Recent Advances in Monocular 2D and 3D Human Pose Estimation: A Deep Learning Perspective
Abstract: Estimation of the human pose from a monocular camera has been an emerging research topic in the computer vision community with many applications. Recently, benefited from the deep learning technologies, a significant amount of research efforts have greatly advanced the monocular human pose estimation both in 2D and 3D areas. Although there have been some works to summarize the different approaches, it still remains challenging for researchers to have an in-depth view of how these approaches work. In this paper, we provide a comprehensive and holistic 2D-to-3D perspective to tackle this problem. We categorize the mainstream and milestone approaches since the year 2014 under unified frameworks. By systematically summarizing the differences and connections between these approaches, we further analyze the solutions for challenging cases, such as the lack of data, the inherent ambiguity between 2D and 3D, and the complex multi-person scenarios. We also summarize the pose representation styles, benchmarks, evaluation metrics, and the quantitative performance of popular approaches. Finally, we discuss the challenges and give deep thinking of promising directions for future research. We believe this survey will provide the readers with a deep and insightful understanding of monocular human pose estimation.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Recent Advances in Monocular 2D and 3D Human Pose Estimation: A Deep Learning Perspective”
Overview
This paper is a “survey,” meaning it summarizes and explains many research papers on the same topic. The topic is how computers can figure out the positions of a person’s body parts (like elbows, knees, and shoulders) from pictures or videos taken by just one camera. It covers both:
- 2D pose (where joints are on the image, like a stick figure drawn on a photo)
- 3D pose (how joints are located in space, including depth, like a 3D mannequin)
It focuses on how deep learning (a type of artificial intelligence) has made big improvements since 2014, and how ideas in 2D and 3D are connected.
Key Objectives and Questions
The paper aims to answer simple but important questions:
- What are the main deep learning methods for 2D and 3D human pose estimation from one camera?
- How do 2D and 3D ideas connect and help each other?
- What are the biggest problems, like lack of 3D training data, tricky camera angles, and crowded scenes?
- What are the common ways to represent the human body in a computer (like stick figures or 3D mannequins)?
- Which datasets, benchmarks, and evaluation metrics are used to compare methods?
- Where is the field heading next?
Methods and Approach (with everyday analogies)
This is a survey paper, so instead of running one experiment, it organizes and explains many methods under simple, shared “frameworks.” Think of it like sorting different kinds of tools into labeled boxes, then showing how they work and relate.
Here are the core ideas and terms, explained simply:
- Pose Encoder–Decoder: Imagine a system that first “reads” the image to understand it (encoder), then “draws” the stick figure or 3D body (decoder). Most modern methods use this two-part design.
- Detection vs. Regression:
- Detection: The model makes heatmaps—like a weather map with “hot spots” where joints are likely to be.
- Regression: The model directly outputs exact coordinates (like giving precise X and Y for the elbow).
- Top-Down vs. Bottom-Up (for multiple people in one image):
- Top-Down: First find each person’s bounding box, then find their joints inside it—like spotting people in a crowd, then zooming in to draw their stick figures.
- Bottom-Up: First detect all joints in the whole image, then group them into different people—like finding all puzzle pieces, then sorting them into person-shaped sets.
- Body Representations:
- Keypoints (2D/3D): The simplest “stick figure” joints and lines.
- Heatmaps: “Warm areas” marking where joints probably are.
- Part Affinity Fields (PAFs): Little arrows connecting joints, like ropes showing which wrist belongs to which elbow.
- SMPL Model: A detailed 3D mannequin with adjustable shape and pose; think of it as a smart 3D puppet with sliders for size and limb rotations.
- 3D-to-2D Projection (camera models): Turning 3D points into 2D image positions is like casting a shadow. The paper explains:
- Perspective camera: A realistic projection with camera geometry.
- Weak perspective: A simpler approximation used when the exact camera isn’t known.
- Handling Challenges:
- Limited 3D Data: Training on lots of 2D data and using 2D as a stepping stone to 3D.
- Ambiguity (many 3D bodies can look the same in 2D): Use body structure rules, motion over time, and multiple views when possible.
- Crowds and Occlusions: Special methods to handle overlapping people, cut-off limbs, blurry images, and small people in the distance.
