- The paper introduces SkiMo, a framework that uses a skill dynamics model to predict long-term outcomes, enhancing planning in reinforcement learning.
- The study employs joint pre-training of skills and the dynamics model to achieve superior performance in navigation and manipulation tasks.
- Experimental results show that SkiMo significantly improves sample efficiency and reliability in complex, sparse-reward environments.
Skill-based Model-based Reinforcement Learning
Introduction
The paper "Skill-based Model-based Reinforcement Learning" presents SkiMo, a framework designed to improve sample efficiency in reinforcement learning (RL) by combining model-based and skill-based approaches. This framework draws inspiration from human intelligence, where high-level skills rather than low-level actions are used for planning. SkiMo leverages a skill dynamics model to predict skill outcomes directly, enhancing the ability to perform accurate long-term planning. This paper demonstrates significant improvements in sample efficiency over existing model-based and skill-based RL techniques, particularly in tasks that require long-horizon and sparse reward structures.
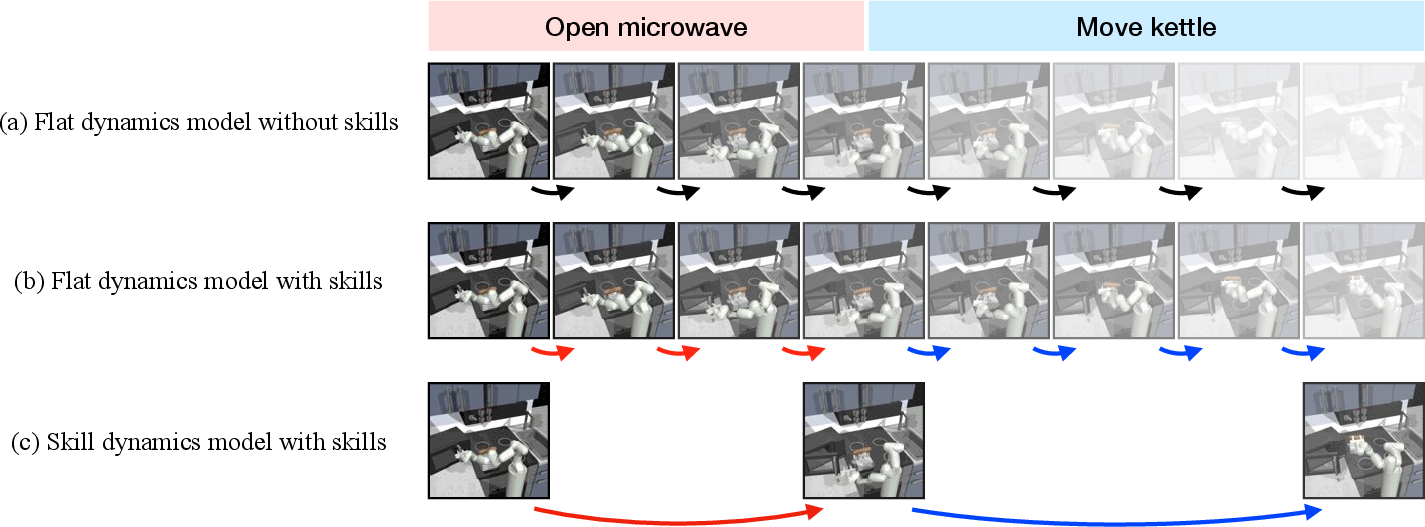
Figure 1: Intelligent agents can use their internal models to imagine potential futures for planning, leading to improved predictions and planning efficiency.
Methodology
Skill Dynamics Model
SkiMo introduces a skill dynamics model, which is a cornerstone of the proposed methodology. Instead of simulating every possible low-level action, the skill dynamics model predicts the state after executing a sequence of high-level skills. This approach significantly reduces the number of predictions required, thereby minimizing error accumulation and enhancing long-term prediction accuracy.
