- The paper demonstrates that lower perplexity, typically seen as a marker of human-like behavior, does not predict psychometric performance in Japanese.
- The study employs over three dozen language models and analyzes eye movement data to evaluate model surprisal and ΔLogLik across languages.
- The paper advocates for language-specific model tuning to capture nuanced cognitive processing beyond uniform perplexity-based measures.
Lower Perplexity is Not Always Human-Like
Introduction
The paper "Lower Perplexity is Not Always Human-Like" explores the relationship between perplexity (PPL) in LMs and their human-like behavior as evidenced by psychometric predictive power. Traditionally, a lower PPL in LMs is often equated with superior human-like qualities, particularly in the context of English. This study challenges that assumption by examining this relationship in Japanese, which has markedly different linguistic structures compared to English. The findings highlight significant differences in how PPL correlates with psychometric predictive power across these two languages.
Human-Like LLMs and Perplexity
The core assumption in psycholinguistics has been that lower PPL, indicative of a model's ability to predict subsequent words effectively, correlates positively with the model's ability to mimic human reading behaviors. This is typically evaluated through metrics such as surprisal, which quantifies the unexpectedness of a word given its previous context. The human cognitive process tends to vary the ease of processing based on such linguistic surprisals, explaining the utility of LMs in this domain.
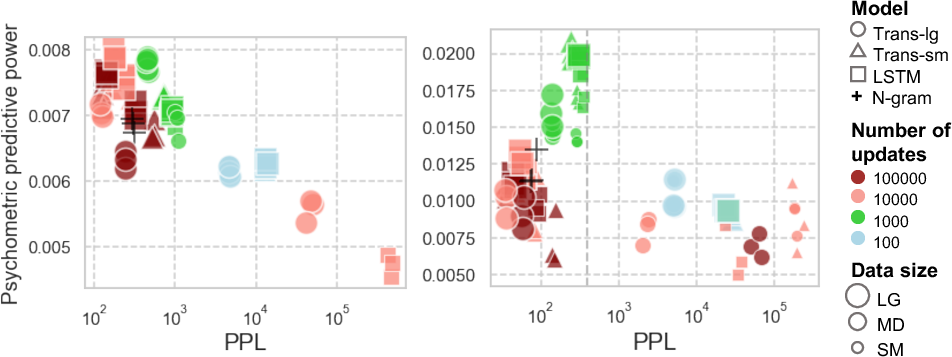
Figure 1: Relationship between PPL and psychometric predictive power, i.e., DeltaLogLik, in English and Japanese languages.
Methodology and Experimental Setup
The study involves training a variety of LMs on syntactically diverse languages, specifically English and Japanese. Over three dozen different LMs were utilized, varying in architecture, training data size, and parameter updates. The evaluation involves analyzing LM surprisals against human eye movement data, focusing on the relationship between the LM's linguistic accuracy (PPL) and psychometric predictive power (ΔLogLik) for two different languages.
Key Findings
A pivotal finding from the paper is that the positive correlation between low PPL and high psychometric predictive power observed in English does not generalize to Japanese. For Japanese, the results show an inverse relationship under certain conditions—lower PPL does not necessarily implicate stronger alignment with human cognitive processes during reading.
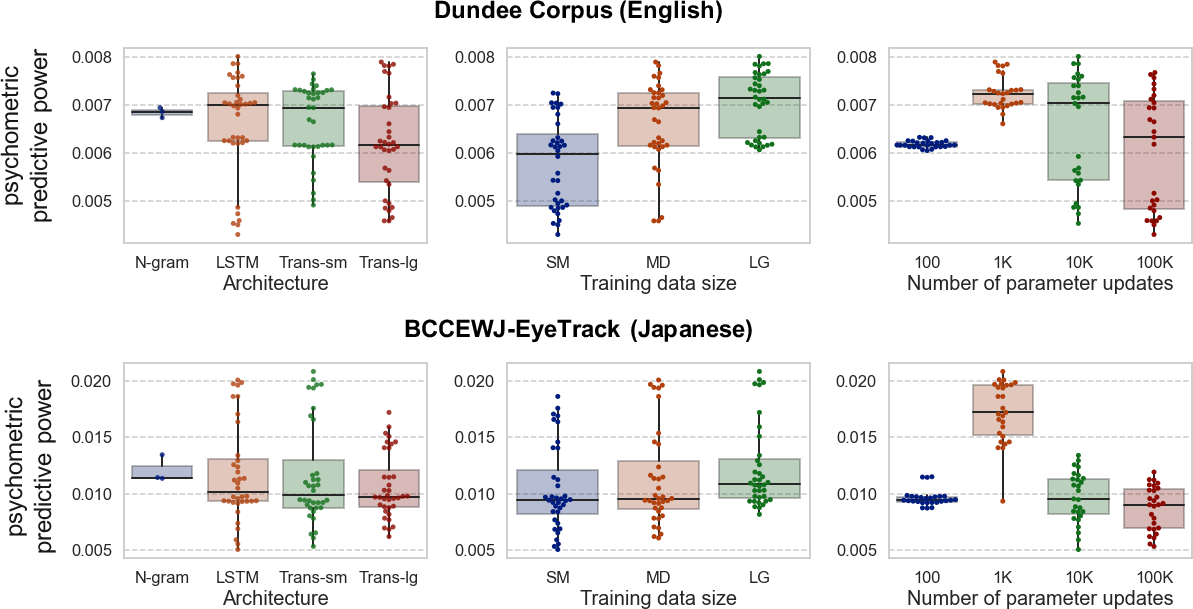
Figure 2: Separate effect of model architecture, training data size, and the number of parameter updates for LMs' psychometric predictive power in each language.