- Videos: Methods use time information—like tracking motion—to improve accuracy. Optical flow (tracking how pixels move) and sequence models (like LSTMs or transformers) help keep poses consistent across frames.
- Benchmarks and Datasets: The paper summarizes popular datasets (like COCO, MPII, Human3.6M, 3DPW) and how methods are scored, making it easier to compare results.
- Toolbox: The authors share a code toolbox to help researchers process 3D pose data.
Main Findings and Why They Matter
The big takeaways:
- Common Frameworks: Despite many different methods, most follow similar designs (encoder–decoder; top-down or bottom-up), which helps researchers understand and improve them.
- 2D Boosted First, Then 3D: Around 2016, new ideas and big datasets sparked rapid progress in 2D. 3D methods then improved by borrowing tricks from 2D and by using better 3D models.
- 2D Helps 3D: Because 3D data is hard to get, many methods learn from large 2D datasets and use clever camera projections to bridge the gap.
- Handling Tough Cases: Methods now better deal with crowds, occlusions, and tiny people in photos by using extra cues (like PAFs, multi-stage refinement, and high-resolution features).
- Unified View: The paper connects dots across 2D and 3D, single-person and multi-person, and image and video methods—showing their similarities and differences clearly.
- Practical Tools: Summaries of datasets, evaluation metrics, and a shared code toolbox make it easier to build and compare new methods.
This matters because understanding and predicting human pose is key for:
- Sports analytics and motion capture
- VR/AR and 3D movie editing
- Safety and self-driving (detecting pedestrians)
- Human–robot interaction and healthcare (rehabilitation, activity monitoring)
Implications and Future Impact
The paper points to promising directions:
- Better 3D in the wild: Create or learn from more realistic 3D data, not just lab recordings.
- Stronger 2D–3D connections: Use structure rules, motion continuity, and multi-view consistency to reduce ambiguity.
- Multi-person 3D: Move beyond single-person 3D to handle crowds in full 3D.
- Efficiency: Build faster, lighter models that work on phones and robots.
- Multi-task learning: Combine pose with related tasks (like body part segmentation or action recognition) to get richer, more robust results.
Overall, the survey gives researchers a clear map of the field, helping them choose the right tools, understand trade-offs, and spot the most impactful problems to solve next.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of concrete gaps and unresolved questions highlighted by (or implicit in) the survey, which can guide future research:
- Dataset standardization: Lack of unified skeleton definitions, joint naming, and SMPL joint regressors across datasets impedes cross-dataset training and fair comparisons; actionable need for conversion tools and protocols that guarantee consistent evaluation.
- Evaluation metrics: Over-reliance on PCK/AP for 2D and MPJPE/PA-MPJPE for 3D fails to capture limb orientations, bone-length consistency, occlusion handling, identity switches in video, and anatomical plausibility; standardized metrics and leaderboards reflecting these aspects are missing.
- Camera model realism: Widespread use of weak-perspective assumptions leaves open how to learn robustly under unknown intrinsics, strong perspective effects, and varying focal lengths; benchmark splits with known intrinsics and protocols for perspective-correct training/evaluation are needed.
- 2D→3D ambiguity: Few methods explicitly model multi-modal 3D solutions consistent with a single 2D pose; actionable directions include probabilistic multi-hypothesis 3D predictors with calibrated uncertainty and appropriate evaluation protocols.
- In-the-wild 3D scarcity: Persistent lack of large, diverse 3D annotations for outdoor, crowded, occluded, and action-rich scenes (and diverse demographics) remains unresolved; scalable self-/weak-/semi-supervised pipelines that fuse 2D labels, multi-view consistency, motion priors, and pseudo-labeling need systematic benchmarking.
- Cross-dataset generalization: Models trained on lab datasets (e.g., Human3.6M) often fail in the wild; there is no standardized cross-dataset generalization protocol or baselines for both 2D and 3D settings.
- Bottom-up grouping at scale: Associating detected keypoints to individuals remains brittle in crowded scenes and heavy truncation; need end-to-end differentiable grouping that is robust to long-range limb associations, small instances, and dense crowds with theoretical and empirical scalability analyses.
- Top-down dependence on detection: Pose accuracy remains bounded by person detector recall for small/low-resolution instances; robust joint learning with detection super-resolution, multi-scale features, and explicit small-object strategies requires standardized evaluation and ablations.
