- The paper introduces a novel framework that leverages shuffled videos to mitigate temporal bias in temporal grounding tasks.
- It incorporates auxiliary tasks of cross-modal matching and temporal order discrimination to enhance semantic alignment and temporal reasoning.
- Experimental evaluations on Charades-STA and ActivityNet demonstrate improved generalization and robustness to out-of-distribution scenarios.
Can Shuffling Video Benefit Temporal Bias Problem: A Novel Training Framework for Temporal Grounding
Introduction
This paper addresses the temporal bias in temporal grounding tasks, which aim to localize video moments matching a given query phrase within untrimmed videos. Temporal bias issues arise when models over-rely on the temporal location of actions rather than the visual-textual semantic alignment. The proposed training framework leverages shuffled videos to alleviate this bias while maintaining grounding accuracy.
Temporal Bias Problem
Temporal bias arises when models predict moment locations based on the memorized temporal patterns of the training data rather than actively using visual and textual content. This limits generalization, particularly when temporal distributions differ between datasets. Typical datasets present correlations between queries and temporal positions, allowing models to shortcut visual understanding.

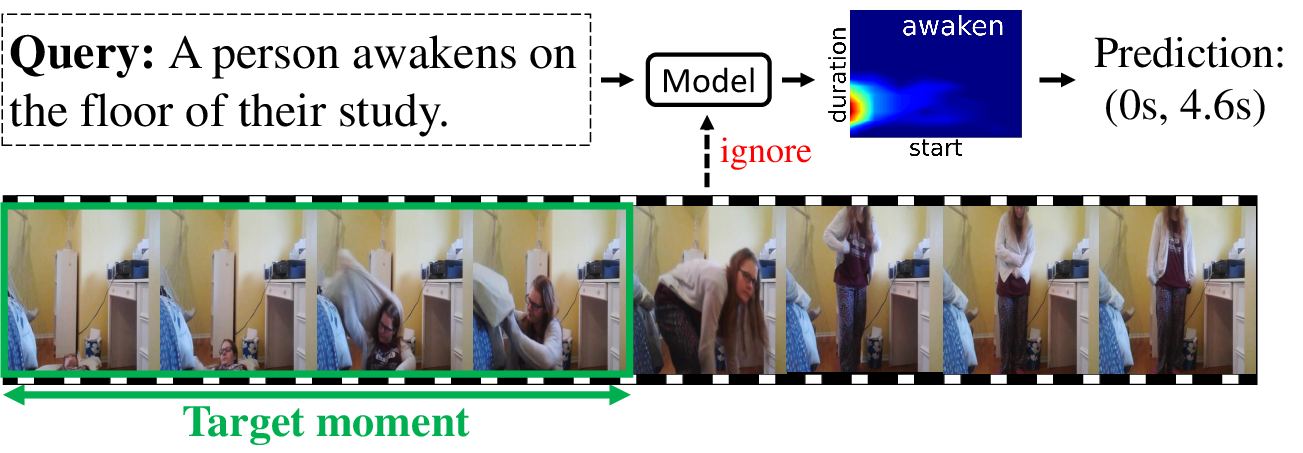
Figure 1: (a) Temporal grounding aims to localize moments from video queries. (b) A model over-relies on temporal bias: uses word awaken from Charades-STA to predict without visual input.
Methodology
Pseudo Video Generation
The method proposes generating pseudo videos by inserting target video moments at random positions in the video timeline, disrupting the temporal bias while preserving spatial coherence within the moment.
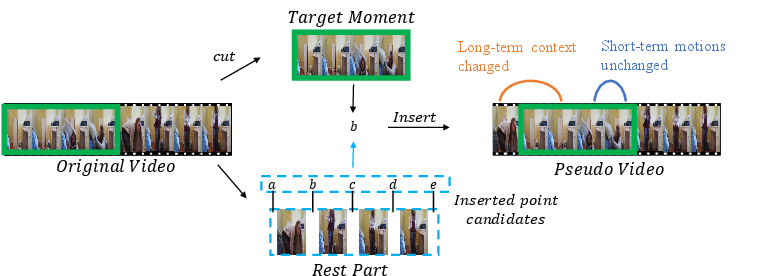
Figure 2: An illustration of generating pseudo videos, showing how target moments are repositioned in the timeline.
