- The paper presents an innovative online distillation method that compresses conditional GANs by leveraging complementary teacher generators without the need for a discriminator.
- It introduces a multi-granularity scheme where intermediate layers provide channel-wise supervision, enhancing image fidelity across various datasets.
- The approach achieves up to 40× MAC reduction, enabling efficient real-time deployment on mobile and other resource-limited devices.
Online Multi-Granularity Distillation for GAN Compression
Abstract
The paper "Online Multi-Granularity Distillation for GAN Compression" (2108.06908) introduces a novel framework aimed at compressing conditional GAN models, such as Pix2Pix and CycleGAN, while maintaining visual fidelity and significantly reducing computational demands. Traditional GANs are resource-intensive, which limits their deployment on devices with constrained resources. The proposed framework, OMGD, leverages an innovative approach to online distillation, employing complementary teacher generators to refine a student generator without the need for a discriminator and ground truth. This method achieves impressive compression results of up to 40× MACs, making it feasible for real-time applications on resource-constrained devices.
Introduction
Generative Adversarial Networks (GANs) have significantly advanced various visual applications, such as image synthesis and image translation. However, their deployment on lightweight devices is challenged by high computational and memory demands. Recent compression efforts, including knowledge distillation and pruning, have achieved notable progress but still face redundancies and multi-stage processing bottlenecks.
OMGD addresses these issues with a single-stage online distillation scheme adapted for GANs. It abandons complex multi-stage processes, enabling an efficient end-to-end distillation framework. The complementary teacher generators and multi-granularity network layers enhance the visual fidelity of the student generator across multiple dimensions.
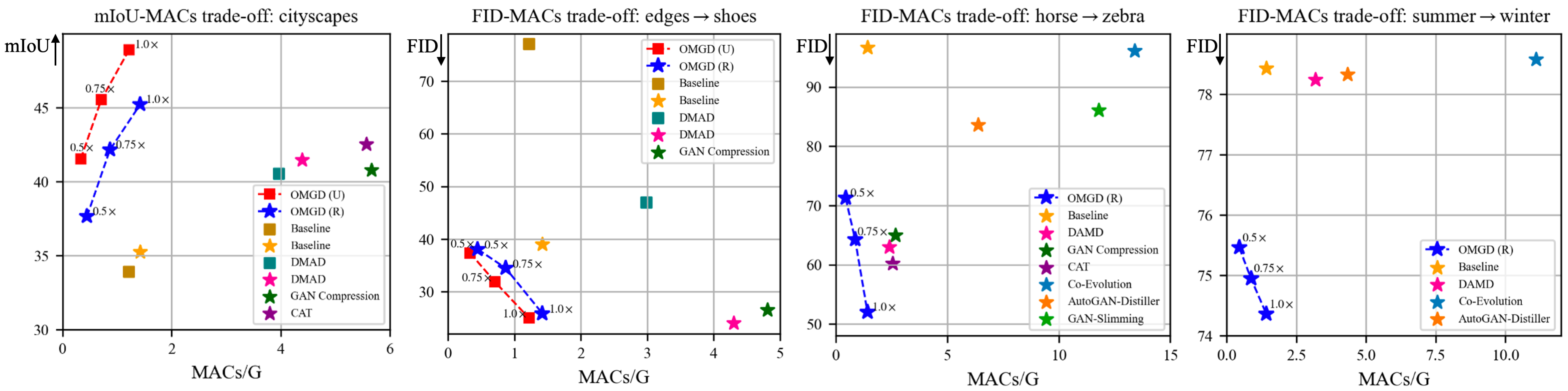
Figure 1: Performance-MACs trade-off illustrating the computational efficiency and superior performance of OMGD compared to other competitive methods.
Methodology
Online GAN Distillation
OMGD introduces an online distillation approach wherein the student generator is optimized directly from the teacher generators without requiring a discriminator. This allows more flexible training and surpasses the constraints of previous methods that tightly couple student with discriminators. The teacher model aids in progressively warming up the student generator, guiding it to achieve superior performance incrementally.
The distillation loss is calculated using SSIM and perceptual losses, ensuring the student learns the structural and style characteristics from the teacher model's outputs.
