- The paper presents a novel gamified data collection process that integrates human and model interaction to expose flaws in AI commonsense reasoning.
- It employs a model-in-the-loop adversarial framework with rigorous validation, revealing a significant performance gap between top models and human reasoning.
- Evaluation shows consistent model weaknesses on size comparison, negation, and long-tail factual knowledge, highlighting the need for robust benchmark design.
CommonsenseQA 2.0: Gamification-Driven Benchmarking for Commonsense Reasoning
Introduction
CommonsenseQA 2.0 (CSQA2), introduced in "CommonsenseQA 2.0: Exposing the Limits of AI through Gamification" (2201.05320), describes a new paradigm for constructing natural language understanding (NLU) benchmarks by employing a gamified, model-in-the-loop adversarial data collection process. The key insight is that conventional crowdsourcing approaches for constructing NLU benchmarks frequently embed annotation artifacts and biases, allowing large pre-trained LLMs (PLMs) to achieve near-human-level performance without generalizing robustly, particularly in out-of-domain or adversarial scenarios. CSQA2 targets this by directly integrating human competition against an evolving model into the benchmark construction process, thereby surfacing model brittleness and gaps in robust commonsense reasoning.
Gamified Data Collection Pipeline
CSQA2 uses a three-phase gamification approach—controlled question generation, model-in-the-loop adversarial answering, and rigorous human validation—to elicit high-quality, diverse yes/no commonsense questions. The design systematically manipulates incentives for annotators via a points system, rewarding questions that "trick" the model, utilize specific topic and relational prompts (derived from ConceptNet and manually curated relations), and are deemed correct by independent validation. Players face dynamic challenge, as the model-in-the-loop is periodically retrained on the adversarial data being collected, explicitly countering annotator strategies that over-exploit transient model weaknesses.
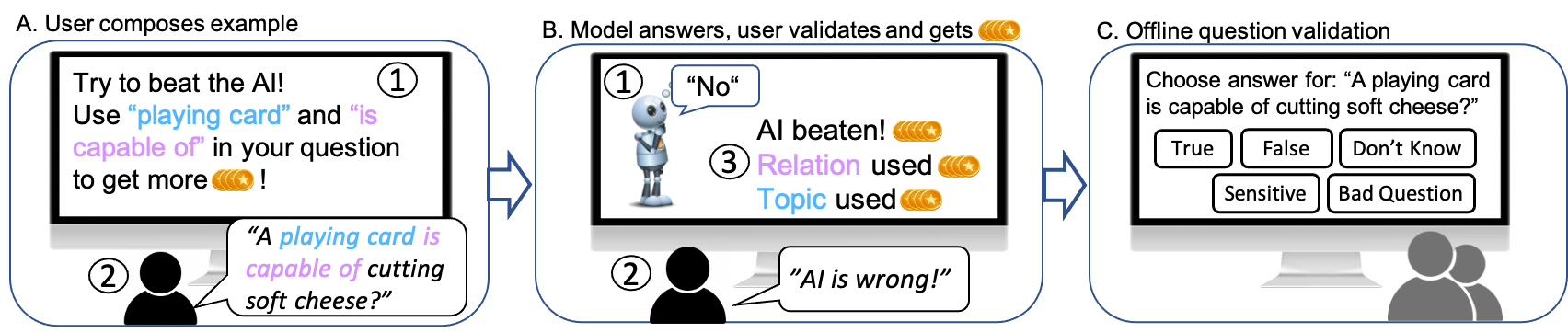
Figure 1: An overview of the CSQA2 gamified data collection, featuring player-authored questions, real-time model interaction, and the incentive-driven pipeline for data diversity and challenge.
The process includes multiple layers of quality assurance. An automatic validation step uses a model trained on manually-labeled data to filter out ambiguous or low-quality questions. Crowdsourcing is mediated via Amazon Mechanical Turk, with non-compliant annotators pruned based on withheld “expert test” questions. Critically, the system automatically issues web queries (top-k Google snippets) for each candidate question, filtering those with high lexical overlap (to preclude trivial web lookup) and thus increasing the dataset's reliance on genuine commonsense.
Dataset Structure and Analysis
CSQA2 comprises 14,343 filtered yes/no questions with broad topical and relational diversity, utilizing 1,868 unique concept prompts and 33 distinct manually defined relational prompts (e.g., "is a", "can", "causes”, "larger than", quantifiers, temporal, conditional, etc.). The distribution of reasoning types and relation types is far more uniform and less artifact-prone than earlier benchmarks due to the incentive structure and gamified interface.