- Multi-person 3D from monocular input: Depth ordering, occlusion reasoning, and inter-person constraints in single-image or video 3D remain largely unresolved; benchmarks and methods for joint 3D estimation, identity-consistent tracking, and interaction-aware modeling are needed.
- Temporal modeling: Long-horizon temporal coherence for both 2D and 3D (handling missed detections, drift, and online latency constraints) lacks standardized tasks and metrics; methods integrating causal models with uncertainty and identity consistency are underexplored.
- Occlusion reasoning: While occlusion-aware augmentations exist, there is a lack of explicit visibility modeling, occlusion labels, and structured reasoning modules evaluated under controlled “crowd index” regimes across datasets.
- Human–object and scene interaction: Current pipelines rarely incorporate contact constraints, scene geometry, or physical plausibility; datasets with contact annotations and models enforcing contact/penetration constraints are needed for realistic predictions.
- Whole-body integration: 2D whole-body estimation exists, but 3D whole-body (body–hand–face) with consistent kinematic frames, scales, and synchronized training remains largely missing; unified datasets and architectures are needed.
- Beyond minimally clothed shape: SMPL-based pipelines underrepresent clothed humans and garment dynamics; datasets and representations capturing clothing, accessories, and soft-tissue dynamics (and their effect on keypoints/mesh) are scarce.
- Physics/biomechanics priors: Few methods enforce biomechanical limits (joint angle limits, symmetry), dynamics, or differentiable physics; designing and evaluating physically plausible pose/shape predictors is an open direction.
- Uncertainty and calibration: Keypoint and 3D mesh predictions often lack calibrated confidence estimates, hindering downstream NMS, tracking, and safety-critical use; benchmarks for calibration error and uncertainty-aware evaluation are needed.
- Robustness: Sensitivity to motion blur, illumination, compression, camera shake, and adversarial perturbations is understudied; standardized robustness suites and data augmentations reflecting real-world distortions are missing.
- Efficiency and deployment: There is no widely adopted benchmark for accuracy–speed–memory–energy trade-offs on edge and mobile hardware for single- and multi-person settings; reproducible profiles under fixed resolutions and crowd levels are needed.
- Training augmentation: Adversarial/data-driven augmentations show promise, but there’s a lack of principled, task-driven augmentation suites that reflect real camera artifacts, occluders, and domain shifts, with standardized ablation protocols.
- Annotation noise and semi-supervision: The impact of noisy 2D labels (visibility ambiguities, annotation bias) and scalable semi-supervised learning with large unlabeled video/image corpora lacks systematic study and benchmarks.
- Domain adaptation/generalization: Few strong baselines exist for synthetic→real and lab→wild adaptation in both 2D and 3D; methods leveraging style, geometry, and motion invariances need consistent evaluation protocols.
- Ethical and fairness considerations: The survey and most benchmarks do not analyze performance across demographics (age, body type, skin tone) or contexts; curated fairness splits and bias-mitigation baselines are lacking.
- Privacy-preserving learning: Federated/on-device training and privacy-aware inference for pose from sensitive imagery is not addressed; practical protocols and methods remain open.
- Reproducibility and unified pipelines: Despite a released 3D toolbox, the community lacks unified, reference training/evaluation pipelines that cover 2D and 3D, single/multi-person, and image/video with consistent preprocessing, skeleton mapping, and metrics.
- Differentiable 3D–2D supervision: While projections are used, learning under unknown intrinsics/extrinsics and lens distortion in the wild remains underexplored; general-purpose differentiable camera models and self-calibration in-the-wild are needed.
- Texture and appearance: Extending from pose/shape to realistic texture under uncontrolled lighting with differentiable rendering remains nascent; benchmarks and methods for self-supervised texture recovery in the wild are needed.
Glossary
- Associative embedding: A technique that assigns learned tags to keypoints so they can be grouped into individual persons. "associative embedding for joint grouping~\cite{17BU_newell2017associative}"
- axis-angle representation: A way to represent 3D rotations using a vector’s direction as the axis and length as the angle. "in the axis-angle representation."
