- The paper demonstrates that no single human evaluation method is universally optimal, with single-model and pairwise approaches showing distinct trade-offs.
- The paper reveals that PW-Dialog is particularly effective for distinguishing output length differences, while SM-Dialog better captures nuances related to model size.
- The paper suggests that developing hybrid evaluation techniques that combine per-turn and per-dialogue methods could enhance the reliability of conversational AI assessments.
Human Evaluation of Conversations: A Comparative Analysis of Methods
The evaluation of open-domain conversational models presents significant challenges, particularly when relying on human evaluations, which are deemed superior to automated metrics. In this paper, five crowdworker-based evaluation methods are analyzed for their effectiveness in distinguishing the performance of dialogue agents. This analysis identifies the strengths and limitations of each method, providing insights into their applicability depending on model comparison scenarios.
Evaluation Methods
Single-Model and Pairwise Evaluations
The paper compares two primary approaches: single-model evaluations, where one model's performance is assessed, and pairwise evaluations, where two models are compared directly.
- Single-Model Per-Turn (SM-Turn) and Per-Dialogue (SM-Dialog): SM-Turn involves rating model responses after each turn, while SM-Dialog evaluates the entire conversation at its conclusion using Likert-scale ratings. SM-Turn offers granular feedback but may suffer from rater variability, as the evaluation context continuously changes.
- Pairwise Per-Turn (PW-Turn) and Per-Dialogue (PW-Dialog): PW-Turn compares model responses at each turn, potentially exposing subtleties in conversational dynamics. PW-Dialog offers a holistic assessment over entire dialogues, benefiting from global judgment metrics. PW-Dialog self-chat involves comparisons between two bots conversing with themselves (Figure 1).
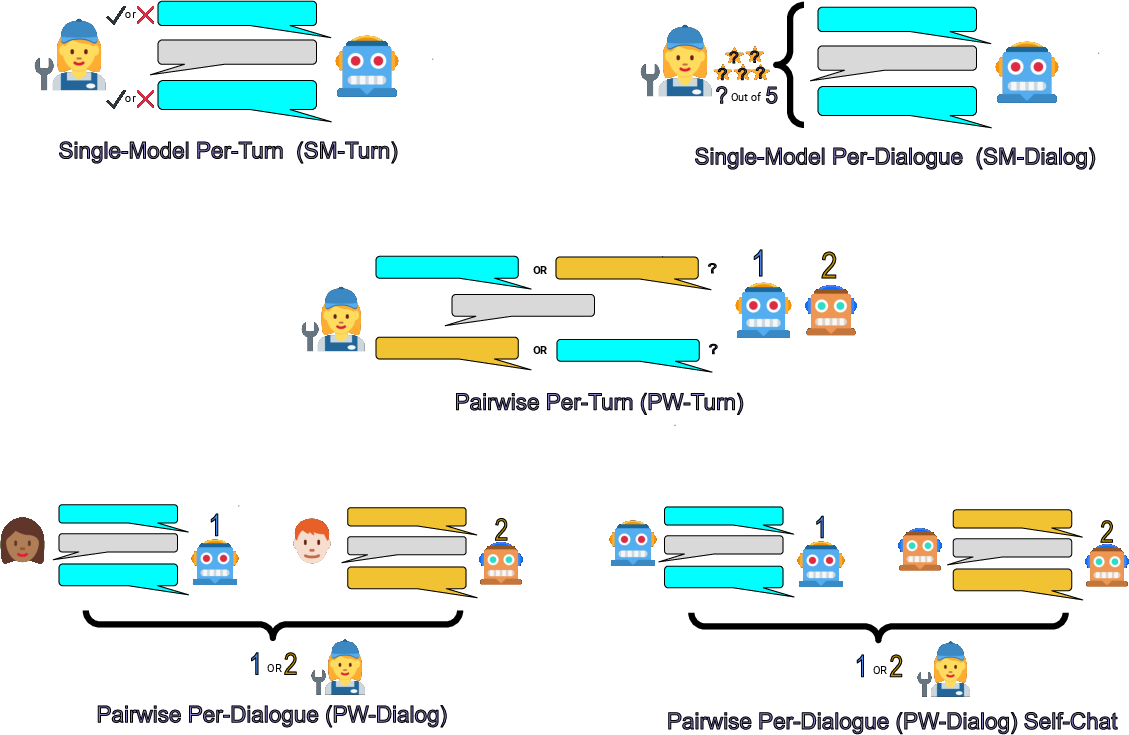
Figure 1: The human evaluation methods compared, depicting both per-turn and per-dialogue, pairwise, and single-model techniques.
