- The paper presents a novel dataset of 16,123 Reddit comments annotated for 8 moral sentiment categories using the Moral Foundations Theory framework.
- It employs rigorous annotation protocols with trained annotators, reporting medium to high interannotator agreement using metrics like Fleiss' kappa and PABAK.
- Baseline evaluations show that fine-tuned models outperform large language models, underscoring the dataset's cross-domain applicability for nuanced moral sentiment analysis.
The Moral Foundations Reddit Corpus
The paper "The Moral Foundations Reddit Corpus" (2208.05545) introduces an annotated dataset focused on understanding moral sentiment within the context of Reddit comments. This corpus aims to facilitate improved insights into the dynamics of moral language across various social communities.
Introduction and Motivation
The introduction of the Moral Foundations Reddit Corpus (MFRC) addresses the need for annotations of moral rhetoric in diverse linguistic and social settings. Moral sentiment, as expressed through online platforms, impacts behaviors such as political engagement and social actions. Existing datasets have largely focused on Twitter, limiting the scope for analysis to short-form text from a single platform. To expand the analytical framework, MFRC compiles Reddit comments, enabling exploration of moral sentiment in a broader, community-driven context.
Dataset Composition
The MFRC consists of 16,123 comments from 12 morally-relevant subreddits, providing annotations for 8 categories of moral sentiment. This includes Care, Proportionality, Equality, Purity, Authority, Loyalty, Thin Morality, and Implicit/Explicit Morality based on the updated Moral Foundations Theory (MFT) framework. The corpus is structured to allow for in-depth analyses of moral dynamics within different subreddit communities.
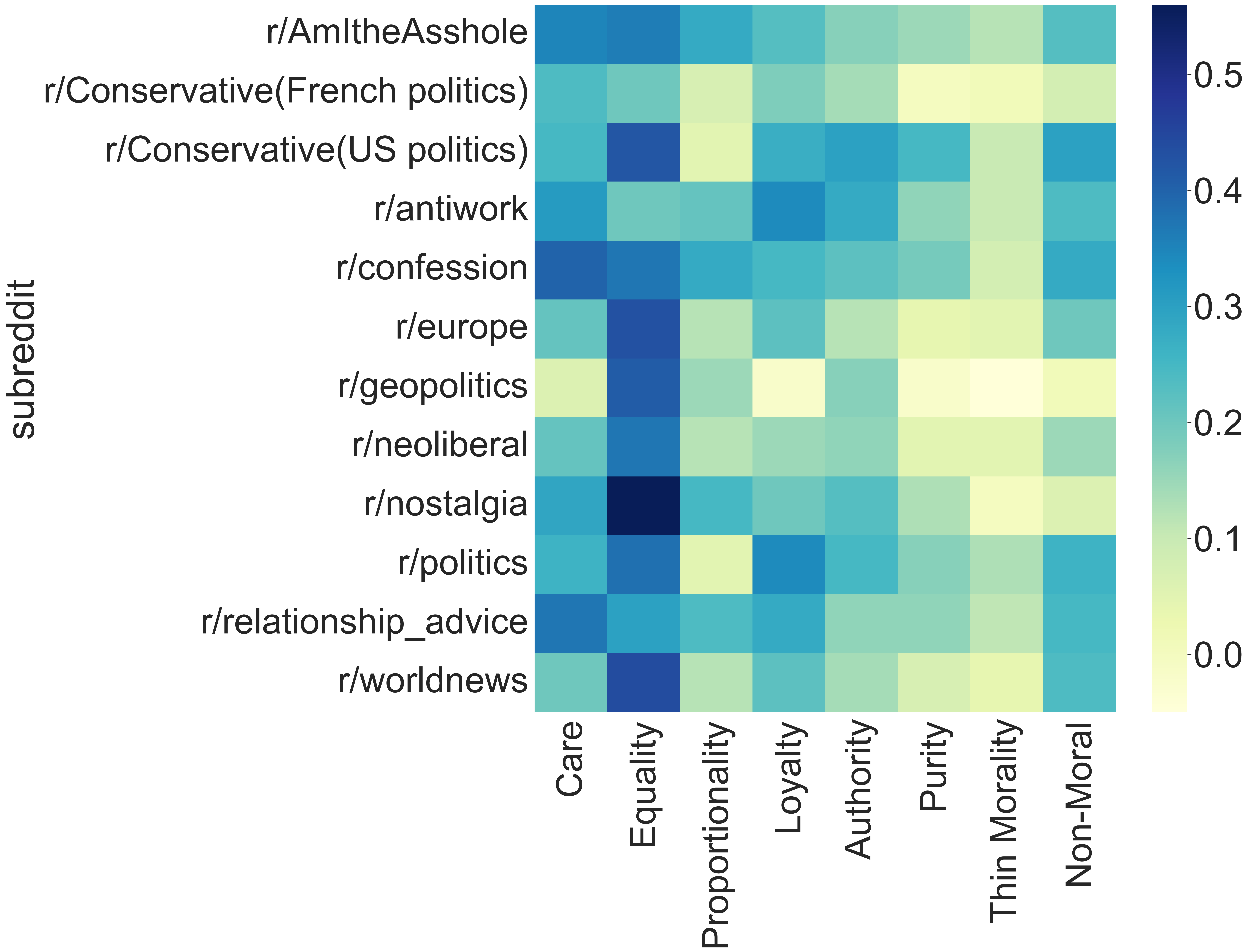
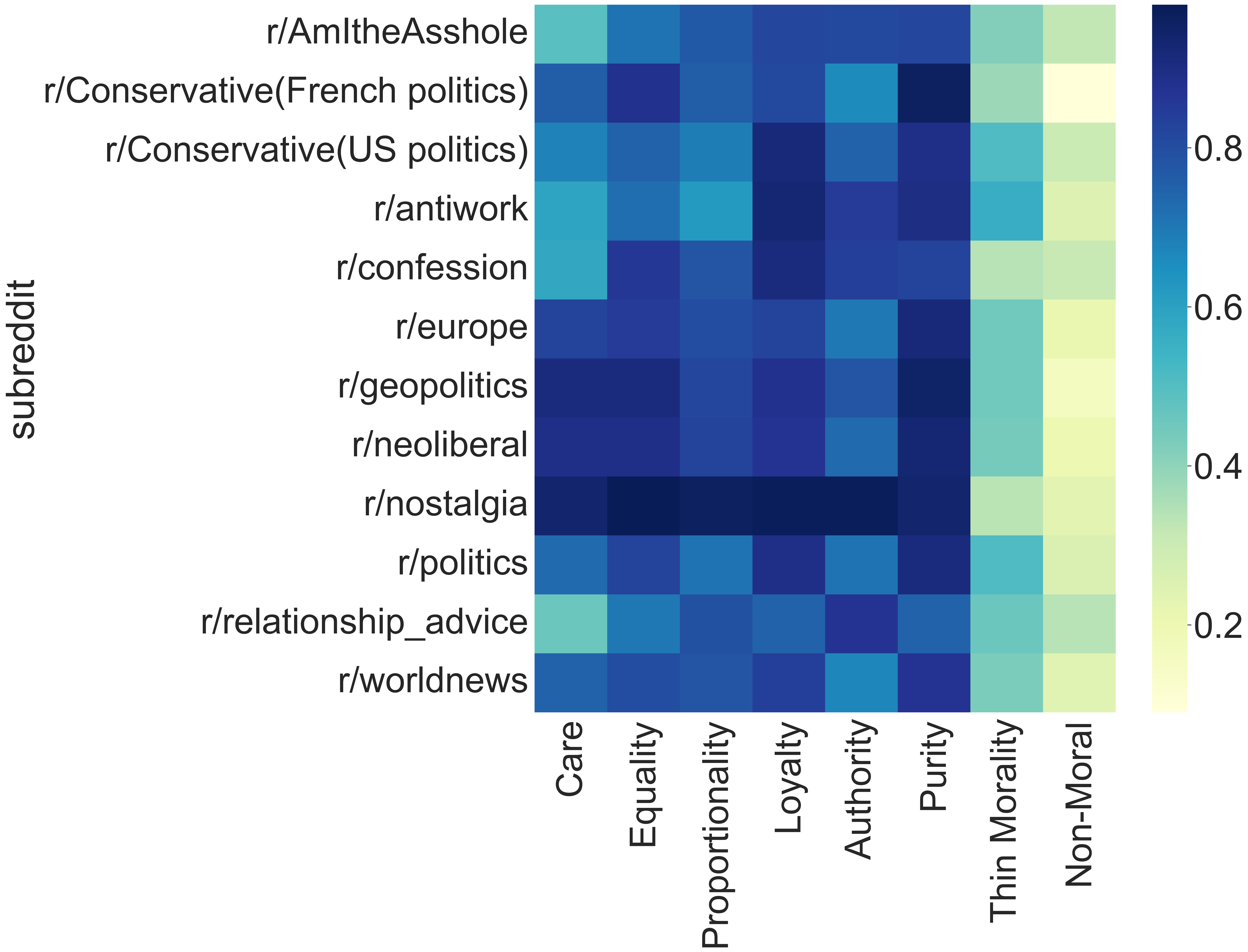
Figure 1: The heatmaps show Interannotator Agreement (PABAK and Kappa) scores for all subreddits and foundations. Higher agreement corresponds with darker colors in both heatmaps.
Annotation Process