- bi-directional tree-structured model: A structure that propagates information both up and down a hierarchical body-part tree. "a bi-directional tree-structured model."
- Binarized neural network: A neural network using binary weights and/or activations to reduce computation and memory. "The Binarized neural network is first exploited in~\cite{17SP_BulatT17a}"
- bottom-up paradigm: A pipeline that detects all keypoints first and then groups them into persons. "the bottom-up paradigm first detects all target outputs and then assign them to different people"
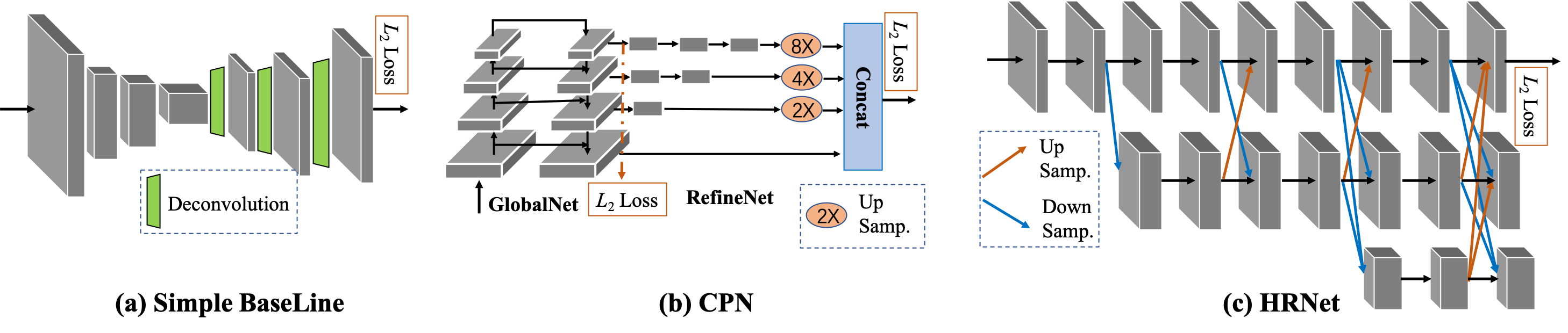
- Convolutional Pose Machine (CPM): A multi-stage CNN with intermediate inputs and supervision for progressive keypoint refinement. "Convolutional Pose Machine (CPM)~\cite{SP16-CPM}"
- cylinder model: A volumetric body-part representation that models limbs as cylinders to handle occlusion. "the cylinder model was developed to generate the labels of occluded parts."
- deconvolution layers: Transposed convolution layers used to increase the spatial resolution of feature maps. "three deconvolution layers"
- deeply learned compositional model (DLCM): A hierarchical model that infers body parts via bottom-up and top-down stages across semantic levels. "the deeply learned compositional model (DLCM)"
- EllipBody model: An ellipsoid-based volumetric body representation providing more flexibility than cylinders. "an EllipBody model is proposed"
- extrinsic matrix: The camera rotation and translation matrix mapping 3D points into camera coordinates. "the extrinsic matrix "
- Gaussian heatmap: A heatmap representation placing a Gaussian peak at each keypoint’s location. "the Gaussian heatmap of each keypoint"
- Generative Adversarial Networks (GANs): An adversarial learning framework used to impose pose plausibility constraints. "by the conditional Generative Adversarial Networks (GANs)."
- graph pose refinement module: A component that refines predicted keypoints by modeling their relationships as a graph. "a graph pose refinement module"
- Hourglass Residual Units (HRUs): Residual blocks designed to expand the receptive field within hourglass architectures. "Hourglass Residual Units (HRUs)"
- integer linear programming (ILP): An optimization approach used to globally assign detected keypoints to persons. "as an integer linear programming (ILP)."
- intrinsic matrix: The camera’s internal parameter matrix used for accurate 3D-to-2D projection. "the intrinsic matrix "
- kinematic tree: A hierarchical skeleton structure that defines parent-child relationships among joints. "following a kinematic tree."