Comparative Analysis of Methods
Sensitivity and Practical Viability
Different methods manifest varying sensitivities based on the model comparison dimensions, such as response length, model size, and training regime.
- Length Comparison (BlenderBot3B vs. BlenderBot3B-M0): PW-Dialog demonstrated superior sensitivity in distinguishing output length differences, likely due to the method's ability to capitalize on global conversational context.
- Size Comparison (BlenderBot3B vs. BlenderBot90M): SM-Dialog was marginally more effective in capturing nuanced differences attributable to model size, underscoring the technique's holistic evaluation strength.
- Fine-Tuning Comparison (BlenderBot3B vs. Reddit3B): PW-Turn was found to be particularly sensitive in detecting qualitative response differences introduced through fine-tuning efforts, highlighting its efficacy in capturing turn-level conversational inconsistencies.
These findings are instrumental in guiding the selection of evaluation techniques relative to the specifics of model comparison tasks.
Implications and Future Directions
The paper underscores that human evaluation methods remain an open problem in the assessment of conversational AI. Despite method-specific sensitivities, no single evaluation technique universally excels across all scenarios. A potential area of future work is the development of hybrid techniques that merge per-turn and per-dialogue assessments, enhancing both granularity and global judgment capabilities.
Moreover, the development of automated, trainable metrics that can supplement human evaluations with similar precision but greater efficiency remains a forward-looking objective. Improvements in this area could significantly streamline evaluation pipelines and support rapid iterative development cycles in the field.
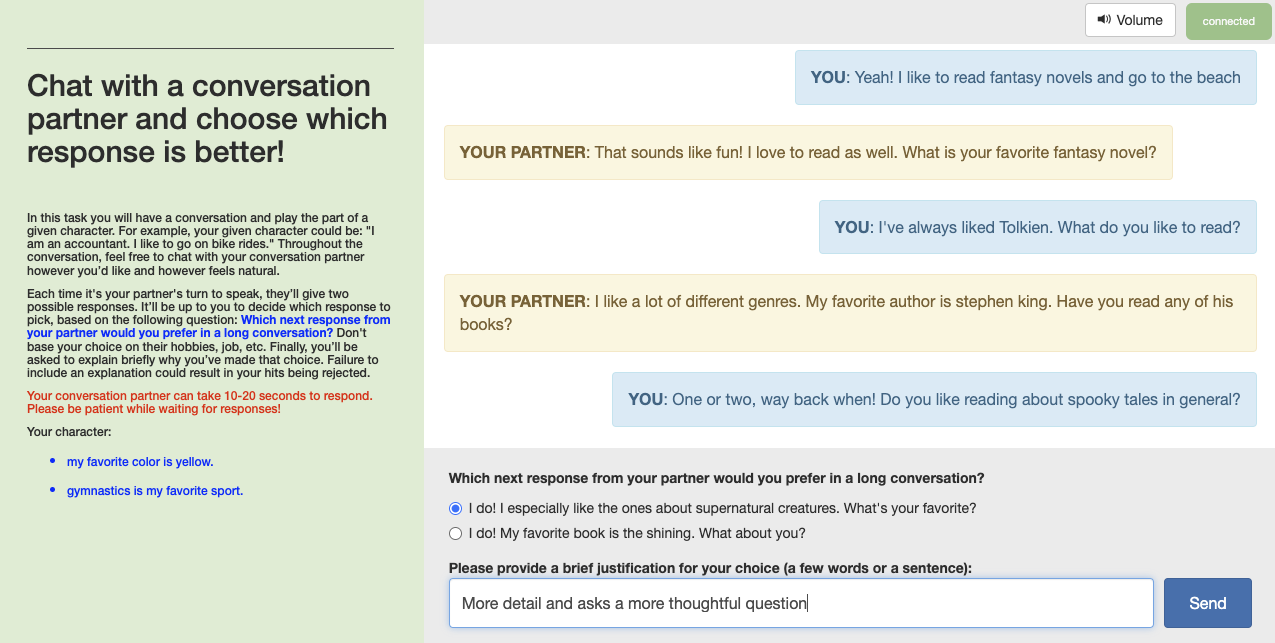
Figure 2: Screenshot of the Pairwise Per-Turn (PW-Turn) evaluation technique, illustrating crowdworker interactions for judging model responses.