Framework Architecture
The architecture consists of a grounding model augmented with two auxiliary tasks: cross-modal matching and temporal order discrimination. These tasks force the model to focus on semantic matching and accurate temporal understanding.
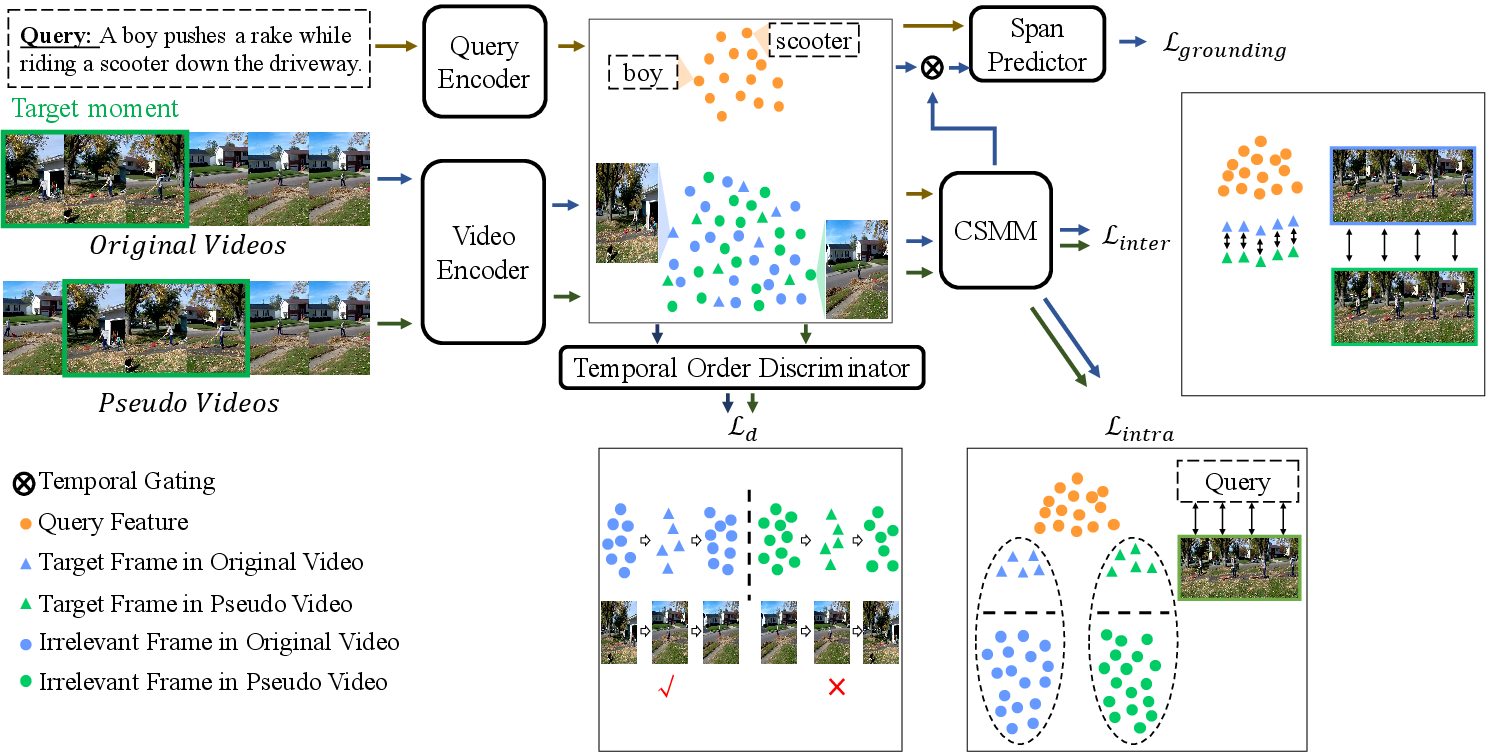
Figure 3: Framework with auxiliary tasks: encoders for video/query detect boundary scores. Cross-modal semantic matching enforces relevance, and temporal order discrimination ensures sequence coherence.