- Markov Random Field-like model: A probabilistic model capturing spatial dependencies among joints to penalize implausible poses. "an Markov Random Field-like model"
- Non-Maximum-Suppression (NMS): A post-processing technique to remove redundant pose detections. "pose Non-Maximum-Suppression (NMS)~\cite{17MP_papandreou2017towards}"
- occlusion relational graphical model: A structured model that encodes interactions between body parts and objects under occlusion. "an occlusion relational graphical model"
- online hard keypoints mining (OHKM) loss: A loss that emphasizes training on difficult keypoints to improve accuracy. "an online hard keypoints mining (OHKM) loss"
- orthographic projection operation: A projection that maps 3D points to 2D without perspective distortion, preserving scale. "an orthographic projection operation"
- Part Affinity Fields (PAFs): 2D vector fields encoding limb orientations to associate detected keypoints. "part affinity fields (PAFs)"
- Part-based volumetric model: A body representation that approximates parts with simple 3D volumes to aid training and occlusion handling. "Part-based volumetric model."
- parametric pose NMS: A learned non-maximum suppression strategy tailored to pose hypotheses. "a parametric pose NMS"
- Perspective camera model: A camera model that projects 3D points onto the 2D image plane with perspective foreshortening. "Perspective camera model."
- PoseNAS: A neural architecture search approach that automatically designs pose-specific feature encoders. "PoseNAS~\cite{20_MP_PoseNAS}"
- Pose Refine Machine (PRM): A module that refines keypoints by balancing local and global representations. "a Pose Refine Machine (PRM) module"
- receptive field: The input region influencing a neuron’s activation, affecting context captured by the network. "to increase the receptive field of the stacked hourglass network."
- Residual Steps Network (RSN): A multi-stage architecture that aggregates features within levels to produce delicate local representations. "Residual Steps Network (RSN)"
- skinned multi-person linear model (SMPL): A parametric 3D mesh model that disentangles human body pose and shape. "skinned multi-person linear model (SMPL)~\cite{smpl}"
- skip connection layer: A connection that links features of the same resolution to preserve spatial details. "skip connection layer"
- stacked hourglass network: A repeated encoder-decoder architecture with intermediate supervision for pose estimation. "the stacked hourglass network~\cite{16SP_NewellYD16}"
- statistical 3D human body model: A learned 3D body mesh model capturing population-level shape and pose variations. "the statistical 3D human body model."
- Temporal Flow Fields: Motion fields that encode temporal associations between keypoints across frames. "Temporal Flow Fields-based model"
- top-down paradigm: A pipeline that first detects persons and then estimates each person’s pose within their bounding boxes. "the top-down paradigm first detects the person areas and then extracts the bounding box-level features"
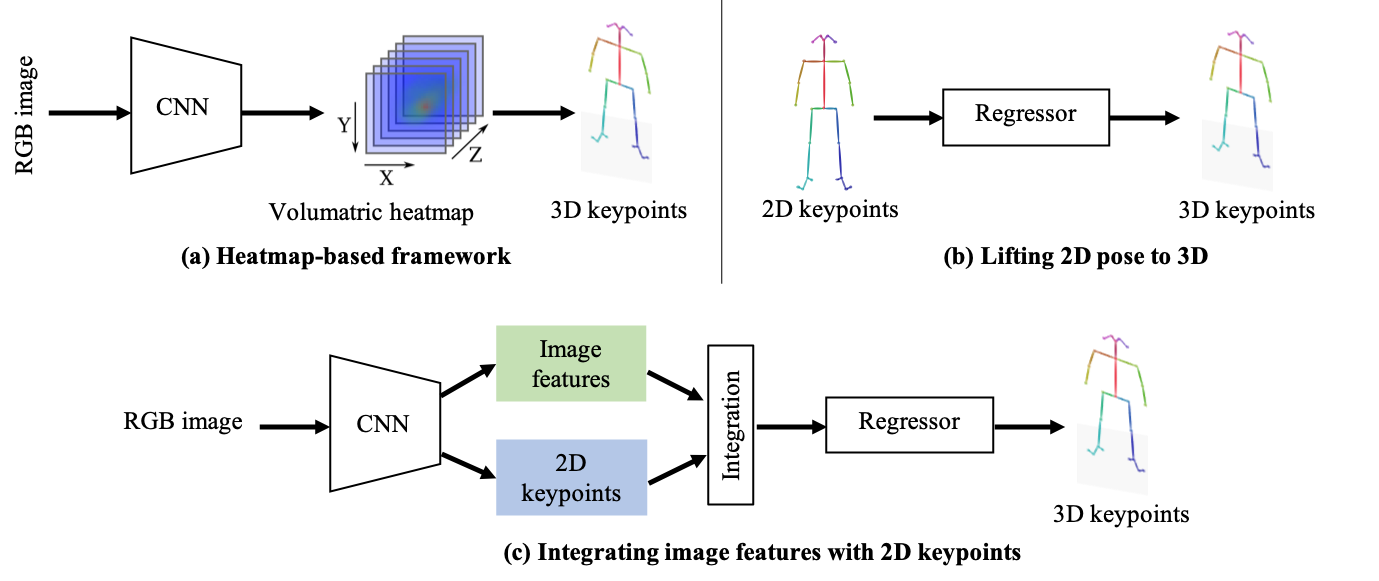
- volumetric heatmap: A 3D heatmap representation that encodes keypoint likelihoods over spatial volume. "volumetric heatmap"
- weak-perspective camera model: An approximate camera model that uses a global scale and rotation with orthographic projection. "Weak-perspective camera model."
