- The paper introduces the spotlight method that reweights losses in the final representation space to identify systematic errors in deep learning models.
- It demonstrates the method’s effectiveness across various benchmarks, revealing nuanced failure modes without relying on explicit subgroup labels.
- The approach enhances model auditing by efficiently pinpointing problematic input regions that span multiple classes and contextual scenarios.
The Spotlight: A General Method for Discovering Systematic Errors in Deep Learning Models
The paper "The Spotlight: A General Method for Discovering Systematic Errors in Deep Learning Models" (2107.00758) introduces a novel approach, named "the spotlight," for identifying systematic errors in deep learning models, particularly those that do not correspond to explicitly labeled subgroups within the data. The core concept is to leverage the tendency of similar inputs to cluster in the final hidden layer's representation space of a neural network. By focusing on contiguous regions within this space where the model performs poorly, the spotlight method can reveal semantically meaningful areas of weakness in various models across computer vision, NLP, and recommender systems.
Methodology
The spotlight method operates by reweighting the dataset to emphasize instances where the model exhibits poor performance. This reweighting is achieved using a parameterized kernel function applied to the final representation space of the model, effectively focusing on a contiguous region. The weights are computed as ki=max(1−τ(x−μ)2,0), where μ represents the center and τ the precision of the spotlight. The objective function aims to maximize the weighted sum of losses:
$\max_{\mu, \tau} \quad \sum_i{\left( \frac{k_i}{\sum_j{k_j} \right) \ell_i } \quad \textrm{s.t.} \quad \sum_i{k_i} \geq S,$
where S is a hyperparameter determining the minimum "spotlight size," ensuring a lower bound on the total weight assigned by the spotlight. To handle the constraint ∑iki≥S, the paper introduces a penalty term:
b(k)=C⋅max(w2(∑iki−(S+w))2,0),
which penalizes reweightings that include fewer than S+w points, thus converting the constrained optimization into an unconstrained one:
$\sum_i{\left( \frac{k_i}{\sum_j{k_j} \right) \ell_i } - b(k).$
The optimization process starts with a large, diffuse spotlight and iteratively refines its focus using the Adam optimizer, gradually reducing the barrier width w. Multiple distinct spotlights can be optimized on the same dataset by iteratively subtracting spotlight weight from each example's loss and then finding another spotlight. This allows for the identification of multiple failure modes within the same model.
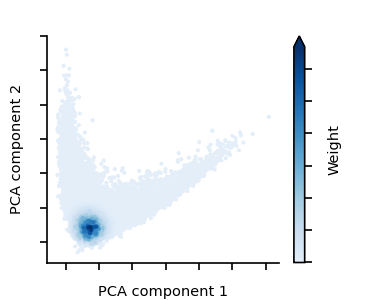
Figure 1: An example of a spotlight in a model's representation space.
Experimental Results
The authors evaluated the spotlight method on a diverse set of pre-trained models and datasets, including FairFace, ImageNet, Amazon reviews, and MovieLens 100k. The results consistently demonstrated the method's ability to uncover systematic issues that would otherwise require explicit group labels to detect.
FairFace
On the FairFace dataset, the spotlights identified various problematic subsets of faces, such as profile views, young children, and faces with shadows or poor lighting (Figure 2). These findings highlighted the model's weaknesses in recognizing faces under specific conditions, without relying on demographic labels.





Figure 2: Spotlights on FairFace validation set. Image captions list true label.
ImageNet
For the ImageNet dataset, the spotlights revealed images that shared a clear "super-class" but were difficult to classify beyond that. For example, one spotlight focused on images of people working, while another highlighted tools and toys (Figure 3). These results indicated the model's challenges in distinguishing between closely related classes.





Figure 3: Spotlights on ImageNet validation set. Image captions list true label.
Amazon Reviews
In the sentiment analysis task using Amazon reviews, the spotlights identified reviews written in Spanish (which the English-trained model misclassified), lengthy reviews of novels, and reviews mentioning customer service aspects. The method effectively pinpointed specific linguistic and contextual elements that influenced the model's performance.
MovieLens 100k
When applied to the MovieLens 100k dataset, the spotlights revealed that the model was uncertain about 3-4 star action and adventure films rated by prolific users, drama films from a small group of users with little reviewing history, and unpopular action and comedy films. These insights demonstrated the spotlight's ability to capture complex interactions between user profiles, movie genres, and rating patterns.
Comparison with GEORGE
The paper compares the spotlight approach with the GEORGE method, which clusters points within a trained neural network's representation space to infer "subclasses" within the dataset. While GEORGE identifies semantically meaningful subsets of data, the spotlight focuses on auditing models, reduces computational costs to linear time, avoids partitioning the entire embedding space, searches only for contiguous, high-loss regions, and identifies issues that involve examples from multiple classes. The authors show that the spotlight can find more granular problem areas within a class or systematic errors that span across multiple classes.
Quantitative Evaluation
The authors compared the spotlight to clusters generated via Gaussian mixture model. The results, shown in Figure 4, indicate that the spotlights effectively identify high-loss regions.
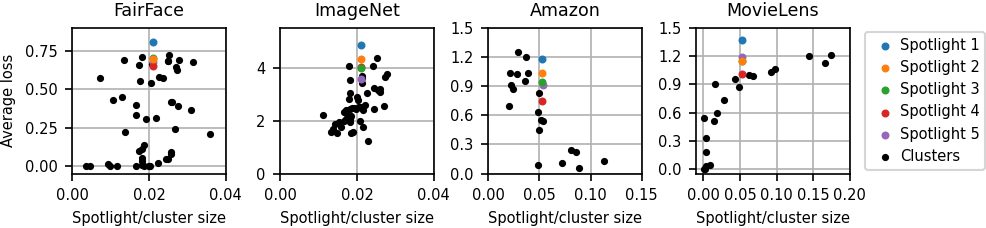
Figure 4: Sizes and average losses for clusters and spotlights. FairFace and ImageNet show spotlights containing 2\% of the dataset and 50 clusters; Amazon reviews and MovieLens show spotlights containing 5\% of the dataset and 20 clusters.
Implications and Future Directions
The spotlight method offers a valuable tool for auditing deep learning models and identifying potential failure modes that are not immediately apparent. By revealing semantically coherent subsets of data where models perform poorly, the method can guide practitioners in improving their datasets, adjusting model architectures, or leveraging robust optimization techniques.
Future research directions include using the spotlight for adversarial training, exploring the structure of representations learned by different models, and investigating spurious correlations. These efforts could lead to more robust and reliable deep learning systems.
Conclusion
The spotlight method provides a computationally efficient and model-agnostic approach for discovering systematic errors in deep learning models. Its ability to uncover meaningful groups of problematic inputs across diverse domains highlights its potential for enhancing the fairness and robustness of deployed AI systems. The method fits into a broader feedback loop of developing, auditing, and mitigating models.