Cross-Modal Matching
The cross-modal matching task ensures models detect semantic relevance between video frames and queries, independent of temporal bias. It utilizes intra- and inter-video consistency constraints to enhance grounding through spatial content focus.
Temporal Order Discrimination
This task strengthens the model's comprehension of long-term temporal contexts without bias, asking models to determine if a video sequence is temporally coherent, thereby guiding them to prioritize contextual understanding over temporal bias exploitation.
Experimental Evaluation
The framework was tested on Charades-STA and ActivityNet datasets with varied temporal distributions. It demonstrated superior generalization performance, particularly in test cases simulating out-of-distribution scenarios.
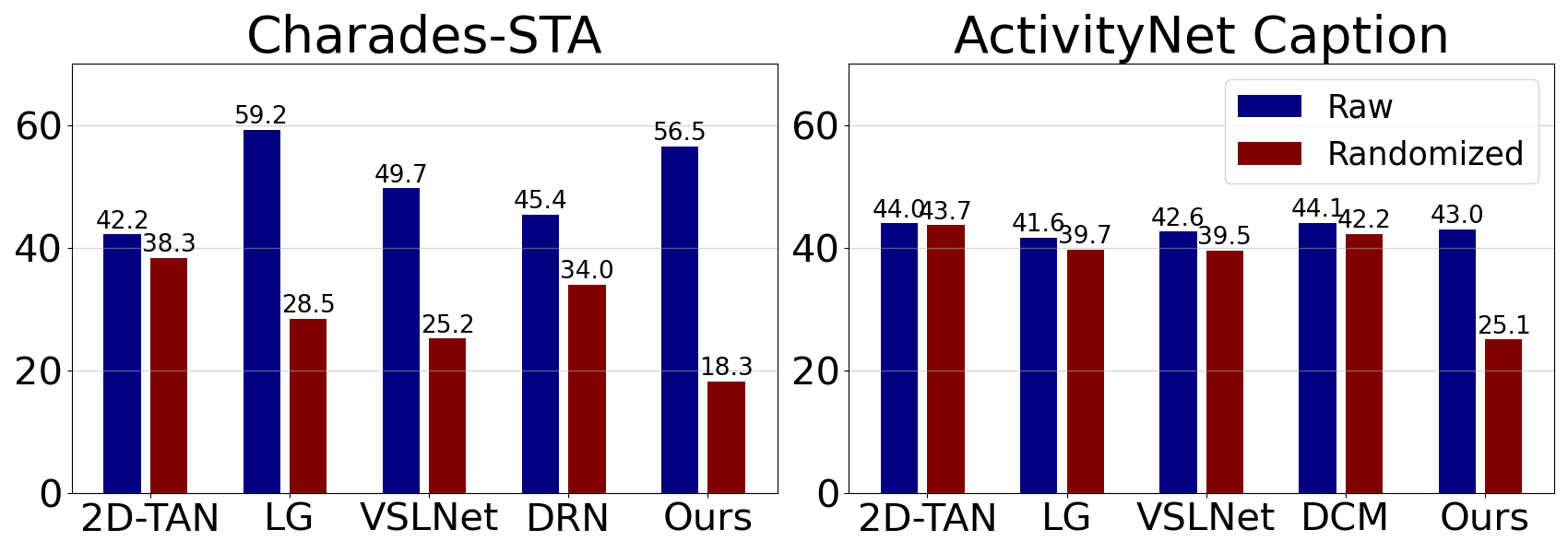
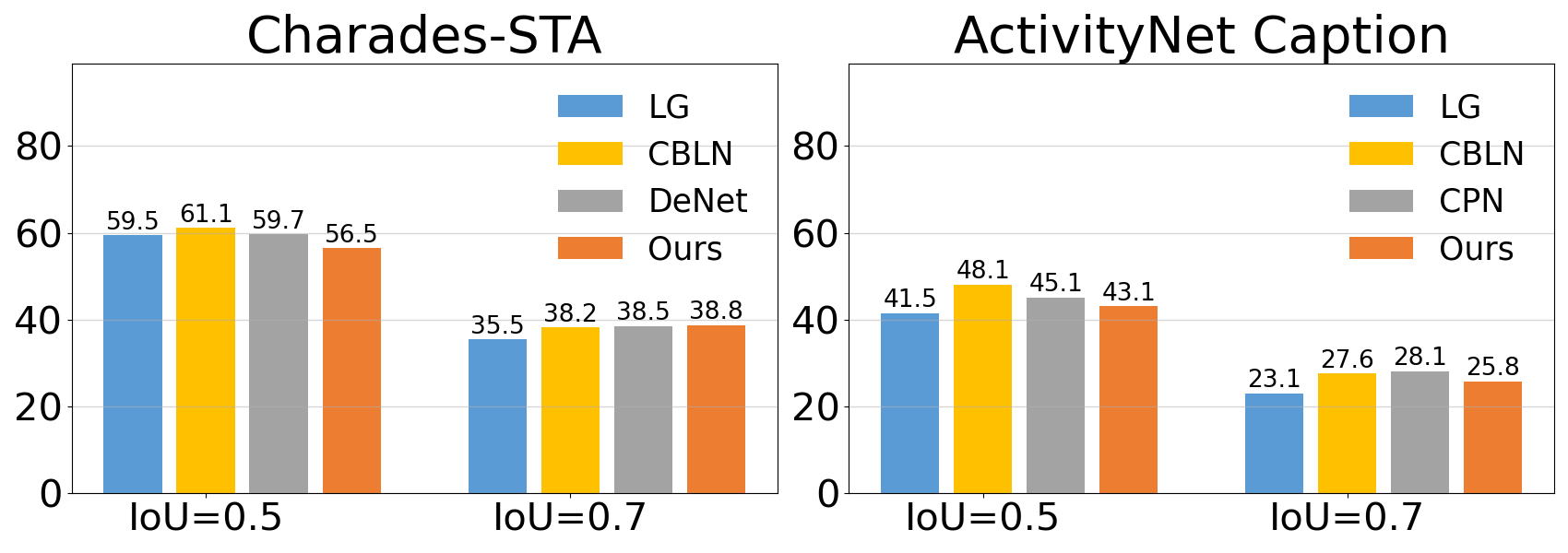
