- The paper introduces FiNS, a novel deep learning framework that estimates RIRs directly from reverberant speech using filtered noise shaping.
- It employs a time domain encoder-decoder architecture with multiresolution STFT loss to capture both impulsive and noise-like acoustic components.
- FiNS outperforms existing models in replicating key acoustic parameters such as T60 and DRR, validated by objective metrics and listening tests.
Filtered Noise Shaping for Time Domain Room Impulse Response Estimation From Reverberant Speech
Introduction
The paper "Filtered Noise Shaping for Time Domain Room Impulse Response Estimation From Reverberant Speech" (2107.07503) introduces FiNS, a novel deep learning framework designed to estimate Room Impulse Responses (RIRs) directly from reverberant speech. This research primarily aims at enhancing audio post-production and augmented reality applications by synthesizing accurate RIRs that mimic the acoustics of specific environments. This task is critical for applications like dereverberation, speech recognition, and virtual sound generation, yet traditional measurement techniques face limitations due to environmental constraints.
The core contribution lies in the architecture of FiNS, which consists of a time domain encoder and a filtered noise shaping decoder. FiNS models the RIR as a combination of filtered noise signals and early acoustic reflections, enabling efficient and realistic spatial transformations with a single convolution.
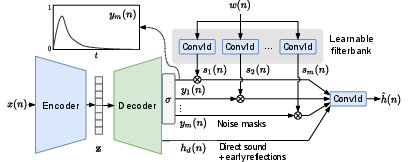
Figure 1: FiNS: Filtered noise shaping RIR synthesis network.
Methodology
The FiNS framework addresses the limitations of existing methods by proposing a blind estimation approach that bypasses the need for direct acoustic parameter measurement. The model considers the room as a linear time-invariant system, where the reverberant speech is the convolution of anechoic speech with the RIR. This approach allows transformation through simple convolution operations without the computational overhead of large models.
The encoder in FiNS employs strided 1-D convolutions to downsample the input signal, capturing both small and large time scales of the RIR. The decoder uses a noise shaping strategy, leveraging the physical properties of room acoustics where late reverberation is modeled as decaying noise. The model is trained using a multiresolution STFT loss to accurately capture both the impulsive and noise-like components of real-world RIRs.
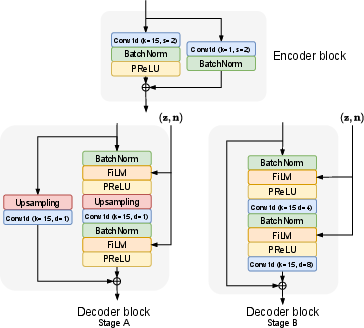
Figure 2: Encoder and decoder block structures.
Results
The evaluation of FiNS demonstrates its effectiveness in generating high-fidelity RIRs that closely match the acoustic characteristics of target environments. Objective metrics indicate the model's proficiency in replicating parameters such as T60 and Direct-to-Reverberant Ratio (DRR) with high accuracy. FiNS outperforms existing deep learning baselines, particularly in generating perceptually realistic RIRs without the ringing artifacts observed in simpler models like Wave-U-Net.
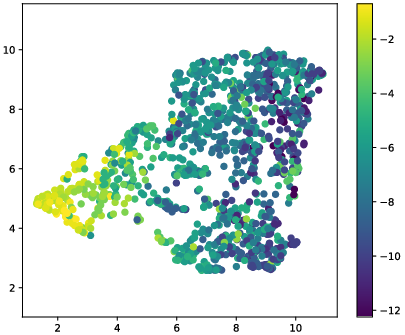
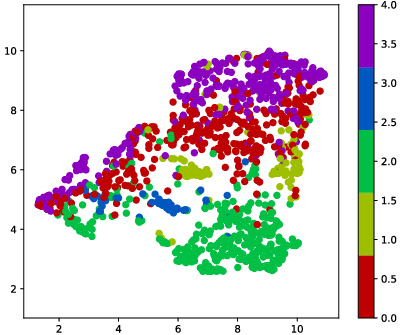
Figure 3: 2-D projections of embeddings from the encoder for unseen examples, colored by (a) ground-truth DRR and (b) room ID.
A subjective listening test further verifies the superiority of FiNS, where listeners rated the FiNS-generated RIRs as more acoustically faithful to the reference recordings than those produced by other models.
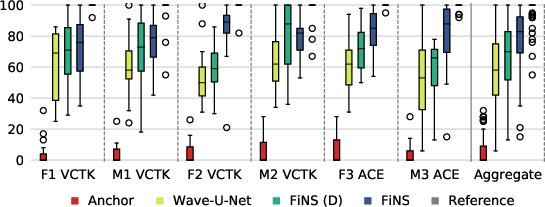
Figure 4: Listening test results.
Discussion and Future Work
The implications of this research are significant for advancements in virtual and augmented reality, particularly in enhancing the realism of audio experiences. FiNS provides a lightweight, efficient means of RIR reconstruction that is scalable and adaptable to various acoustic environments.
Future research directions may include exploring data augmentation techniques to cover a broader array of acoustic settings and employing adversarial training strategies to further refine synthesis quality. Integration with multimedia systems, leveraging audio-visual cues for enhanced environmental modeling, represents another promising avenue for development.
Conclusion
FiNS sets a new benchmark for time domain RIR estimation from reverberant speech, offering a comprehensive solution that combines computational efficiency with perceptual accuracy. This work not only advances current understanding of acoustic modeling but also opens up new possibilities for applications requiring realistic soundfield reproductions.