- The paper demonstrates a hybrid integration by combining DRL-based local planners with global planning algorithms via an intermediate waypoint strategy.
- It employs an actor-critic A3C framework enhanced with GRU to balance short-term reactivity and long-range planning in dynamic scenarios.
- Results show the framework outperformed conventional methods, reducing collisions and enabling more efficient paths in complex test environments.
Integration of Deep Reinforcement Learning into Robot Navigation Systems
Introduction
The paper "Arena-Rosnav: Towards Deployment of Deep-Reinforcement-Learning-Based Obstacle Avoidance into Conventional Autonomous Navigation Systems" (2104.03616) addresses the challenge of integrating Deep Reinforcement Learning (DRL) into industrial robot navigation systems. With the increasing complexity of environments where mobile robots are deployed, traditional navigation methods often fall short due to their conservative nature and inability to adapt to dynamic environments with moving obstacles like humans and machinery.
DRL offers a promising alternative due to its ability to learn complex behaviors from end-to-end. However, its integration into existing navigation systems has been limited by its short-term focus and lack of long-term memory. This work proposes a hybrid navigation framework that integrates DRL-based local planners with conventional global planners, leveraging the strengths of both approaches to enhance navigation capabilities in dynamic environments.
Methodology
The proposed navigation framework incorporates DRL-based local planners into the Robot Operating System (ROS), utilizing an intermediate way-point planner to bridge the gap between DRL and classic global planning algorithms such as RRT and A*. The intermediate planner dynamically selects way-points based on the robot's position and a spatial horizon, which adapts as the robot moves.
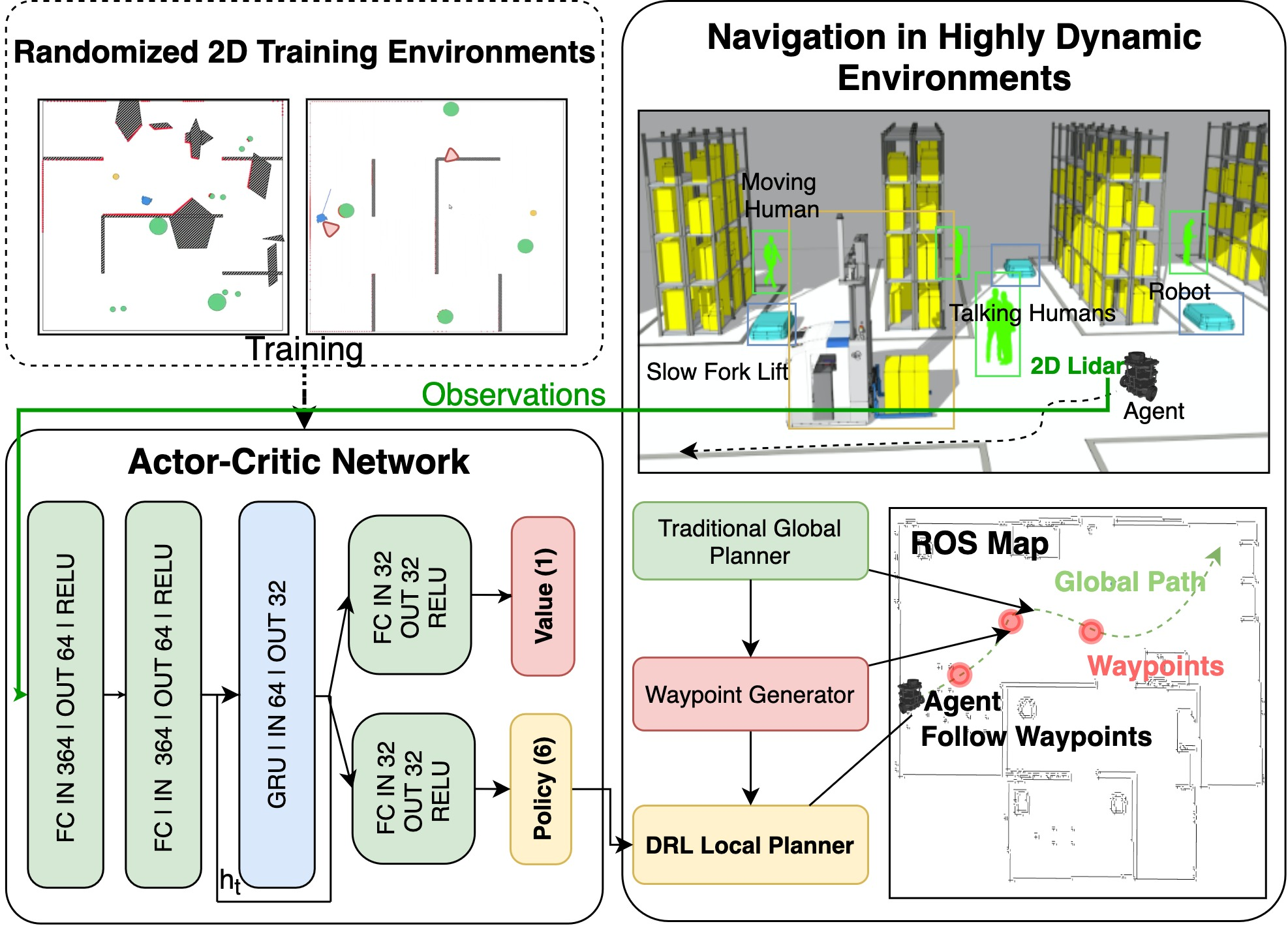
Figure 1: This work provides a platform to train and test learning-based obstacle avoidance approaches along with conventional global and local planners. This way, DRL-based obstacle avoidance approaches are made comparable against conventional approaches and feasible in industrial navigation systems.