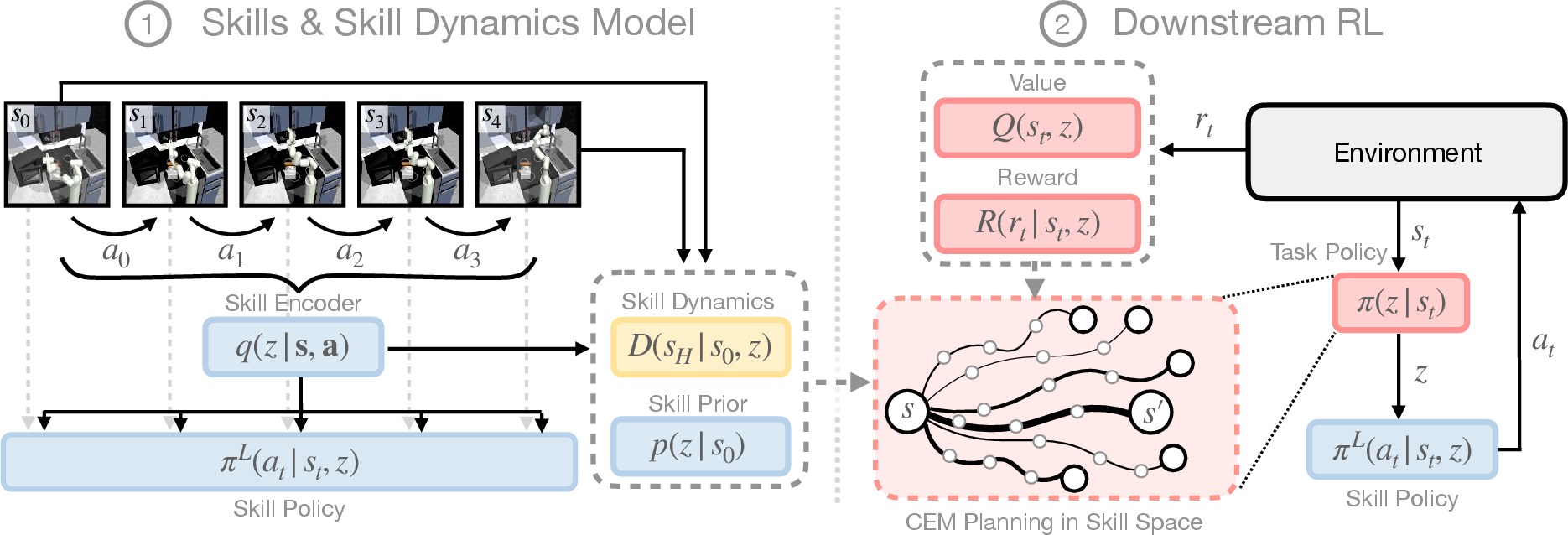
Figure 2: SkiMo combines model-based RL and skill-based RL for efficient learning of long-horizon tasks, leveraging learned skills and skill dynamics.
Pre-Training Phase
During pre-training, SkiMo extracts a skill repertoire and a skill dynamics model from task-agnostic, offline data. The joint training of skills and the skill dynamics model shapes the skill embedding space, allowing for efficient prediction and skill execution. This method contrasts with others that train these components separately, suggesting that integration leads to more cohesive learning outcomes.
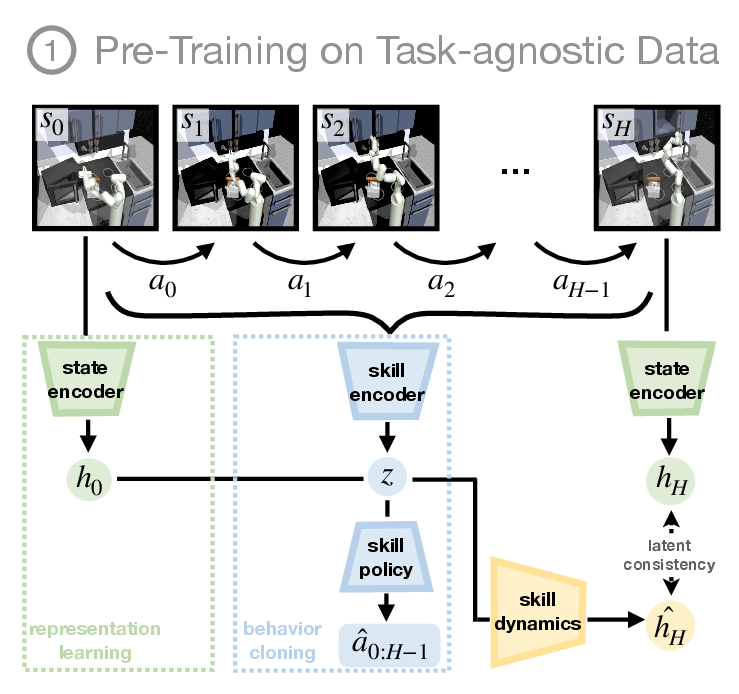
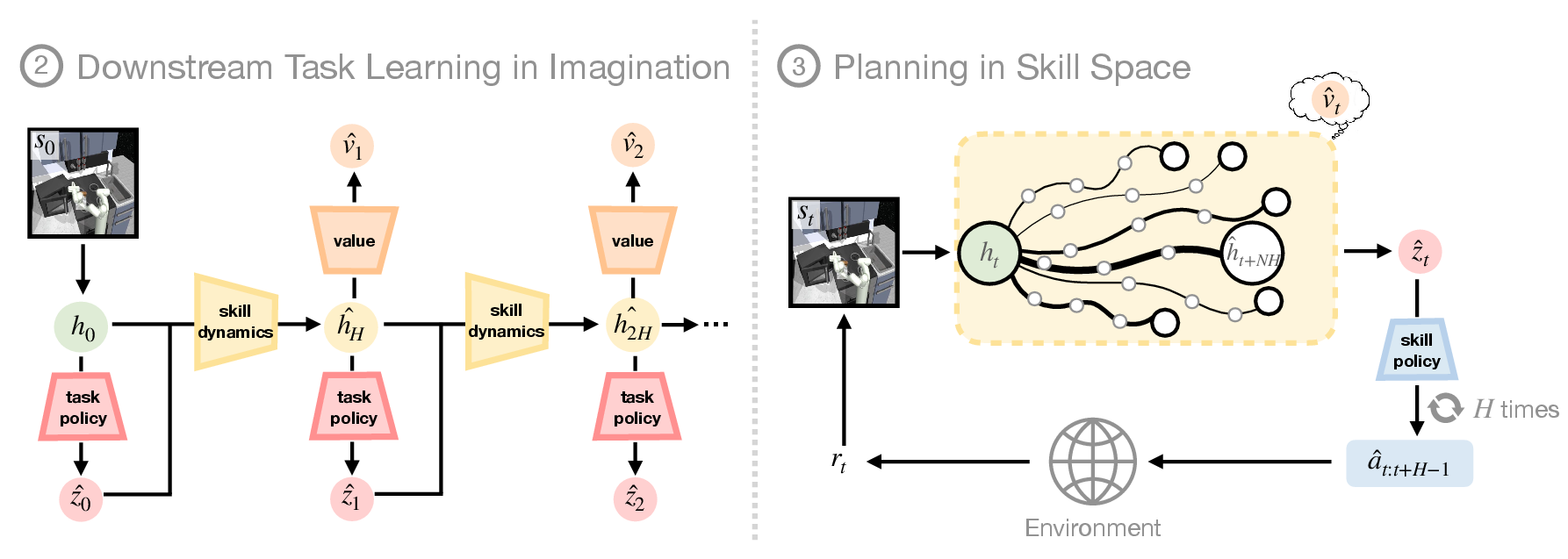
Figure 3: Pretraining in SkiMo jointly trains the model and policy to derive an effective skill space for planning.
Experimental Results