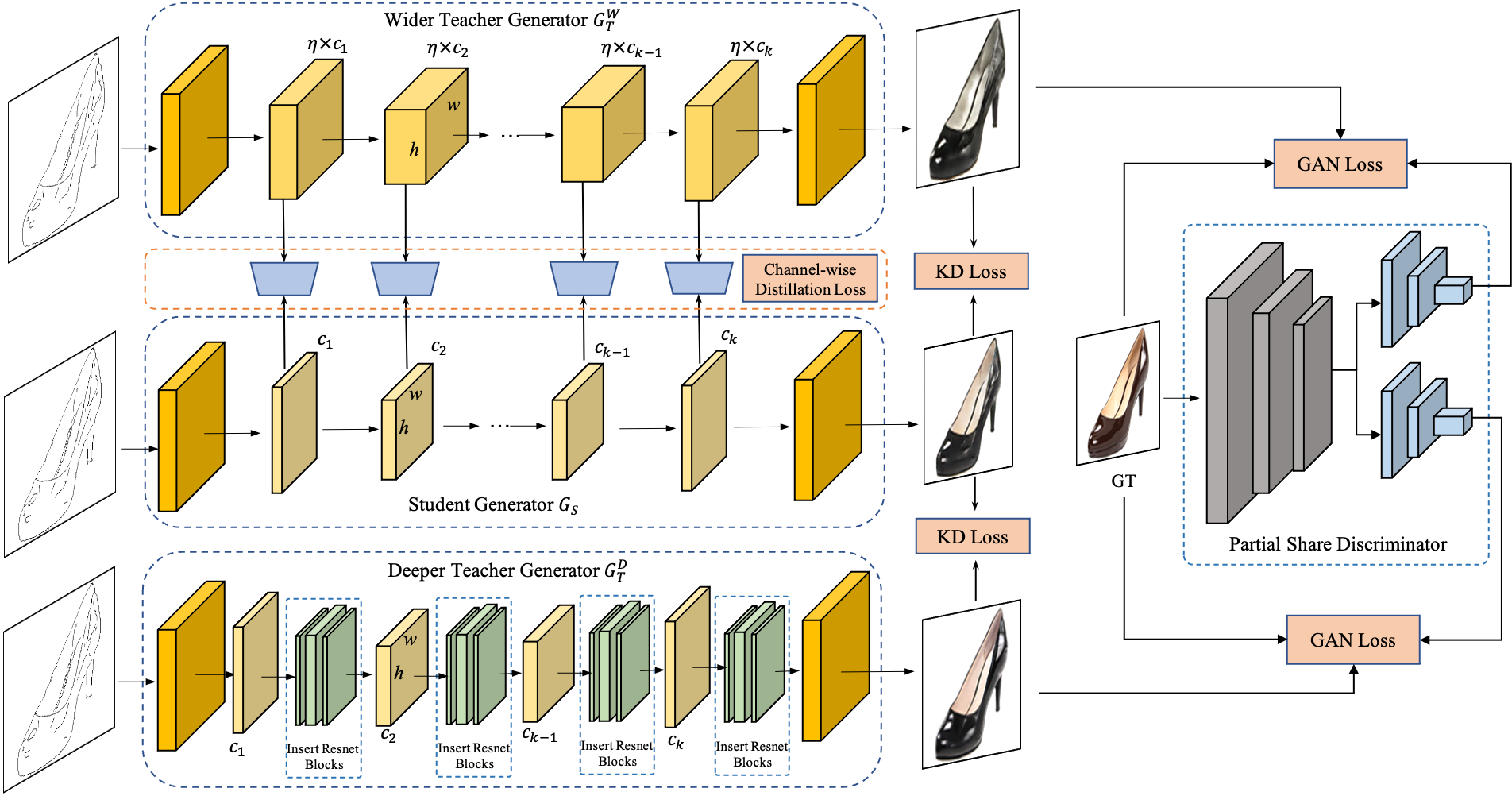
Figure 2: The pipeline of OMGD framework showcasing the interaction between student and teacher generators.
Multi-Granularity Distillation Scheme
The framework expands into a multi-granularity scheme by using complementary structures in teacher generators—wider and deeper architectures provide diverse supervisory cues for optimization. Intermediate layers supplement the distillation process with channel-wise granularity information, enhancing the compressed model's performance without increasing computational complexity.
Experimental Results
Experiments conducted on benchmarks such as horse→zebra, cityscapes, and others demonstrate OMGD's capability to compress GAN models while achieving high fidelity. Against existing methods, OMGD provides better image quality with reduced MACs.
Additional qualitative results underline OMGD's ability to maintain visual fidelity across various datasets, even at high compression rates.

Figure 3: Qualitative compression results showing OMGD's ability to preserve image fidelity across various datasets.
Conclusion
OMGD represents a significant advancement in GAN compression technology, enabling the deployment of real-time image translation models on mobile and other resource-constrained devices. By leveraging online multi-granularity distillation, OMGD effectively balances compression efficiency with image fidelity, potentially transforming practical applications of GANs in edge-device contexts.
The research opens future avenues for improving the robustness and adaptability of online distillation frameworks, hinting at broader applicability across machine learning fields where computational efficiency and model scalability are paramount.