The DRL-based local navigation is formulated as a Partially Observable Markov Decision Process (POMDP), solved using an actor-critic framework with A3C (Asynchronous Advantage Actor-Critic), enhanced by a GRU for incorporating past observations. The combination aims to balance short-term reactivity with long-range planning, a crucial capability for dynamic obstacle avoidance.
Results and Evaluation
The framework was evaluated against state-of-the-art planners including TEB, DWA, and MPC, as well as other DRL-based approaches like CADRL. Evaluations in both static environments and those with increasing numbers of dynamic obstacles demonstrated the superiority of the DRL-enhanced framework in terms of safety, efficiency, and robustness.
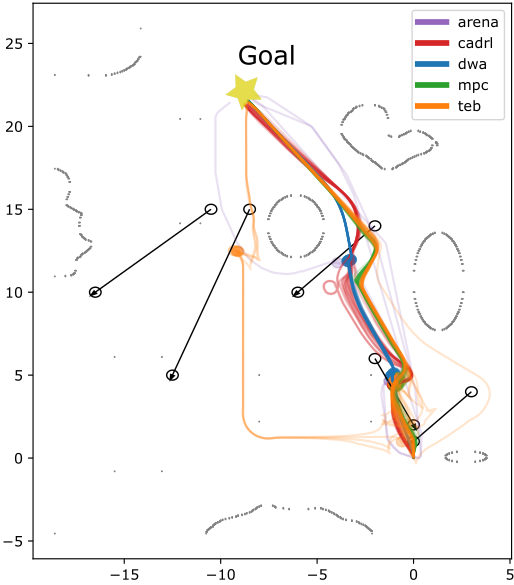
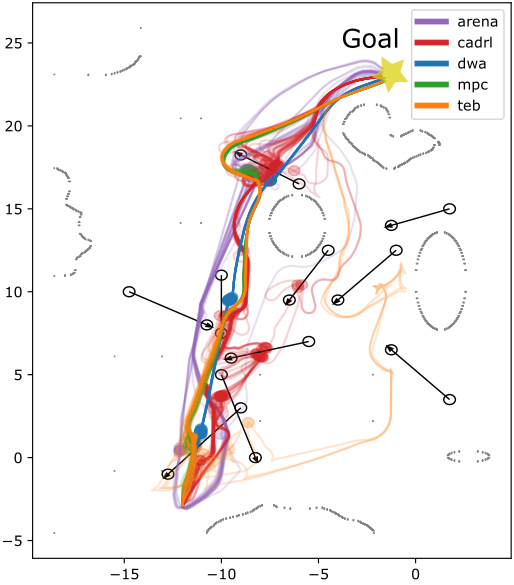
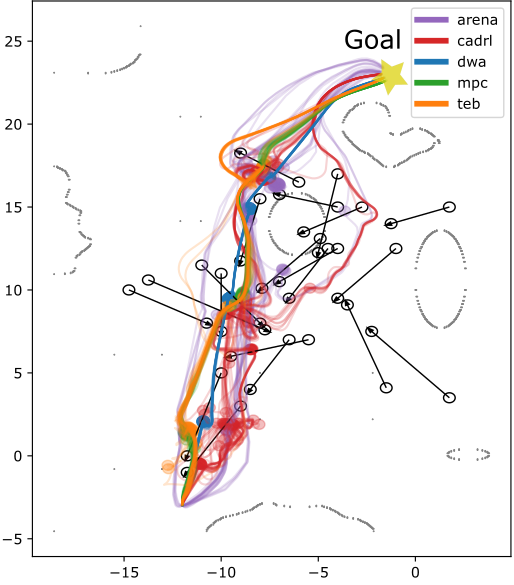
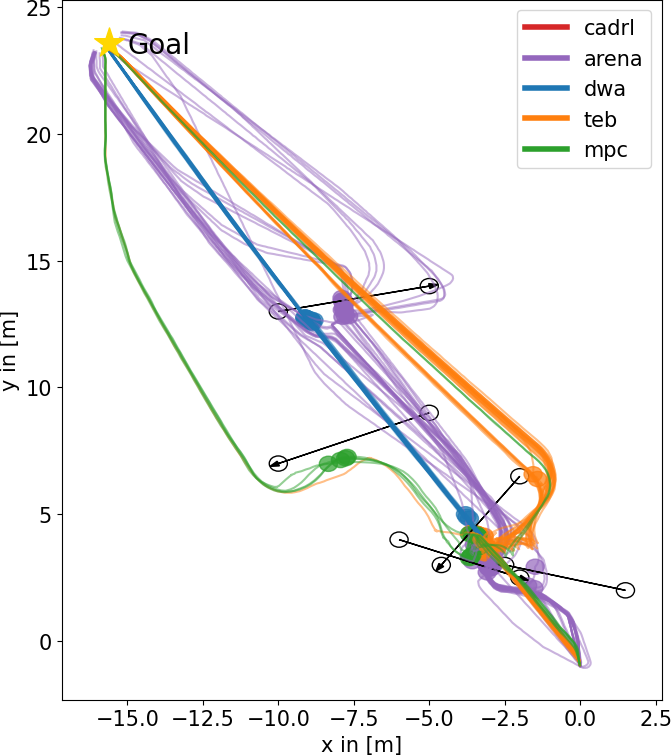
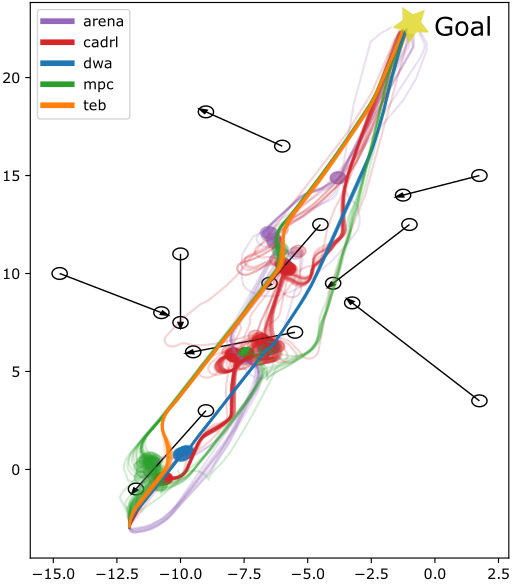
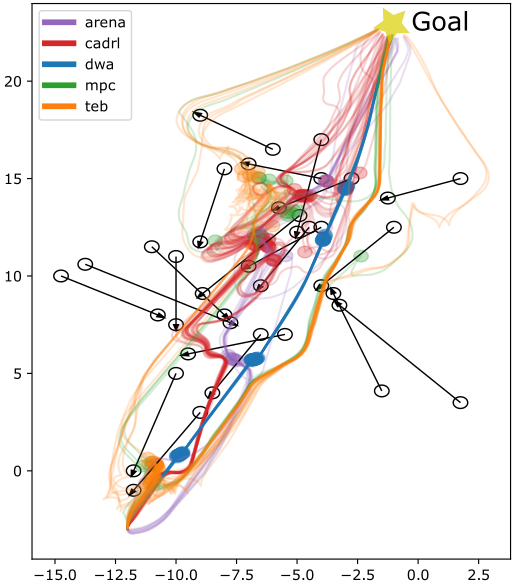
Figure 2: Trajectories of all planners on different test scenarios with obstacle velocity vobs=0.3 m/s. Upper row: office map, lower row: plain test area.
