- The paper demonstrates that attention heads in BERT and RoBERTa partially capture constituency grammar using syntactic distance measures.
- The study employs pre- and post-fine-tuning analysis on SMS and NLI tasks to assess changes in grammar induction performance.
- The findings reveal that certain layers and attention heads correlate with higher NLU accuracy, highlighting nuanced roles in syntactic learning.
Constituency Grammar in BERT and RoBERTa Attention Heads
This paper investigates whether attention heads in the BERT and RoBERTa models capture constituency grammar. It uses the syntactic distance method to analyze the grammar inducing ability of individual attention heads before and after fine-tuning on various tasks. The research focuses on understanding the internal representations that contribute to natural language understanding (NLU) capabilities and explores how these representations change with task-specific training.
Methodology
Analysis of Attention Mechanisms
The study leverages the transformer architecture intrinsic to BERT and RoBERTa to assess constituency parsing abilities. Each attention head within these layers processes input tokens through self-attention, transforming them into query, key, and value vectors, which are then combined via weighted summation to produce token representations. The paper uses this mechanism to extract implicit constituency structures from attention distributions, invoking a syntactic distance measure borrowed from prior research [kim2020pretrained].
Syntactic Distance and Constituency Trees
To derive constituency trees from attention layers, the study computes syntactic distances between sequential tokens, incorporating a skewness bias to reflect English syntax patterns more accurately. This distance facilitates the recursive generation of trees, revealing how well each head captures grammar [shen-etal-2018-straight]. This parsing ability is benchmarked against baseline methods, including left- and right-branching trees.
Results and Analysis
Pre-fine-tuning Grammar Induction
The preliminary findings suggest that not all attention heads contribute equally to constituency grammar. In BERT, higher layers generally outperform lower layers in inducing constituency structure, whereas RoBERTa shows stronger performance in its middle layers (Figure 1).
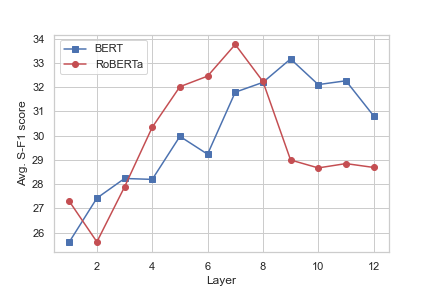
Figure 1: Average constituency parsing S-F1 score of each layer in BERT and RoBERTa.
The evaluation against baselines reveals that both BERT and RoBERTa exceed right-branching structures but only moderately improve over left-branching approaches, suggesting incomplete grammar learning.
Impact of Fine-tuning
The study extends this investigation by fine-tuning the models on two categories of NLU tasks: Sentence Meaning Similarity (SMS) and Natural Language Inference (NLI). The results demonstrate that NLI fine-tuning enhances the CGI ability in higher layers, whereas SMS tasks slightly reduce it, as depicted in Figure 2 and Figure 3.
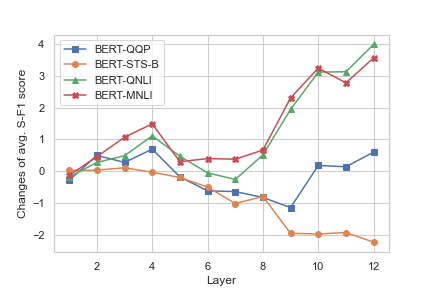
Figure 2: Changes of average S-F1 score of each layer in BERT after fine-tuning.
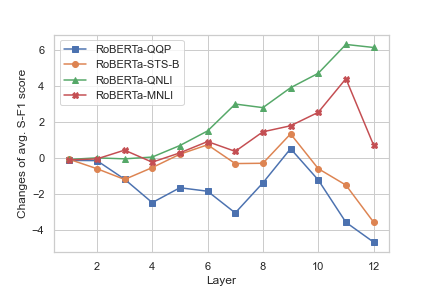
Figure 3: Changes of average S-F1 score of each layer in RoBERTa after fine-tuning.
Despite task-related enhancements, neither model conclusively learns full constituency grammar across all phrase types, though specific phrase types like NP, PP, and ADJP exhibit stronger recognition post-fine-tuning.
Relation to Natural Language Understanding
A critical part of the study measures the relation between CGI capabilities and NLU performance on QQP and MNLI tasks. By masking attention heads based on CGI capacity, the paper identifies distinct impacts on task accuracy. In BERT, heads with significant CGI ability align with higher NLU performance, while RoBERTa displays weaker correlations, particularly in SMS contexts (Figure 4 and Figure 5).
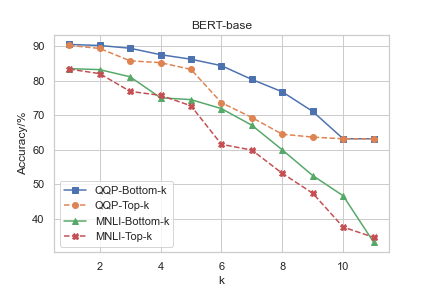
Figure 4: QQP dev and MNLI dev-matched accuracy after masking the top-k/bottom-k attention heads in each layer of BERT-QQP and BERT-MNLI.
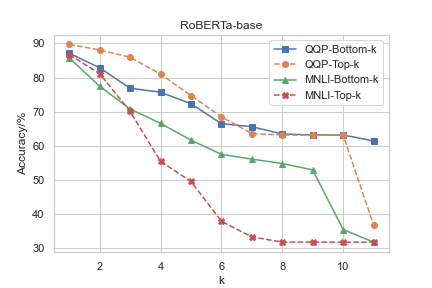
Figure 5: QQP dev and MNLI dev-matched accuracy after masking the top-k/bottom-k attention heads in each layer of RoBERTa-QQP and RoBERTa-MNLI.
Implications and Future Directions
The research underscores the nuanced role that attention heads play in learning complex grammatical structures. The findings imply that while transformer-based models can partially learn syntactic structures, they may not inherently require exhaustive syntactic knowledge for achieving state-of-the-art NLU performance. This opens avenues for further research to explore alternative architectures or methods for more comprehensive grammar integration.
Future work could explore optimizing attention heads for specific tasks or even creating hybrid models that integrate explicit syntactic knowledge more effectively. Additionally, understanding why certain tasks disproportionately affect CGI ability can guide more targeted model training strategies.
Conclusion
This paper provides insights into the extent and manner by which BERT and RoBERTa models capture constituency grammar through their attention heads. It evaluates their performance against syntactic baselines and explores how fine-tuning influences grammar induction and NLU capabilities. While attention heads manifest some linguistic knowledge, the study points to potential limitations in how grammar is encoded and highlights areas for continued investigation.

