- The paper introduces a unified taxonomy that categorizes segmentation methods based on weak supervision types (no, inexact, incomplete, inaccurate) and tasks.
- It emphasizes the role of heuristic priors—cross-label, cross-pixel, cross-view, and cross-image constraints—in bridging the supervision gap within both self-training and end-to-end methods.
- The survey highlights that advanced self-training and transformer-based methods have narrowed mIoU gaps between weakly- and fully-supervised segmentation on datasets like PASCAL VOC and Cityscapes.
Label-efficient Deep Image Segmentation: A Comprehensive Survey
Introduction
This survey provides a systematic and detailed review of label-efficient deep image segmentation, focusing on the challenge of reducing the reliance on dense, pixel-level annotations in semantic, instance, and panoptic segmentation. The paper introduces a unified taxonomy based on the type of weak supervision—no supervision, inexact supervision, incomplete supervision, and inaccurate supervision—and analyzes the strategies that bridge the gap between weak labels and dense predictions. The survey also discusses the mathematical foundations, methodological paradigms, and the role of heuristic priors in the design of label-efficient segmentation algorithms.
The taxonomy is organized along two axes: the type of weak supervision and the segmentation task (semantic, instance, panoptic). The types of weak supervision are:
- No Supervision: No annotations are provided.
- Inexact Supervision: Coarse annotations (image-level, box-level, scribble-level) are available.
- Incomplete Supervision: Only a subset of images is densely annotated (semi-supervised, domain-adaptive).
- Inaccurate Supervision: Annotations are noisy or erroneous.
This taxonomy is visualized in a matrix where each cell corresponds to a specific segmentation problem under a given supervision regime, with filled dots indicating explored areas and representative works annotated.
(Figure 1)
Figure 1: The taxonomy of label-efficient deep image segmentation methods, organized by weak supervision type and segmentation task, with representative works at explored intersections.
The mathematical formulation for each supervision type is unified by expressing the training set as a collection of image-label pairs, where the label format varies according to the supervision (e.g., full dense labels, image-level tags, bounding boxes, scribbles, or noisy masks).
Heuristic Priors for Bridging the Supervision Gap
The core challenge is the supervision gap between weak labels and dense predictions. The survey identifies four heuristic priors that are repeatedly leveraged:
- Cross-label Constraint: Natural constraints between coarse and fine labels (e.g., image-level class implies at least one pixel of that class).
- Cross-pixel Similarity: Pixels with similar low- or high-level features likely belong to the same region.
- Cross-view Consistency: Different views (augmentations) of the same image should yield consistent predictions.
- Cross-image Relation: Pixels from the same class across images share semantic relations.
These priors are instantiated in loss functions for pseudo-label generation and regularization, and their applicability varies with the supervision type.
Methodological Paradigms
Two dominant methodological paradigms are identified:
- Self-training: Generate pseudo-labels from weak supervision, then train a segmentation model on these pseudo-labels, often with iterative refinement and regularization.
- End-to-end Training: Directly optimize a loss that connects weak labels to dense predictions, sometimes bypassing explicit pseudo-label generation.
The survey provides formal definitions and loss formulations for each approach, highlighting the role of priors in both paradigms.
Advances in Label-efficient Segmentation
Unsupervised Segmentation
Recent advances in unsupervised segmentation leverage dense self-supervision via contrastive learning and Siamese architectures. Methods such as VADeR and MaskContrast use pixel-wise contrastive objectives to enforce cross-view consistency, while STEGO exploits cross-image feature correspondences.
(Figure 2)
Figure 2: Illustration of VADeR, contrasting image-level and pixel-level contrastive learning for dense representation learning.
Weakly-supervised Segmentation (Inexact Supervision)
For image-level, box-level, and scribble-level supervision, the mainstream pipeline involves generating seed regions (e.g., via CAMs), expanding them using priors (saliency, affinity, cross-image relations), and iteratively refining pseudo-masks. End-to-end approaches are emerging but less common.
