- The paper introduces DeepTMR, a novel neural network approach that reorders matrices to uncover latent structural patterns in relational data.
- It utilizes an autoencoder-like architecture to extract and map row and column features, outperforming traditional SVD and MDS techniques.
- Experimental results on synthetic and real-world datasets demonstrate enhanced interpretability and reliable reconstruction of complex data patterns.
Deep Two-Way Matrix Reordering for Relational Data Analysis
Introduction
The paper "Deep Two-Way Matrix Reordering for Relational Data Analysis" introduces DeepTMR, a novel approach in the domain of matrix reordering, aimed at finding meaningful structural patterns in relational data without prior assumptions about the matrix's structure. The authors propose leveraging a neural network model with an autoencoder-like architecture, uniquely designed to automate the simultaneous extraction of row and column features and subsequent matrix reordering.
Methodology
The DeepTMR model addresses traditional limitations by using a neural network to learn row and column permutations that result in structured and interpretable matrix forms. Unlike spectral methods such as SVD, which assume linear orthogonality and dependence on predefined features, DeepTMR employs a non-linear mapping via row and column encoder networks. These encoders process input data vectors, r(i) and c(j), derived from the matrix, to generate one-dimensional features. These features then pass through a decoder network, reconstructing the matrix entries by minimizing the mean squared error enhanced with L2 regularization.
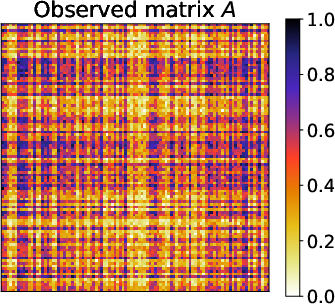

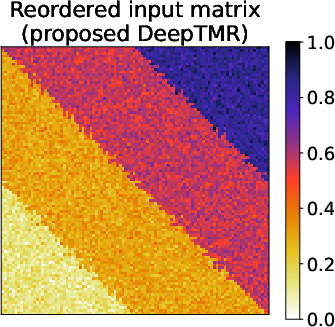
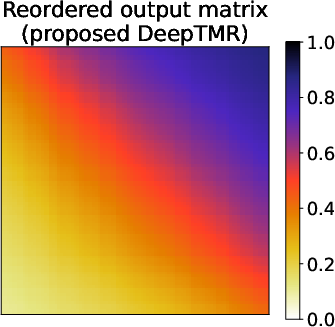
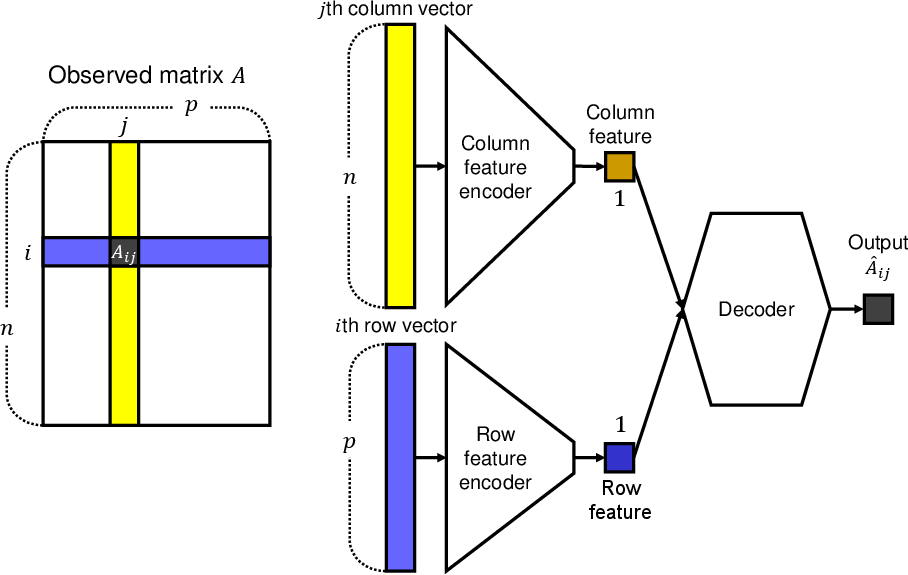
Figure 1: Matrix reordering problem. Given an observed matrix A, the proposed DeepTMR reorders the rows and columns to show interpretable structures, providing the denoised mean matrix.
Experimental Results
The efficacy of DeepTMR was validated using both synthetic datasets—Latent Block Model (LBM), Striped Pattern Model (SPM), and Gradation Block Model (GBM)—and real-world datasets including the divorce predictors dataset and metropolis traffic census dataset.
Synthetic Dataset Analysis
The tests on synthetic datasets demonstrated DeepTMR's capability to accurately reconstruct latent structures prominently under block and gradation patterns. The testing involved reordering errors contrasting DeepTMR's effectiveness over traditional approaches (SVD-based and MDS), which struggled to provide clear delineations without Gaussian noise obfuscation.