Figure 4: (a) Sanity check on visual input shows reliance differences; (b) performance comparisons demonstrate improvement over traditional splits.
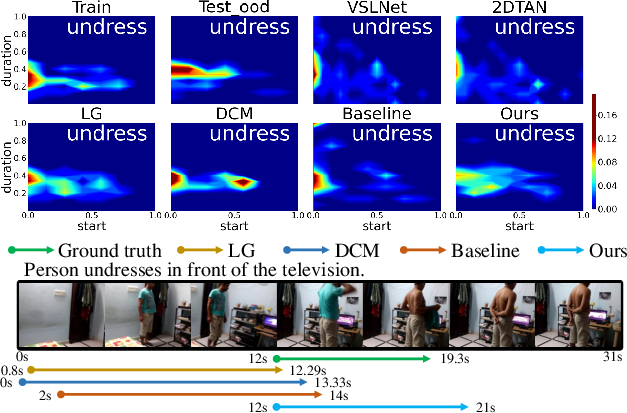
Figure 5: Top: temporal distribution of 'undress' on Charades-CD illustrating bias discrepancy. Bottom: grounding result for a query containing 'undress', showing better alignment with shuffled model.
Conclusion
The proposed framework effectively mitigates temporal biases, enhancing generalization capability while maintaining grounding accuracy. By integrating shuffled videos and auxiliary tasks, it promotes more authentic visual-textual correspondence and robust temporal reasoning. Future investigation into broader application scenarios and additional plausible biases can further cement this framework’s adaptability in video understanding tasks.