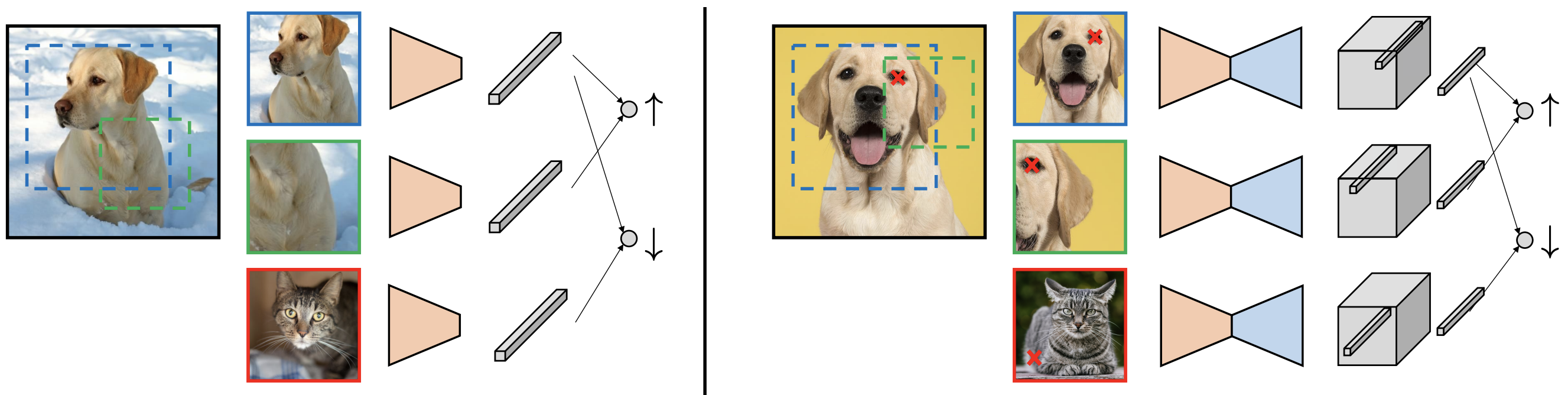
Figure 3: Mainstream pipeline for semantic segmentation with image-level supervision, highlighting the role of priors in seed area refinement and pseudo-mask generation.
Semi-supervised and Domain-adaptive Segmentation (Incomplete Supervision)
Semi-supervised methods use self-training with confidence-based pseudo-label selection and regularization via cross-view consistency (e.g., Siamese networks, contrastive learning). Domain-adaptive methods introduce domain alignment via adversarial learning or domain mixing, in addition to pseudo-label refinement.
(Figure 4)
Figure 4: Mainstream pipeline for semi-supervised semantic segmentation, showing teacher-student self-training and the use of priors for pseudo-label generation and regularization.
Segmentation with Noisy Supervision
Methods for segmentation with noisy labels focus on robustness, using early stopping, uncertainty estimation, and multi-scale consistency to mitigate overfitting to annotation errors.
The survey compiles benchmark results across supervision regimes. Notably, state-of-the-art weakly- and semi-supervised methods approach the performance of fully-supervised models on standard datasets (e.g., PASCAL VOC, Cityscapes), with mIoU gaps narrowing to a few percentage points. However, performance degrades significantly under large domain shifts or when scaling to open-vocabulary settings.
Open Challenges and Future Directions
Supervision Gap and Scalability
Despite progress, bridging the supervision gap remains unresolved, especially for large-scale, open-vocabulary segmentation. Scaling to thousands of classes and integrating multi-modal supervision (e.g., text) are open problems.
Openness and Lifelong Learning
Label-efficient segmentation is closely related to open-domain and lifelong learning, where new classes and annotation types may appear over time. Unified frameworks for handling heterogeneous, evolving supervision are needed.
Granularity vs. Consistency
As the number of classes increases, maintaining consistent, fine-grained recognition becomes challenging. New evaluation protocols are required to account for granularity-consistency trade-offs.
The emergence of vision transformers and large-scale self-supervised pretraining (e.g., CLIP, DINO, MAE) offers new opportunities for label-efficient segmentation, particularly in zero-shot and open-domain scenarios. Leveraging unsupervised attention maps and cross-modal alignment is a promising direction.
Unexplored Problem Settings
Several supervision-task combinations remain underexplored, such as instance segmentation with noisy labels and panoptic segmentation with incomplete labels, due to dataset and modeling limitations.
Conclusion
This survey provides a comprehensive synthesis of label-efficient deep image segmentation, unifying diverse supervision regimes and methodological advances under a common framework. While significant progress has been made, especially in leveraging heuristic priors and self-supervised learning, substantial challenges remain in scaling, robustness, and open-domain generalization. Future research will likely focus on integrating multi-modal supervision, advancing transformer-based architectures, and developing unified frameworks for lifelong, open-vocabulary segmentation.