Figure 2: Distribution of relational prompt words in the dataset; area proportional to prompt frequency, evidencing the diversity of both topics and reasoning types.
Detailed linguistic analysis of a random sample of CSQA2 reveals a high frequency of questions requiring physical commonsense, long-tail factoid knowledge, causal inference, size comparison, temporal constraints, and quantification. This high coverage—together with the low entropy of prompt usage—yields a consistently challenging set for both discriminative and generative NLU models.
A battery of large LMs and specialized models were benchmarked on CSQA2: GPT-3 (175B, few-shot), T5-{Large, 11B} (fine-tuned), and Unicorn (T5-11B multi-task trained on Rainbow). None approach human-level accuracy. The top-performing model (Unicorn-11B, fine-tuned) achieves only 70.2% test accuracy, compared to 94.1% from the human majority vote, creating a clear performance gap and removing the ceiling effects found in prior benchmarks. GPT-3 few-shot, despite its scale, lags at 52.9% accuracy, and prompt engineering for few-shot settings does not close the gap. Model accuracy improves somewhat when web snippets are provided as auxiliary context (not available at test time), but this benefit is limited and context injection introduces susceptibility to misinformation and context hallucination effects, further revealing failure modes unlike those in artifact-heavy, closed-domain QA datasets.
Strong numerical findings and claims from the paper include:
- Unicorn-11B outperforms GPT-3 by over 17 percentage points (70.2% vs. 52.9%), but still lags humans by nearly 24 percentage points.
- No baseline demonstrates robust consistency under minor linguistic/logical perturbations of the same question (“contrast set” evaluation), with the best EM (exact match per contrast set) <20%.
- Models exhibit systematically lower accuracy on questions requiring size comparison, negation, or long-tail factual/temporal knowledge, even as scaling model size improves only some aspects (e.g., “hypernymy”).
- Counterfactual or misleading web snippets can further degrade performance, as models are prone to failing to distinguish categorical facts from fiction or metaphorical/imaginary statements.
Data Curation and Annotation Dynamics
The paper provides a rigorous ablation analysis of the impact of game design on data quality—showing, for example, that increased feedback to annotators on verification/validation rates increases data quality but makes questions easier for models due to increased conservatism among players. Retraining the model-in-the-loop at regular intervals causes real-time increases in dataset difficulty as annotators are forced to diversify question types. Annotator engagement is high, evidenced by positive sentiment feedback and a sharp increase in annotator participation relative to prior QA datasets (2,537 participants vs. only 85 for CommonsenseQA 1.0).
Comparative Error Analysis and Skill Breakdown
The work provides a meticulous breakdown of model performance by reasoning skill (e.g., meronymy/hypernymy, causality, long-tail factoids, size comparison), leveraging prompt metadata for interpretable skill attribution. The most significant performance discrepancies appear in questions requiring complex composition or world knowledge outside the model’s parametric pretraining distribution. In addition, despite the apparent extensibility of large LMs, none exhibit robust transfer to logically equivalent minor variants of a question, and “free-form” answer generation with GPT-3 displays low agreement and oddities upon further probing via “why” prompts, flagging major deficiencies in knowledge consistency and explainability.
Implications and Future Directions
CSQA2 demonstrates the success of dynamically adversarial gamified data creation as a mechanism for generating artifact-resistant, scaling-challenging, high-diversity QA datasets. This approach both exposes and quantifies the remaining gap between current LMs and robust human-level commonsense reasoning. The evidence for dramatic performance shortfalls, weak logical consistency, and poor generalization in the presence of trivial linguistic perturbations stratified across skill types suggests two critical directions for NLU research:
- Robustness and Consistency: Model improvements need to move beyond red-teaming and artifact reduction to emphasize cross-perturbation consistency, causal reasoning, and resilience against both linguistic variation and adversarial context.
- Adversarial Benchmark Design: Gamification, integrated human modeling, and validation feedback are effective at creating ongoing "moving targets" for NLU that prevent simple curve fitting or shortcut exploitation by LMs.
Conclusion
CommonsenseQA 2.0 provides a compelling case that existing state-of-the-art LLMs, even at scale, are not remotely close to solving the challenge of general commonsense reasoning. The adversarial, gamification-driven, dynamic data collection paradigm should be considered a new standard for the creation of high-fidelity benchmarks. The empirical findings in this work support the assertion that bridging the remaining gap will require methodological innovation in model architectures, training procedures, and, crucially, in the design of evaluation datasets themselves. CSQA2 sets a new bar for future work in commonsense reasoning and NLU benchmark construction, and its methodological framework is directly extensible to other reasoning and knowledge domains.