SkiMo was tested against several baseline algorithms across multiple domains, including navigation and manipulation tasks. The experimental results show that SkiMo consistently outperforms state-of-the-art RL methods in sample efficiency and effectiveness on tasks with long horizons and sparse rewards. For instance, in complex maze navigation tasks, SkiMo achieved more reliable goal attainment due to its superior planning and prediction techniques.
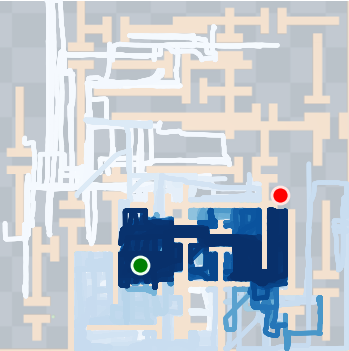
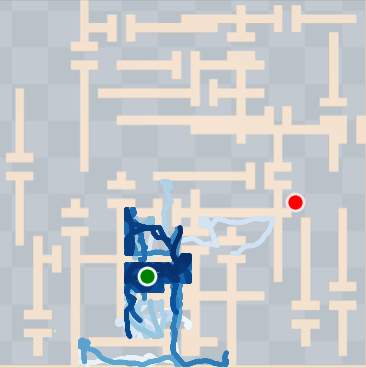
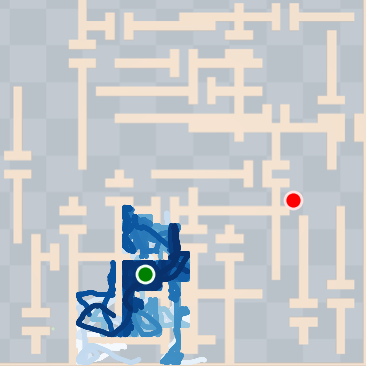
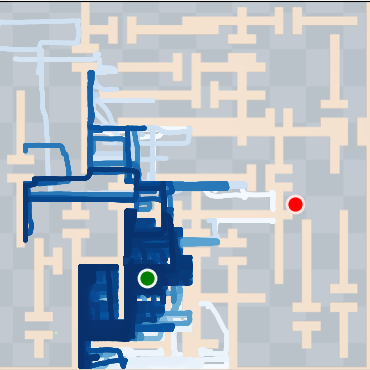
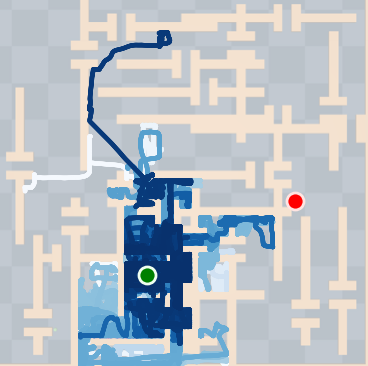
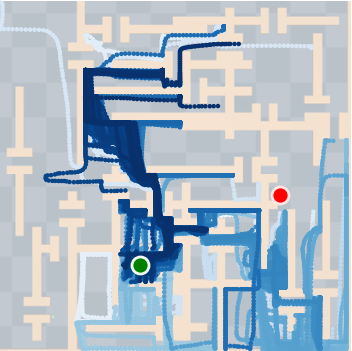
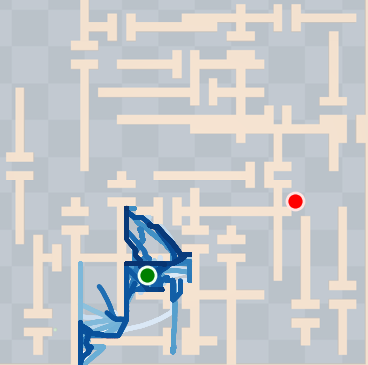
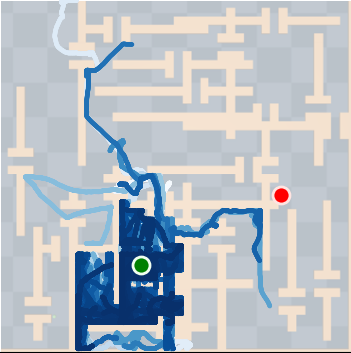
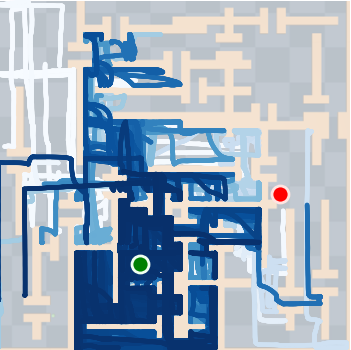
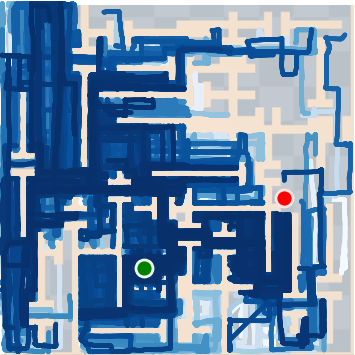
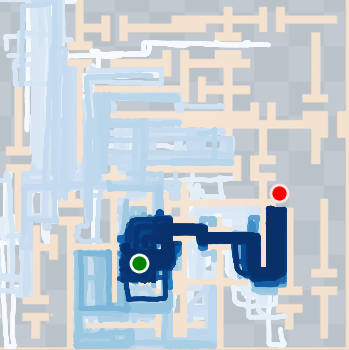
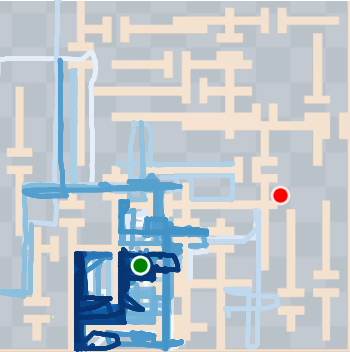
Figure 4: SkiMo outperforms other approaches in completing long-horizon tasks efficiently.
Implications and Future Directions
The implications of this research are significant for practical RL applications, particularly in robotics and automation, where tasks are typically long-horizon with sparse feedback. The ability to plan using temporally abstracted skills while maintaining high prediction accuracy opens pathways for deploying RL in complex real-world scenarios. Future work may explore extending SkiMo to real robots, where tasks involve high-dimensional sensory inputs such as RGB images and tactile feedback. Additionally, developing flexible semantic skill extraction could enhance planning capabilities further.
Conclusion
SkiMo presents a robust framework for skill-based and model-based RL, effectively merging the strengths of both approaches. The innovation of using a skill dynamics model for long-term planning marks a pivotal advancement in RL methodologies. By optimizing skill learning and execution, SkiMo offers a pathway towards more efficient and scalable RL, suitable for complex problem-solving in dynamic environments.