Practical Applications
Immediate Applications
Below are deployable applications that can be built now by composing surveyed methods (e.g., top-down and bottom-up 2D pose estimators, video tracking, 3D lifting with SMPL, 3D-to-2D reprojection losses, occlusion-aware refinement, lightweight/edge models).
- Healthcare — Remote physiotherapy and musculoskeletal assessment
- Workflow: smartphone/tablet video capture → 2D keypoints (HRNet, SimpleBaseline, MSPN) → optional 3D lifting (HMR/SPIN with SMPL + weak-perspective projection) → range-of-motion and symmetry analytics dashboards; session progress tracking.
- Tools/methods: HRNet, CPN/MSPN, PoseFix for refinement, video temporal models for stability; SMPL-based metrics; 3D-to-2D projection for weak supervision.
- Assumptions/dependencies: clinical validation, consistent camera placement and lighting, privacy-compliant data handling, domain adaptation for diverse body shapes and clothing.
- Sports and Fitness — Performance analysis and coaching
- Workflow: live or recorded video → multi-person 2D pose (top-down with HRNet or bottom-up OpenPose/HigherHRNet) → action-specific kinematic features → feedback and training plans; for team sports, player tracking across frames (KeyTrack, PoseFlow).
- Tools/methods: OpenPose/PAFs, Associative Embedding for grouping, CrowdPose-tuned models for dense scenes, KeyTrack/Detect-and-Track for video; mobile-friendly models via distillation/binarization.
- Assumptions/dependencies: camera vantage points, occlusion in games, need for sport-specific calibration and ground truth for accuracy claims.
- AR/VR and Gaming — Body-driven avatars and interaction
- Workflow: monocular webcam/phone → 2D pose (HRNet or lightweight MobileNet-based hourglass) → retarget to avatar skeleton; for hands/face add whole-body models (ZoomNet, whole-body OpenPose).
- Tools/methods: whole-body keypoints (body, hands, face), multi-stage refinement, on-device inference via binarized networks or distillation (FPD).
- Assumptions/dependencies: latency constraints, robust tracking under motion blur/lighting, acceptable drift for consumer UX.
- Film/Media/Animation — Markerless mocap previsualization
- Workflow: multi-camera optional but monocular-friendly → multi-person 2D pose + 3D lifting (SPIN/HMR; coarse mesh via SMPL) → animation clean-up.
- Tools/methods: SMPL, coarse-to-fine refinement, occlusion-aware models (OASNet), compositional models (DLCM) for complex poses.
- Assumptions/dependencies: heavy occlusion and clothing still challenging; final production may require manual cleanup.
- Retail and Customer Analytics — Footfall and in-store interaction analysis
- Workflow: ceiling camera → bottom-up multi-person 2D pose (OpenPose/HigherHRNet) → skeleton-based interaction features (reach, dwell) → heatmaps/BI dashboards.
- Tools/methods: PAFs/Associative Embedding for grouping, graph refinement of keypoints; lightweight models for edge NVRs.
- Assumptions/dependencies: privacy-by-design (no identity), signage for consent, robust performance in crowds and occlusions.