Analysis and Hypothesis
This discrepancy is further analyzed through the uniform information density (UID) hypothesis, which suggests that cognitive processing efficiency is a function of maintaining a constant flow of information. The study finds that Japanese language processing exhibits greater nonuniformities, potentially due to its syntactic structures and reading habits compared to English. Specifically, Japanese segments show greater variability in gaze durations across sentences, a factor that might not align well with the predictive uniformity targeted by low-PPL LMs.
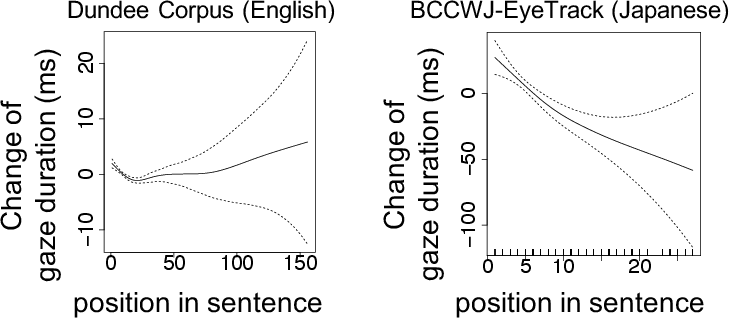
Figure 3: Uniformity of gaze duration with respect to segment position in a sentence.
Implications for Language Modeling
The paper suggests that optimizing LMs purely for lower PPL might obscure language-specific cognitive phenomena, such as in Japanese where anti-locality effects are more pronounced. It advocates for a more nuanced approach that accounts for linguistic diversity in modeling human-like language processes across different languages.
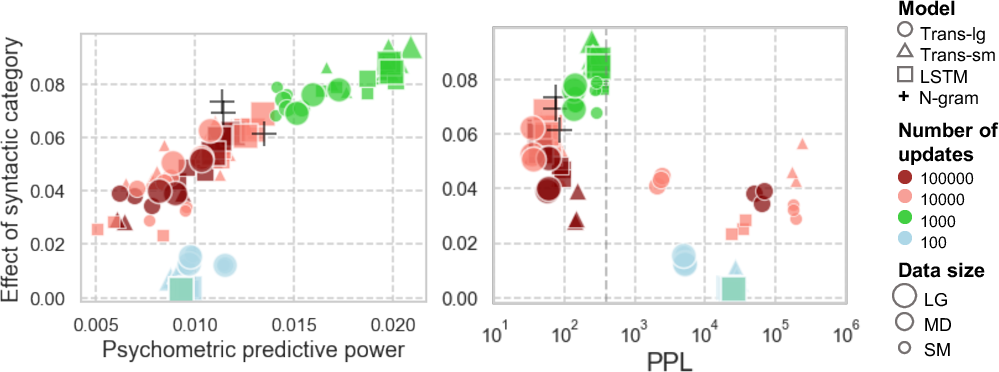
Figure 4: Relationship between the LM's psychometric predictive power and the effect of the syntactic category on the surprisal computed by each LM.
Conclusion
The investigation underscores the importance of re-evaluating the reliance on PPL as a sole measure of human-likeness in LLMs. It opens avenues for further research into language-specific tuning of LMs to enhance their applicability in cross-linguistic contexts. By questioning the universality of PPL as a measure of human-like behavior, the study enriches the ongoing discourse on creating more linguistically and cognitively informed computational models.
Future Directions
The paper's findings invite future work on expanding the scope of cross-lingual evaluations and exploring additional linguistic phenomena beyond PPL. There is a clear impetus to gather more comprehensive reading behavior data across diverse languages, which could inform the development of LMs that better integrate nuanced human cognitive processes.