Annotations were conducted by trained annotators, with demographic and psychological metadata collected to investigate potential bias and response patterns. This level of detail aims to ensure robust analysis across subjective dimensions of morality and addresses inherent subjectivity in sentiment classification. Interannotator agreements were assessed using Fleiss’s kappa and PABAK, indicating medium to high agreements once adjusted for prevalence issues.
Model Evaluation
Baseline evaluations were conducted using LLMs such as Llama3-8B and Ministral-8B, as well as fine-tuned models like BERT. These evaluations included zero-shot, few-shot, and parameter-efficient fine-tuning (PEFT) settings to assess the comparative performance of these models. Results indicated that fine-tuned models outperformed LLMs, underscoring the necessity of domain-specific annotated datasets for accurate sentiment classification.
Cross-Domain Applications
Preliminary results demonstrate transferability between MFRC and the Moral Foundations Twitter Corpus (MFTC), highlighting cross-platform and cross-linguistic analysis potential. Training models on MFRC and testing on MFTC—and vice versa—yielded comparable performance, suggesting that further research could capitalize on these datasets for generalized moral sentiment classification.
Conclusion
The MFRC builds upon prior work to provide a rich dataset for analyzing moral language within varied social contexts. By including community-specific and longer-form discourse from Reddit, this corpus facilitates new lines of inquiry into moral sentiment analysis. While the dataset provides substantial detail and methodological updates, researchers are advised to consider inherent biases and data-specific limitations. The corpus stands as a benchmark for evaluating moral sentiment classifications and can aid in developing comprehensive AI alignment strategies.
In summary, the MFRC not only bridges existing gaps in moral language datasets but also paves the way for extended applications in both NLP and social science domains. The dataset’s structure and annotation detail foster nuanced analyses of moral rhetoric, integral to understanding contemporary social dynamics online.