Real-World Dataset Analysis
- Divorce Predictors Dataset: Here, DeepTMR showcased its ability to delineate divorce risks quantitatively and visually differentiate between 'divorced' and 'married' groups. The reconstructed matrices revealed latent social patterns manifesting in questionnaire responses.
- Metropolis Traffic Census Dataset: DeepTMR adeptly reordered matrix entries to reflect significant commuting patterns. The latent block structures extracted by DeepTMR aligned with intuitive geographic commuting flows, proving the method's applicability for dense and complex relational datasets.
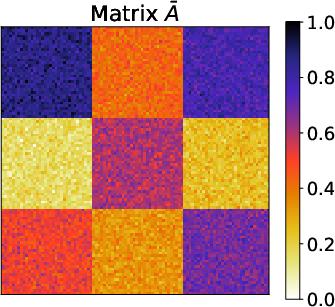
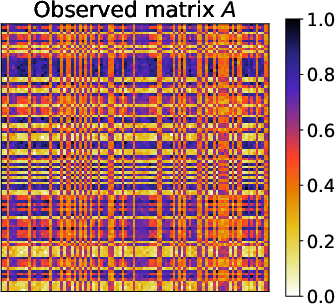
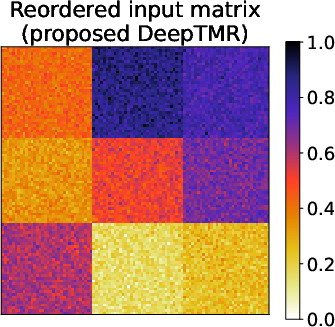
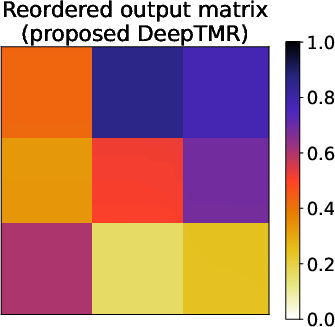
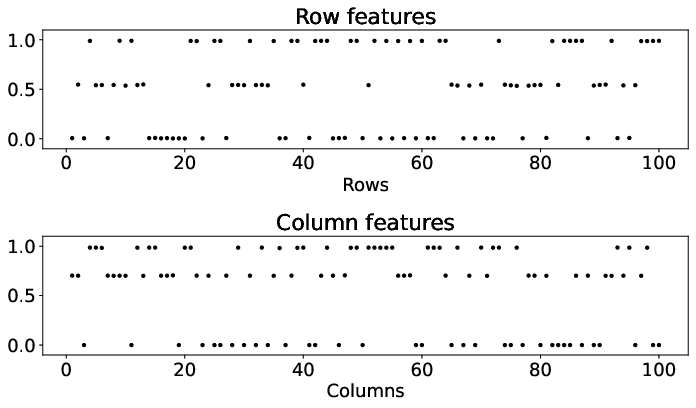

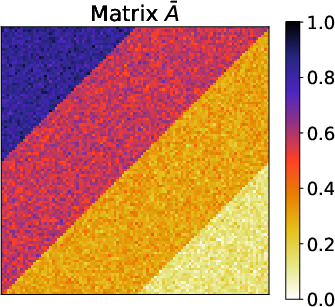
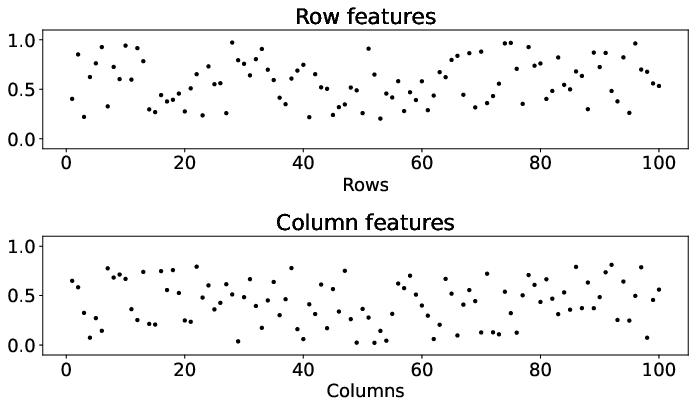
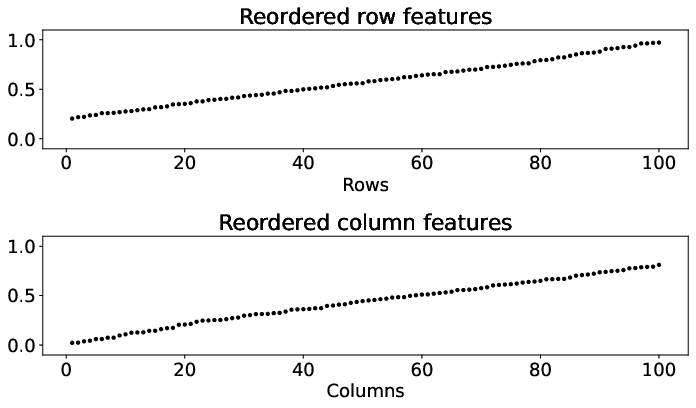
Figure 2: Results of the metropolis traffic census dataset for matrices A, A, and $\underline{\hat{A}$, demonstrating the clarity of commuting patterns in reordered matrix forms.
