of Sliced Wasserstein estimation under Model (3) where data contamination exists.
Computational Guarantees
For computational efficiency, the authors analyze methods to rapidly compute the Sliced Wasserstein distances. The Monte Carlo integration method is proven effective for computing the average-sliced Wasserstein distance with an error that can diminish as dimensionality increases. This result defies the typical curse of dimensionality by showing that the accuracy of this straightforward estimator can actually benefit from increasing dimension in certain cases.
For maximum-slicing, a subgradient method for local optimization is shown to have effective computational complexity, including concrete bounds on the number of iterations required to reach a stationary point. Global optimization strategies based on the LIPO algorithm were also benchmarked, highlighting how even those methods can achieve guaranteed performance in practical scenarios despite non-convexity challenges.
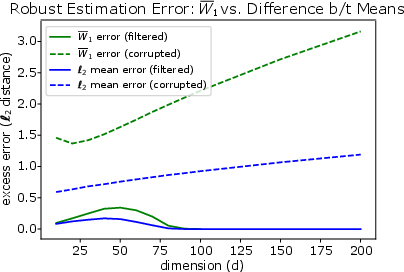
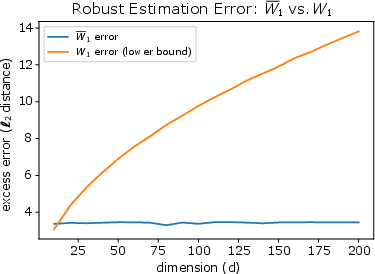
Figure 3: Illustration of robust estimation errors compared between robust estimation using MSW1 and classic W1, highlighting the dimension-free property of sliced distances.
Conclusion
Sliced Wasserstein distances provide substantial scalability advantages over the classic Wasserstein distance in the context of high-dimensional applications. The adaptation to the structure of data, robustness to outliers, and computational efficiency achieved by slicing highlight their utility in modern machine learning tasks. Future research directions could include extending the analysis to different forms of sliced distances or exploring alternative computational strategies to further enhance performance and applicability.