- Robotics and HRI — Safety and intent-aware collaboration
- Workflow: monocular camera on robot/cell → fast 2D pose + temporal smoothing → safety zone estimation around limbs → robot slowdown/stop; gesture commands for HRI.
- Tools/methods: bottom-up methods for wide FoV, temporal models (LSTM/transformer-based keypoint tracking), occlusion-aware refinement.
- Assumptions/dependencies: safety certification, worst-case latency bounds, domain adaptation to factory PPE and background clutter.
- Automotive — Driver/passenger monitoring and pedestrian intent cues
- Workflow: in-cabin camera → upper-body pose for drowsiness/distraction; external camera → pedestrian pose cues for intention estimation (looking, stepping).
- Tools/methods: top-down single-person in-cabin; bottom-up for street scenes; temporal tracking to reduce jitter.
- Assumptions/dependencies: regulatory approval, robust night/IR performance, occlusion (seat belts, steering wheel), system fusion with other sensors.
- Workplace Safety and Ergonomics — Posture risk scoring
- Workflow: monocular camera overlooking workstation → 2D/3D pose → ergonomic indices (e.g., RULA/REBA proxies) → alerts/coaching.
- Tools/methods: HRNet/SimpleBaseline + 3D lifting for joint angles; hierarchical bone representations for robust angle computation.
- Assumptions/dependencies: calibration to convert pixels to angles/distances, worker acceptance and privacy, illumination variability.
- Security/Surveillance — Behavior patterning without identity
- Workflow: pose-only analytics (fall detection, loitering, aggression cues) to minimize PII exposure.
- Tools/methods: bottom-up multi-person 2D pose + spatio-temporal graph features.
- Assumptions/dependencies: careful thresholding to avoid overreach and bias; need for clear policy and auditing.
- Education and Remote PE — Form feedback for exercises and dance
- Workflow: webcam → 2D pose → pose similarity scoring against exemplar → live feedback.
- Tools/methods: video pose tracking, multi-scale heatmap regression, compositional constraints for limbs.
- Assumptions/dependencies: instructional design; tolerance to small rooms and occlusion.
- Mobile Creator Tools — Posture correction, AR filters, video editing
- Workflow: on-device 2D keypoints → effects tied to limbs/body; automatic reframing and horizon leveling based on pose.
- Tools/methods: MobileNet-based hourglass, binarized CNNs, pose distillation for speed.
- Assumptions/dependencies: device compute and battery, permissioning and on-device privacy.
- Academic Research Infrastructure — Reproducible baselines and datasets
- Workflow: use the survey’s unified frameworks and released 3D pose data-processing toolbox to standardize preprocessing, training, and evaluation; organize benchmarks (COCO, MPII, Human3.6M, 3DPW).
- Tools/methods: code toolbox for 3D pose data, standard metrics, weak-supervision via 3D-to-2D projection.
- Assumptions/dependencies: license compliance, careful cross-dataset evaluation to avoid leakage.
- Policy and Governance — Procurement and evaluation criteria for pose systems
- Workflow: use benchmarks and metrics summarized in the survey to specify minimum performance, latency, and fairness requirements when procuring systems; mandate pose-only analytics to reduce PII where possible.
- Tools/methods: COCO/MPII/3DPW metrics; occlusion/crowd stress testing (CrowdPose).
- Assumptions/dependencies: alignment with local privacy laws, standardized reporting, independent validation.
Long-Term Applications
These rely on advances highlighted as challenges in the survey: in-the-wild 3D data scarcity, 2D–3D ambiguity, multi-person 3D in crowds, fine-grained full-body shape/texture, and robust, efficient edge deployment.
- E-commerce and Apparel — Accurate virtual try-on with body shape and cloth simulation
- Vision: reliable SMPL/SMPL-X parameter estimation under everyday clothing → physics-based garment simulation → size/fit recommendations and realistic try-on.
- Dependencies: in-the-wild 3D mesh ground truth, robust shape estimation through clothing, better body-shape priors; integration with cloth simulation engines.
- Consumer Health — Longitudinal musculoskeletal digital twins
- Vision: personalized 3D body model over time for injury prevention, sarcopenia monitoring, or scoliosis screening using home videos.
- Dependencies: calibrated or self-calibrated monocular pipelines, bias mitigation across ages and body types, clinical trials.