Results showed that the proposed DRL-based planner maintained high success rates even as obstacle complexity increased, with fewer collisions and more efficient paths compared to conventional planners. The integration of DRL with a flexible intermediate planner was key in adapting to unexpected changes, offering rapid replanning capabilities when obstacles altered or blocked paths.
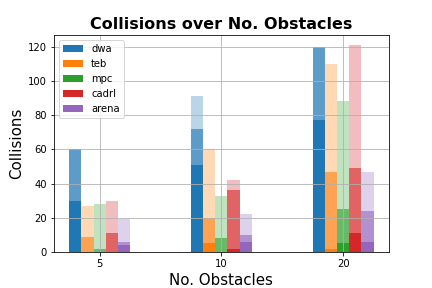

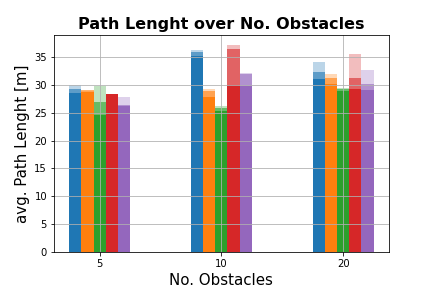
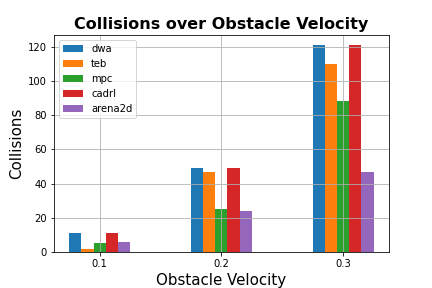
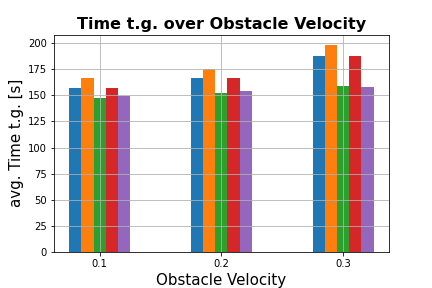
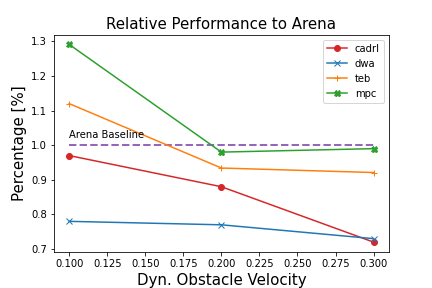
Figure 3: Results from test-runs on the office map. (a) Collisions over number of obstacles and vobs.
Conclusion
This work successfully demonstrates the potential for DRL to be integrated into industrial navigation systems when complemented with conventional planning strategies. By providing a flexible computation framework through ROS and robust evaluation in varied environments, this research paves the way for more adaptive and responsive navigation systems.
Future work should focus on incorporating semantic understanding of environments, and further improving the intermediate planner. The exploration of hybrid learning methods could enhance the system's adaptability to even more complex and dynamic environments, ultimately broadening the scope of applications where DRL can be effectively deployed.