Comparison and Discussion
DeepTMR consistently outperformed established spectral and dimension-reduction techniques by allowing automatic feature extraction without predefined assumptions. SVD and MDS methods, while effective under certain structured conditions, were inflexible in scenarios lacking prior structure knowledge.
However, DeepTMR's dependency on neural network initializations and configurations poses a potential limitation, indicating a need for robust adaptive hyperparameter selection strategies in future implementations. Moreover, extending DeepTMR to accommodate dynamically sized inputs could enhance its applicability to evolving datasets, particularly useful for time-series analysis.
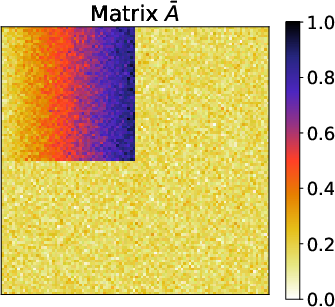
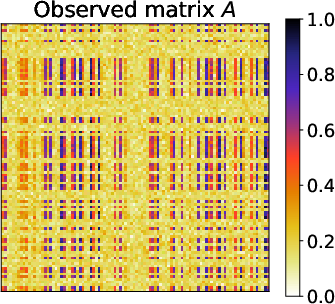
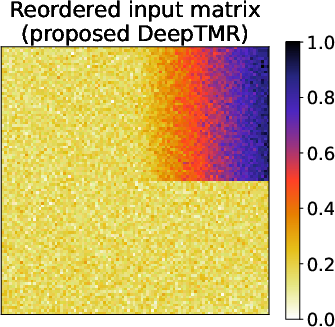
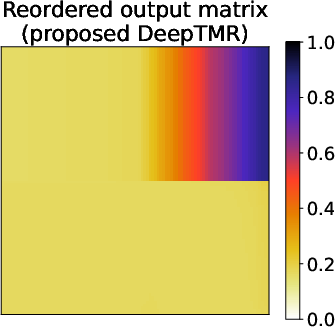
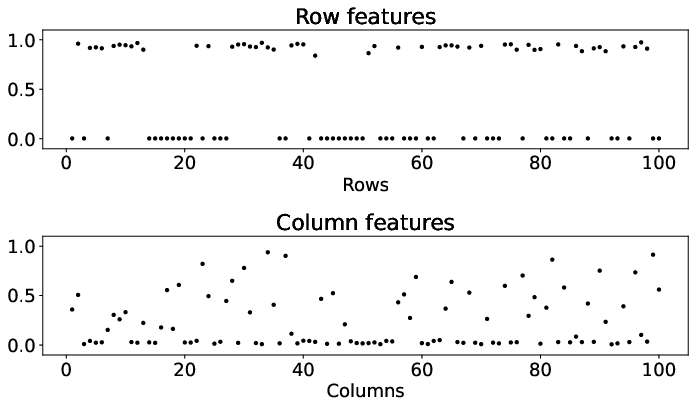
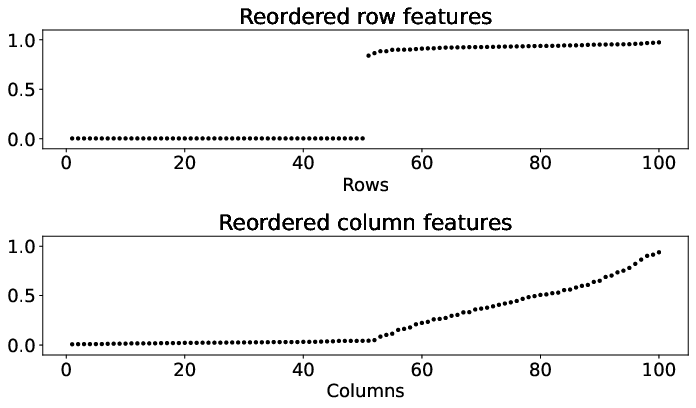
Figure 3: Results of the gradation block model for matrices Aˉ, A, A, $\underline{\hat{A}$, highlighting the method's robust capture of underlying patterns.
Conclusion
The DeepTMR represents a significant advancement in matrix reordering, notably enhancing interpretability of complex relational data without prior assumptions. By employing neural networks to perform non-linear mappings and automatic feature extractions, DeepTMR aligns with modern data analysis demands. Future research will need to focus on optimizing model robustness and computational efficiency, particularly for larger-scale data matrices with evolving structures.