- The paper demonstrates that syntactic probes heavily rely on semantic cues, questioning claims of inherent syntactic understanding in transformer models.
- It employs Jabberwocky sentences that preserve valid syntax while stripping away semantics, exposing limitations in current probing methodologies.
- Experimental results reveal significant performance drops, including a 15.4 UUAS reduction and a 53% decrease in BERT’s edge, urging more refined evaluation techniques.
Do Syntactic Probes Probe Syntax? Experiments with Jabberwocky Probing
Introduction
The interrogative proposition posed by the paper "Do Syntactic Probes Probe Syntax? Experiments with Jabberwocky Probing" evaluates the efficacy of syntactic probes, specifically within the context of whether they truly capture syntactic knowledge without relying heavily on semantic data. The authors challenge the predominant methodology in syntactic probing literature, suggesting these methods conflate syntax with semantics. This conflation could erroneously suggest that models like BERT encode syntactic structures purely based on probe performance.
Methodology
The authors construct a novel evaluation framework using syntactically valid yet semantically nonsensical Jabberwocky sentences to disentangle syntactic and semantic influences in probing results. The core idea is to utilize a corpus where semantics are stripped away, based on Carroll's concept of "Jabberwocky," resulting in sentences that still maintain valid syntactic structure but lack lexical semantics.
Two prevalent probes are deployed: a structural probe, which estimates syntactic distances directly from word pair embeddings, and a perceptron probe, which learns these distances to form a minimum spanning tree that corresponds to syntactic relationships. These probes are trained on conventional corpora and then evaluated on newly crafted Jabberwocky data using three transformer models: BERT, GPT-2, and RoBERTa.
Experimental Results
The results demonstrate a significant performance drop when probes are transitioned from evaluating real-world sentences to Jabberwocky constructions. For the perceptron probe, a notable reduction in performance by an average of 15.4 UUAS points was observed across models. BERT's competitive advantage diminished by 53% in the comparison to simplistic baselines when evaluated via structural probes (Figure 1).
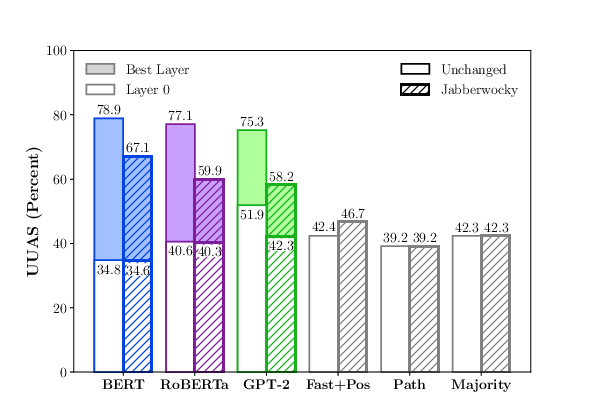
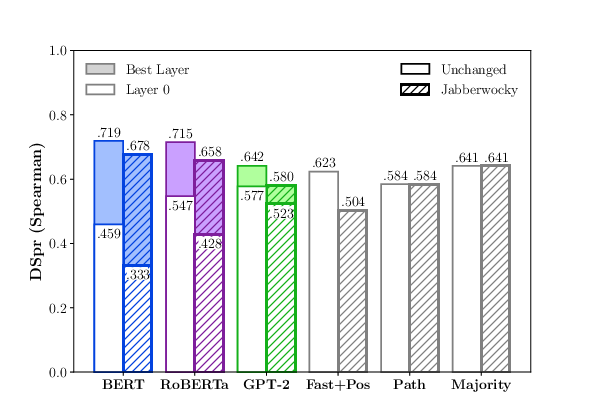
Figure 1: How the models perform when the probes are evaluated on unchanged sentences versus the Jabberwocky.
Discussion
The study indicates that syntactic probes largely rely on semantic cues embedded in training data to produce syntactic predictions, suggesting that existing claims of syntactic knowledge in models such as BERT might be overestimated. The baselines, devoid of any syntactic information, demonstrate surprisingly strong performance, further cautioning against claims that transformer LLMs inherently understand syntax.
Importantly, recognizing the limitations of probing methodologies, the authors assert that these reductions could be indicative of probe inadequacies rather than the incapacity of models themselves. A vital takeaway is the need for meticulous experimentation and control over semantic influences to genuinely evaluate a model's syntactic acumen.
Conclusion
The research calls for a refined approach to evaluate syntactic knowledge in pre-trained models, advocating for a separation of syntax from semantics within probing studies. Future endeavors could involve constructing artificial treebanks eschewing semantic cues to facilitate unbiased syntactic probing. This work not only questions the broader claims of BERT's syntactic prowess but also sets a roadmap for developing more nuanced and accurate probing methodologies. As the field progresses, such rigorous explorations will be critical in advancing our understanding of the true linguistic capabilities encapsulated in neural LLMs.