- Urban Mobility and AVs — Pedestrian intent prediction and proactive planning
- Vision: multi-person 3D pose in-the-wild + temporal forecasting for crossing intent, yielding decisions, and negotiation at intersections.
- Dependencies: robust multi-person 3D pose under occlusion/weather, uncertainty quantification, multi-sensor fusion with LiDAR/radar.
- Collaborative Robotics — Shared autonomy with human motion forecasting
- Vision: monocular 3D pose + short-horizon motion prediction for safe co-manipulation and handover planning.
- Dependencies: low-latency, certified pipelines; learned human motion priors transferable across tasks and users.
- Smart Workplaces — Adaptive ergonomic environments
- Vision: real-time 3D posture analysis drives dynamic desk/chair adjustments and exoskeleton assistance.
- Dependencies: precise joint-angle estimation under clothing, actuator integration, user acceptance and safety standards.
- Public Health and Safety — Non-contact crowd behavior monitoring
- Vision: city-scale pose-only analytics for fall detection in public spaces, mass event risk detection (stampede precursors) without facial identity.
- Dependencies: scalable bottom-up multi-person pipelines in dense crowds, privacy-preserving analytics, policy frameworks and oversight.
- Telepresence/Metaverse — Photorealistic tele-immersion from monocular cameras
- Vision: full-body mesh and texture recovery with fine hand/face detail and expression for immersive avatars.
- Dependencies: advances in 3D body+hand+face estimation (SMPL-X), neural rendering, temporal consistency, edge compute.
- Industrial Inspection and Training — Skill assessment from body mechanics
- Vision: derive competency metrics for complex tasks (e.g., surgical, assembly) from detailed 3D kinematics and attention to occluded limbs.
- Dependencies: domain-specific datasets, high-fidelity 3D under occlusion, validated scoring rubrics.
- Privacy-Preserving CV — On-device, encrypted pose analytics
- Vision: end-to-end systems that never leave raw pixels; only anonymized skeletons processed and stored, with federated or on-device learning.
- Dependencies: efficient binarized/lightweight models, secure enclaves, federated learning pipelines, regulatory standards.
- Education/Assessment — Automated PE and arts grading with fairness guarantees
- Vision: standardized scoring of movement quality (dance, martial arts) with fairness across demographics.
- Dependencies: diverse, balanced datasets; bias audits; interpretable models leveraging hierarchical bone vectors and structure-aware losses.
- Research Ecosystem — Unified 2D→3D training via weak/self-supervision at scale
- Vision: large-scale training using 2D in-the-wild data with 3D-to-2D reprojection, motion continuity, and multi-view consistency; reduced reliance on mocap labs.
- Dependencies: robust camera-model estimation, better priors, standardized pipelines, community-curated datasets.
- Regulation and Standards — Safety and performance certifications for pose systems
- Vision: sector-specific standards (e.g., ISO-like) for latency, accuracy under occlusion, fail-safe behavior, and fairness in pose-based products.
- Dependencies: consensus metrics and stress tests (occlusion, crowding, lighting), third-party certification infrastructure, periodic audits.
Notes on Feasibility and Cross-Cutting Dependencies
- Data and bias: Many surveyed methods train on COCO/MPII/Human3.6M/3DPW; domain gaps (culture, clothing, age, ability) can degrade performance and affect fairness.
- Occlusion/crowds: Top-down pipelines suffer from detector errors; bottom-up grouping (PAFs, Associative Embedding, CrowdPose-aware training) mitigates but still struggles in extreme densities.
- 3D ambiguity: Monocular 2D→3D lifting needs strong priors (SMPL), temporal/multi-view consistency, and 3D-to-2D projection constraints to resolve depth ambiguities.
- Compute/latency: Edge deployment benefits from binarized nets, MobileNet backbones, and distillation (FPD); safety-critical use requires deterministic latency bounds.
- Privacy/compliance: Prefer pose-only analytics; ensure consent, on-device processing, and regulatory alignment (GDPR/CCPA, sector regs).
- Tooling: The survey’s unified frameworks and released 3D pose data-processing toolbox can accelerate prototyping, benchmarking, and reproducibility across sectors.
Collections
Sign up for free to add this paper to one or more collections.