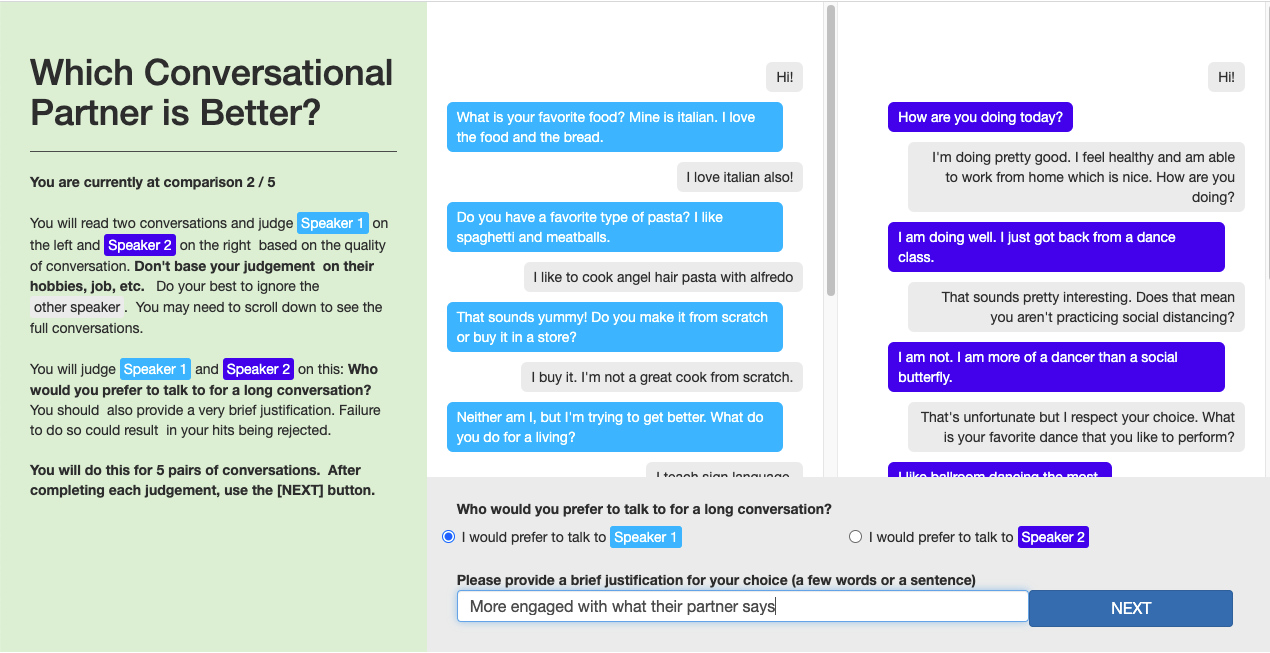
Figure 3: Screenshot of the Pairwise Per-Dialogue (PW-Dialog) evaluation technique, showcasing crowdworker assessments of whole conversations.
Conclusion
This analysis of human evaluation techniques for dialogue agents reveals the importance of context-specific method selection, emphasizing the need for continued refinement and innovation in evaluation methodologies. By tailoring methods to the specific dimensions distinguishing model performance, researchers can achieve more precise and informative evaluations of dialogue systems. These insights pave the way for improved model assessments, ultimately leading to the enhancement of conversational AI technologies.